
이번에는 13번째 강의를 할 차례가 되었습니다. 이번 시간에는 어텐션 Attention에 대해서 다루게 될건데 "집중하세요" pay attention 같은 엉터리 조크는 하지 않을게요. 지난 번 중간 고사 이전에 순환 신경망에 대해서 다뤘습니다.
한번 다시 떠올려보면 순환 신경망은 다른 작업을 가능하도록 만든 다양한 벡터 시퀀스들을 처리 할수 있는 유용한 구조인걸 배웠습니다.
우선 순전파 신경망 feed forwad neural network에서 시작해서 순환 신경망 recurrent neural network로 고치면서 풀수 있는 다양한 문제들을 살펴보았는데, 예시로 기계 번역에 대해서 봤었습니다. 이 기계번역의 경우 한 시퀀스를 다른 시퀀스로 바꾸는 문제였어요. 다른 예시로는 이미지 캡셔닝이 있었는데, 입력 이미지가 주어질때 그에 대한 단어들의 시퀀스를 예측하는 문제였습니다.
이번 시간에는 지난 시간 배운 순환 시긴경망에 대해서 하나하나 짚어보면서 어탠션에 대해서 다뤄보겠습니다.

일단 순환 신경망에서 시퀀스 투 시퀀스 문제로 돌아가서 다시 살펴봅시다. 이 과정에서는 입력 시퀀스들 그러니까 x1에서 xt까지 받는데, 이걸 가지고 y1에서 yt까지의 출력 시퀀스를 만들게 됩니다. 여기서 x들은 영어 문장의 단어 하나하나라 볼수 있겠고, y들은 스패인어 문장에서 그에 해당하는 단어들이라고 할수 있겠습니다.
그래서 우리가 하고자 하는건 한 언어로 된 문장의 단어들을 다른 언어의 문장으로 변환을 시키는것이 되겠습니다. 다른 언어들은 서로 다른 개념들을 사용하다보니 두 시퀀스의 길이는 다를수 있습니다. 그래서 입력 시퀀스 x의 길이를 t, 출력 시퀀스 y의 길이를 t'으로 나타낼게요.
지난 강의때 순환 신경망 아키텍처로 시퀀스 투 시퀀스 모델에 대해서 다뤄보면서 이 아키텍처는 번역 문제에서 사용할수 있다고 했었습니다. 이게 동작하는 과정을 다시 떠올려보면 인코더라고 부르는 순환 신경망이 있었는데, 인코더는 벡터 x들을 받아서 은닉 상태들의 시퀀스 h1 ~ ht를 만들어 냅니다.
매 타임 스탭마다 순환 신경망에 대한 수식/함수 fw로 이전의 은닉 상태와 현재 입력 벡터 xi를 받아가지고 현재 은닉 상태를 만들어 냈습니다. 이 과정을 순환 신경망이 전체 입력 벡터 시퀀스에다가 적용시킬수가 있었습니다.
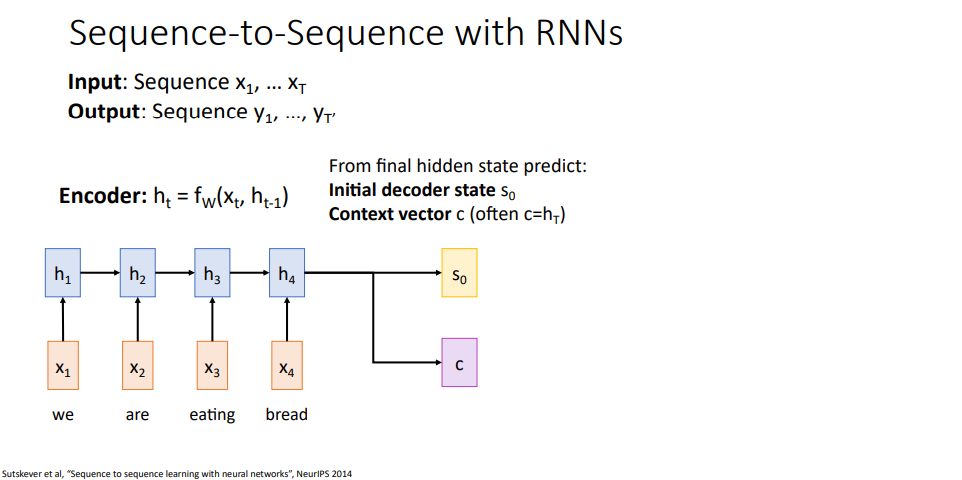
여길 보면 어떻게 동작하는지 조금 더 자세한 사항내용들을 볼수 있겠는데, 입력 벡터를 처리하고 나서 전체 입력 시퀀스 내용들을 두 벡터로 정리하고자 한다고 합시다. 디코더, 출력 문장을 만들어냄,라고 부르는 다른 순환 신경망을 쓸거다보니 입력 문장을 두 백터로 정리할수 있어야 해요.
이들 중 하나는 디코더의 초기 은닉 상태 initial hidden state로 이 그림 상에서는 s0로 표기되고 있습니다. 그리고 컨텍스트 벡터 c를 계산해야해요. 이 벡터 c는 디코더의 매 타임스탭마다 흘러/통과하겠습니다. 가장 일반적으로 구현시 컨텍스트 벡터는 최종 은닉 상태를 사용하고, 초기 은닉 상태를 가장 흔하게 선정하는 방법은 순전파 계층이나 완전연결 계층 같은 것으로 예측한 결과를 사용합니다.
-> 인코더는 디코더에서 사용할 벡터 2개를 만들어낸다. 초기 (디코더) 은닉 상태 벡터와 컨텍스트 벡터
-> 컨텍스트 벡터는 디코더의 모든 타임 스탭에서 사용되며, 인코더의 최종 은닉 상태가 주로 사용된다.
-> 초기 (디코더) 은닉 상태는 인코더의 최종 은닉 상태로부터 예측한 결과를 사용한다.

