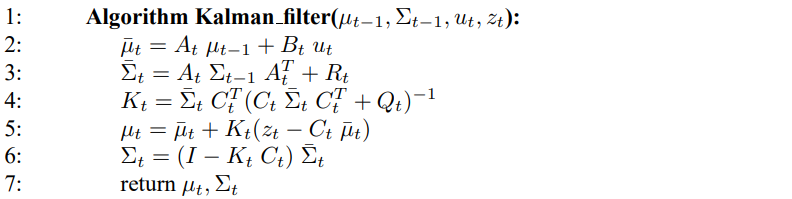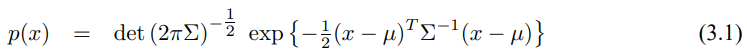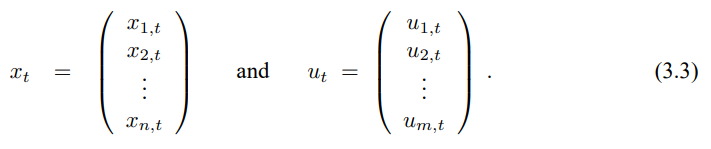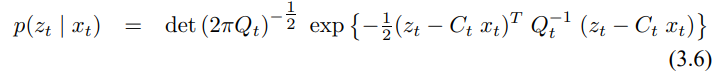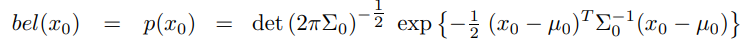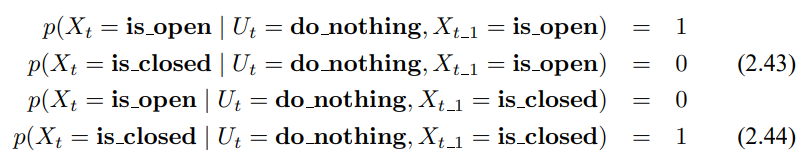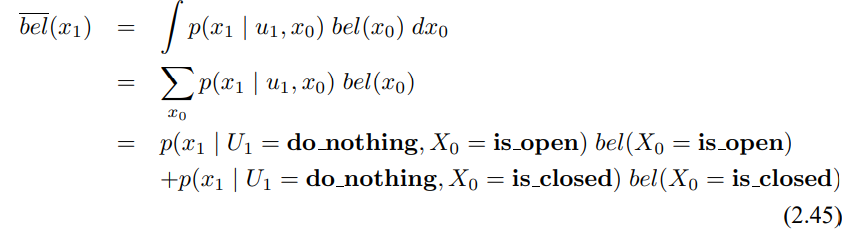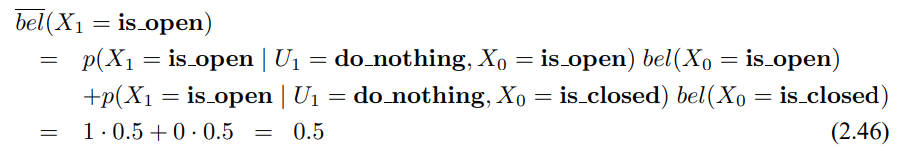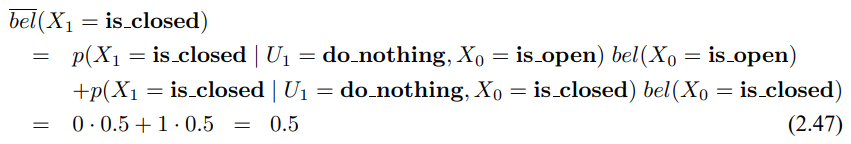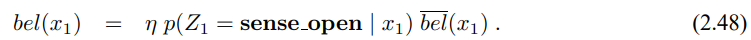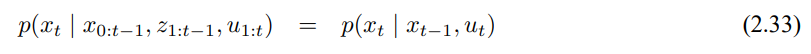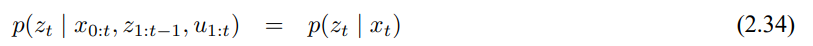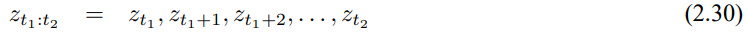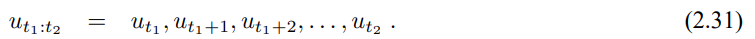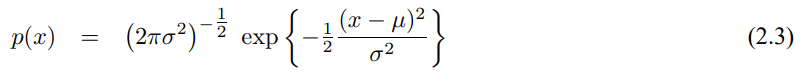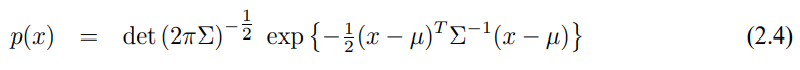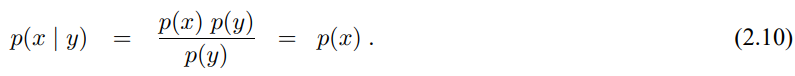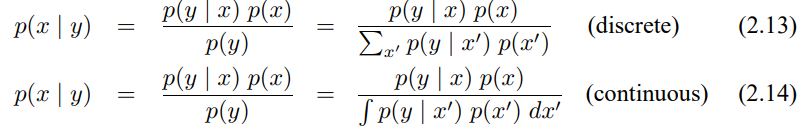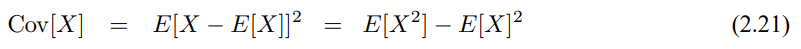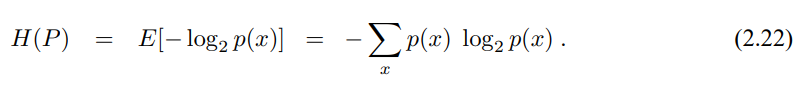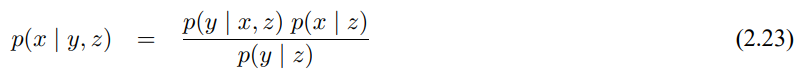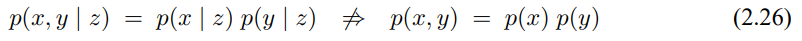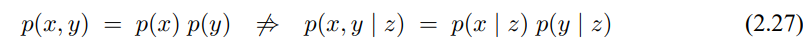3.3 확장 칼만 필터