이제 디코더를 다뤄보면 디코더가 하는일은 어느 입력 시작 토큰을 받아서 출력 시퀀스를 만들어 나가게 됩니다. 첫 타임 스탭 디코더의 출력을 구하기 위해서는 초기 은닉 상태 s0과 컨텍스트 벡터 c 그리고 시작 토큰 y0을 입력받아서 출력 문장의 첫번째 단어가 만들어 집니다.

시간에 따라 계속 반복할건데, 디코더의 두번째 타임 스텝에서는 이전 타임 스탭의 은닉 상태 s1와 문장의 첫번째 단어 "estamos" 그리고 컨텍스트 벡터 c를 받아서 동작하고,

여러 타임스탭을 진행하면서 입력 문장을 번역해서 "we are eating bread"가 스패인 번역기를 통해서 바뀌어지겠다. 이 구조에서 살펴봐야할 부분은 분홍색 상자의 컨텍스트 백터를 사용하고 있다는 점인데, 이 벡터는 인코딩 시퀀스와 디코딩 시퀀스 사이에서 정보를 전달하기 위한 목적으로 사용한다.
이 컨텍스트 벡터는 디코더가 문장을 만들어내는데 필요한 모든 정보를 요약한 것이며, 이 컨택스트 백터는 디코더의 모든 타임 스탭에서 사용된다. 이 아키텍처는 꽤 합리적이기는 하지만 문제점을 가지고 있다.

이렇게 만든 아키텍처는 짧은 문장을 다루는 경우에 잘 동작할거고, 슬라이드의 예시와 같이 약간 긴 경우에도 잘 동작할것이다. 하지만 실제로 아주 긴 문장을 다루는 sequence to sequence 아키텍처를 사용한다고 할때, 짧은 문장을 번역하는게 아니라 책의 전체 문단을 번역하고자 하는 경우 문제가 발생할 수 있다.
여기서 발생하는 문제는 입력 문장, 입력 텍스트에대한 전체 정보가 하나의 컨텍스트 벡터 c로 병목화/압축해서 나타내려하기 때문인데, 벡터 하나를 가지고 짧은 문장 전체를 표현하는건 괜찬겠지만 텍스트북의 문단 전체를 하나의 컨텍스트 벡터 c로 요약하는건 어렵기 때문이다.

이 문제를 극복하기위해서 모든 정보를 하나의 벡터 c에다가 다 집적? 요약시키기지 않는 매커니즘을 찾고자했으며, 간단한 해결책으로 하나의 컨텍스트 벡터 c로 정리하는게 아니라
디코더의 모든 타임 스탭마다 새로운 컨텍스트 백터를 계산해 내는데, 이 새 컨텍스트 벡터는 디코더의 모든 타임 스탭에서 입력 시퀀스의 어느 부분에 집중을 할 건지 선택할수 있게 만들어 준다.

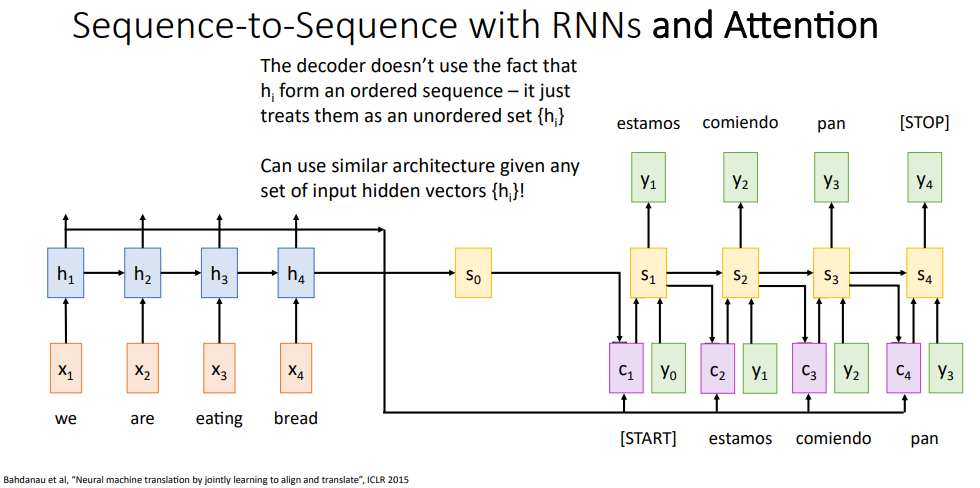
이 좋은 방법을 정리하였고, 어텐션 attention이라 부른다. 이 슬라이드를 보면 여전히 시퀀스 투 시퀀스 순환 신경망을 사용하고 있으며, 입력 시퀀스를 인코딩해서 은닉 상태 시퀀스를 만들어내는 인코더를 가지고 있고, 매 시간마다 출력을 만들어내는 디코더를 사용할건데 차이점이라면 이 신경망에다가 어텐션 매커니즘을 추가시키겠다.
어탠션 매커니즘은 디코더의 매 타임 스탭마다 새로운 컨텍스트 백터를 계산해내는데, 어떻게 되는지보자면 인코더는 그대로라 입력 시퀀스에 대한 은닉 상태 시퀀스들을 만들고, 디코더에서 사용할 초기 은닉 상태을 추정한다.

하지만 이전에 본 시퀀스 투 시퀀스 아키택처와 차이점을 볼수 있는데, 우측 상단에 배정 함수 alignment function (의미를 생각하면 위치를 배치한다?는 의미에서 배치가 맞을것같긴한데 이전에 본 배치와 햇갈리지 않게 그냥 위치를 배정한다는 의미에서 배정 함수라 하였다.)를 작성하였다. 이 배정 함수는 매개변수를 받는 완전 연결 신경망으로 작은 완전 연결 신경망이라 생각하면 되겠다.
그래서 이 신경망은 두 벡터를 입력으로 받는데, 하나는 디코더의 현재 은닉 상태와, 다른 하나는 인코더의 은닉 상태들 중 하나를 받는다. 그러면 이 배정 함수는 디코더의 현재 은닉 상태가 주어졌을때 인코더의 각 은닉 상태들 중에서 얼마나 주의를 기울이냐, 다시말하면 디코더의 현재 은닉 상태가 인코더의 각 은닉 상태들 중에서 얼마나 가까운가 집중하는가에 대한 스코어를 출력시키게 된다.
그래서 디코더의 매 타임스탭마다 새 컨텍스트 백터를 만들기 위해서 이 정보들을 사용할건데, 구체적으로 보자면 디코더의 맨 첫번째 타임 스탭에서 디코더 초기 은닉 상태 s0를 가지고 있겠다. 여기서 f_att 함수를 사용하여 s0와 h1이 주어질때 다른 값들이랑 비교하기위해서 일단 배정 함수 스코어로 e_11을 구하였다.
이 배정함수 스코어는 은닉 상태 h1가 출력 은닉 상태 s0 뒤에 어떤 단어가 올지 예측하는데 얼마나 필요하는가를 나타내며, 스칼라값 e_11이 출력으로 나오게 된다. 그래서 스칼라값인 e_12는 디코더의 첫번째 은닉 상태를 가지고 단어를 예측할때 h2를 얼마나 사용되는가로 볼수 있겠다.
그리고 이 배정 함수를 디코더의 한 은닉 상태가 주어질때 인코더의 모든 은닉상태에다가 돌려서, 인코더의 모든 은닉 상태에 대한 배정점수를 얻을수 있었다. 하지만 이 배정 스코어들은 순전파 신경망 f_att로부터 얻은것이다보니 실수값이고,

다은 단계에서 할일은 소프트 맥스 연산을 수행해서 이 배정 점수들을 확률 분포로 만들어 주겠다. 이 솦프트맥스 함수는 이전에 이미지 분류때 봤던것과 동일한 것으로 스코어들로 이뤄진 벡터를 입력으로 받아서 확률 분포를 출력하게되는데, 가장 큰 스코어는 가장 큰 확률값이 될것이고 각 출력된 값들은 0에서 1사이의 실수 값이 되며 이들을 모두 합하면 1이 된다.
그래서 우리는 디코더의 첫번쨰 은닉 상태에 대한 확률 분포를 예측했고, 이 확률 분포는 인코더의 각 은닉 상태들 중에서 얼마나 가중을 줄지를 알려주다보니 이들을 어탠션 가중치 attention weights라고 부른다.

다음에 할일은 얼핏보면 어려워보이지만, 은닉 상태 각각에대한 가중합을 가져와서 사용하겠다. 이들을 예측된 확률 스코어 만큼 가중을 줘서 더하여, 디코더의 첫번째 타임스탭에서 사용할 컨텍스트벡터 c1을 만든다.
이게 의미하는건 입력 시퀀스에대한 (인코더의)각 은닉 상태들을 얼마나 가중치를줘서 반영시킬지를 예측해서 디코더의 모든 타임스탭마다 동적으로 가중치를 변화시키면서 디코더의 매 타임 스탭마다 다른 컨텍스트 백터를 구할수가 있겠다.

그러면 이제 디코더의 첫 타임 스탭을 동작시킬수가 있겠고, 이 디코더 신경망은 방금 막 계산한 컨텍스트 벡터와 (이 슬라이드에는 빠트렸지만) <start> 토큰을 입력으로 받아서 문장에서 첫번째 예측되는 단어를 출력한다.

정리를하자면 문장의 각 단어들을 생성시키고자 할때, 출력 문장의 각 단어는 입력 문장의 하나 혹은 여러개의 단어에 대응된다. 그래서 디코더 신경망이 입력의 한 부분에 집중할수 있도록 해주는 컨텍스트 백터를 매 타임 스탭마다 동적으로 만들어낸게 되겠다.
그래서 여기서 보는 예시는 "we are eating bread"라고 하는 특정한 문장을 번역하는것으로 첫번째 단어 "estamos"는 스페인어로 "we are doing somthing"이란 뜻을 가지고 있다. 영어문장에서 첫, 두 단어에 가중을 두고 나머지 두 단어에는 가중치를 적게 준다면, 디코더 신경망이 단어들을 만드는데 입력 시퀀스에서 중요한 부분에 집중할수 있게 된다.
다른 중요한 점으로 이 모든 연산들은 미분 가능한것들이며, 우리가 신경망한태 디코더의 매 타임스탭마다 어디에 집중하라고 알려주기보다는 신경망이 스스로 어디를 집중해서 보도록 만들었다.
지금 보고 있는 계산 그래프의 모든 연산들은 미분가능하다보니 우리가 따로 지시하거나 신경망에게 어딜 보라고 할 필요없이, 이런 큰 연산을 하나의 계산그래프를 만들고 신경망의 모든 파츠들을 역전파를 통해서 최적화 시키면 되겠다.

다음 타임 스탭에서 이 과정을 반복해서, 디코더의 새 은닉상태 s1을 가져와서 이 은닉상태와 입력 시퀀스의 각 은닉 상태를 비교해서 새로운 배정 스코어 e21, e22, ... 등 시퀀스를 만들어낸다.
그리고 소프트맥스를 적용해서 입력 시퀀스에 대한 확률 분포들을 구해내고, 이 확률 분포는 출력 시퀀스에서 두 번째 단어를 만들어낼때 입력 시퀀스의 어떤 단어에 집중을 할것인가를 알려주며, 이 추정 확률로 입력 시퀀스의 은닉 상태에대해 가중 합으로 새 컨텍스트백터를 만들어내겠다.

이전의 과정을 다시 반복해서, 두번쨰 컨택스트 벡터와 첫 번째 단어, 이전 은닉 상태로 두 두번째 은닉 상태를 계산한뒤 두번쨰 단어를 생성해내겠다.

정리하자면 무언가를 먹다는 걸 의미하는 두번째 단어 "comiendo"가 생성된 것은 모델이 "eating"의 타임 스탭에 가중치를더 줘서 집중했으며, "we"나 "bread"같은 단어는 생성시키는게 적정하지 않은것으로 보고 무시했다고 할수 있겠습니다.
다시말하지만 이 모델은 미분가능해서 학습시킨것으로 우리가 모델에거 어떤 단어, 부분이 집중하라고 알려줬기보다는 모델이 출력 시퀀스를 생성할때 어떤 부분을 집중할지 학습한 것입니다.

그래서 이제 여러 타임 스탭으로 풀어나가서 이와 같이 어탠션으로 학습한 시퀀스 투 시퀀스 예시를 볼수 있겠습니다. 이 방법을 통해서 바닐라 시퀀스 투 시퀀스 모델이 가지고 있던 문제를 극복할수가 있었습니다.
왜냐면 이건 입력 시퀀스에 대한 전체 정보를 하나의 단일 벡터에 넣어서, 그 한 벡터를가지고 디코더의 모든 타임스탭에다가 반영시킨것이아니라 디코더에게 각 타임스탭마다 새로운 컨텍스트백터를 생성해서 줬거든요. 그래서 다시 정리하자면 우리가 아주 엄청 엄청 긴 시퀀스를 다루더라도 모델이 디코더의 각 출력때마다 입력 시퀀스에서 주의를 집중할 부분을 이동/바꿀수있게 되었습니다.

우리가 지금까지 기본적으로한것은 순환 신경망 모델인 시퀀스 투 시퀀스를 학습시켰고, 이 모델은 영어로된 단어들의 시퀀스를 입력받아 프랑스어 단어 시퀀스를 출력시킨다고 합시다. 그림에서 뒤집혓을수도 있긴한대 햇갈리니 넘어가겠습니다.
하지만 결국에 하는 일은 영어 단어들과 프랑스 단어들/문장을 번역하는 작업을 할 것인데, 이 어텐션을 이용한 시퀀스 투 시퀀스 모델을 학습시킨것이고, 디코더의 타임 스탭마다 출력 시퀀스를 만드는 과정에서 입력 시퀀스의 어떤 단어에 주의를 기울일것인지를 정리하는 입력 시퀀스의 모든 단어들의 확률 백터를 만들어 냅니다.
그래서 우린 여기서 어탠션 가중치를 이 모델이 번역 작업을 할 때 어떤 결정을 내렸는가, 어떻게 결정을 내렸는가로 이해/해석 할 수가 있어요.
위 슬라이드를 보면 위에 영어 문장으로 "the agreement on the european economic area was signed in august 1992"가 있고, 그 아래에 프랑스어로 동일한 의미를 나타내는 문장이 있어요.

여기서 재미있는 부분은 이 다이어그램은 출력의 모든 타임스탭에서 어탠션 가중치가 어떤지를, 즉 모델이 어떤 선택을 했는지를 보여주고 있어요. 그래서 이 그림으로 해석할수 있는 구조 부분들이 많은데, 첫번째로 볼수 있는 건 왼쪽 위 코너에서 어텐션 가중치의 대각 패턴을 볼수가 있어요. 이 패턴의 의미는 "the"라는 단어가 프랑스어 토큰 L'를 생성하는대서 가장 집중을 했다는 의미입니다.
그 다음 영단어 "agreement"는 프랑스 단어 "accord"를 만들때 가장 집중되었다는 것이고, 그래서 출력 시퀀스의 처음에서 네 번째 단어를 생성하는데까지 일대일 대응되었다고 이해/해석할수 있겠습니다. 그리고 이 대응관계는 모델이 스스로 찾아내는것이지 우리가 모델에게 문장의 어떤 부분이 배정/매칭되는지 알려준게 아니에요.

하지만 여기서 가장 놀라운 부분은 프랑스어로 "zone economique europeenne", 영어로는 "european economic area"인데, 여기서 세 단어는 같은 의미이지만 다른 순서로 되어있어요. 프랑스어 "zone"은 영어로 "area"이고, 영어로 "economic"은 프랑스어로 "economique", "european"은 "europeenne"와 대응되는 구조인것을 볼수 있고, 이 모델은 이 세 단어의 순서를 뒤집어서 대응시키고 있어요.
이 어텐션 매커니즘에서 좋은 점은 다른 신경망 아키텍처와는 달리 이 모델이 어떻게 결정을 내렸는지에 무엇을 골랏고 무엇을 안 골랐는지에 대해서 어느정도 해석할수있는 점이되겠습니다.
그래서 이 어텐션 매커니즘으로 시퀀스를 생성했고, 단어 생성시 매 타임스탭마다 입력 시퀀스의 서로 다른 부분들을 집중해서 보았습니다. 하지만 이 어텐션 메카니즘의 수학적인 구조에 대해서 알아차릴수 있는점은 입력이 시퀀스라는 사실을 신경쓰지 만들었다는 점입니다.
이러한 기계 번역의 작업에서 입력을 시퀀스로 받고 출력도 시퀀스가 되었지만, 어탠션 매커니즘의 목표는 시퀀스인 입력 벡터들을 사용하는것이 아니라, 시퀀스가 아니더라도 다른 종류의 데이터에도 집중할수 있도록 어텐션 메카니즘이 만들어졌어요.
**다음에는 이미지 캡셔닝과 어탠션에 대하여...
'번역 > 컴퓨터비전딥러닝' 카테고리의 다른 글
| 딥러닝비전 13. 어텐션 - 3. 어텐션 레이어 (0) | 2021.03.19 |
|---|---|
| 딥러닝비전 13. 어텐션 - 2. RNN과 어텐션을 이용한 이미지 캡셔닝 (0) | 2021.03.18 |
| 딥러닝비전 12. 순환 신경망 - 6. LSTM (0) | 2021.03.15 |
| 딥러닝비전 12. 순환 신경망 - 5. 이미지 캡셔닝과 Vanilla RNN Gradient Flow (2) | 2021.03.15 |
| 딥러닝비전 12. 순환 신경망 - 4. 텍스트 생성과 은닉 유닛 해석 (0) | 2021.03.13 |