가우시안 노이즈가 추가된 선형 상태 전이와 선형 측정이란 가정은 현실에서는 매우 드뭅니다. 예를 들면 로봇이 상수 값으로 평행, 회전 속도로 원형 운동을 할 경우 이는 선형 상태 전이로 나타낼 수 없습니다. 이러한 유니모달 신뢰도를 이용하는 것은 실제 대부분의 로봇 공학 문제에 적용하기가 어렵습니다.
확장 칼만 필터 EKF는 이러한 선형성 문제들을 극복하였습니다. 여기에는 상태/측정 확률에 비선형 함수 g와 h이 적용이 된다고 하여

이 모델은 식 (3.2), (3.5)에서 정리한 선형 가우시안 모델을 일반화 한것으로 함수 g가 행렬 식 (3.2)에서 $A_t$, $B_t$를 대체하며, 식 (3.5)에서의 행렬 $C_t$를 h로 대체하였습니다. 하지만 함수 g, h로 구한 신뢰도는 더이상 가우시안이 되지 않으므로 비선형 함수 g, h에 대해 신뢰도 갱신 수행이 불가능 하게 됩니다.
확장 칼만 필터는 실제 신뢰도를 추정을 통해 계산하며, 이 추정치를 가우시안으로 나타냅니다. 그래서 신뢰도 bel($x_t$)는 평균 $\mu_t$와 공분산 $\Sigma_t$로 나타냅니다. 확장 칼만 필터는 칼만 필터의 기본적인 신뢰도 표기법을 상속받아 사용하나 이 신뢰도는 칼만필터에서 구했던것과는 달리 추정치가 됩니다.
3.3.1 테일러 전개를 이용한 선형화 Linearization Via Taylor Expansion
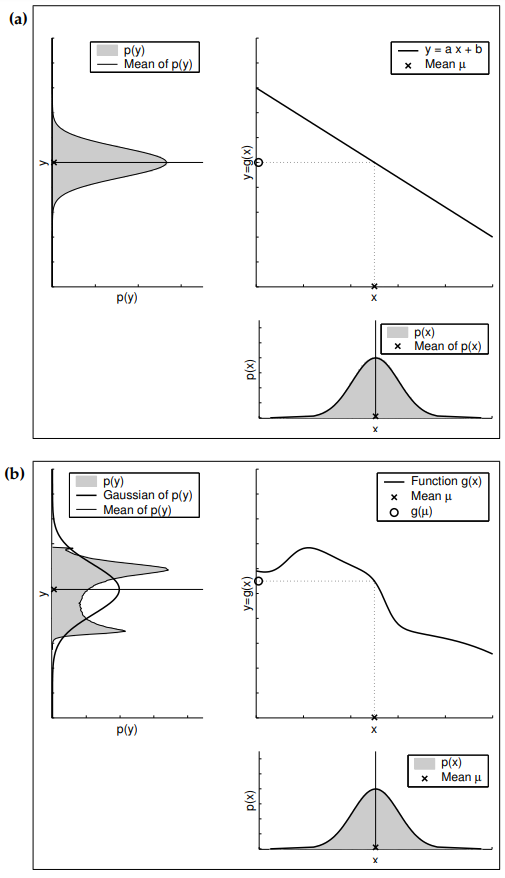
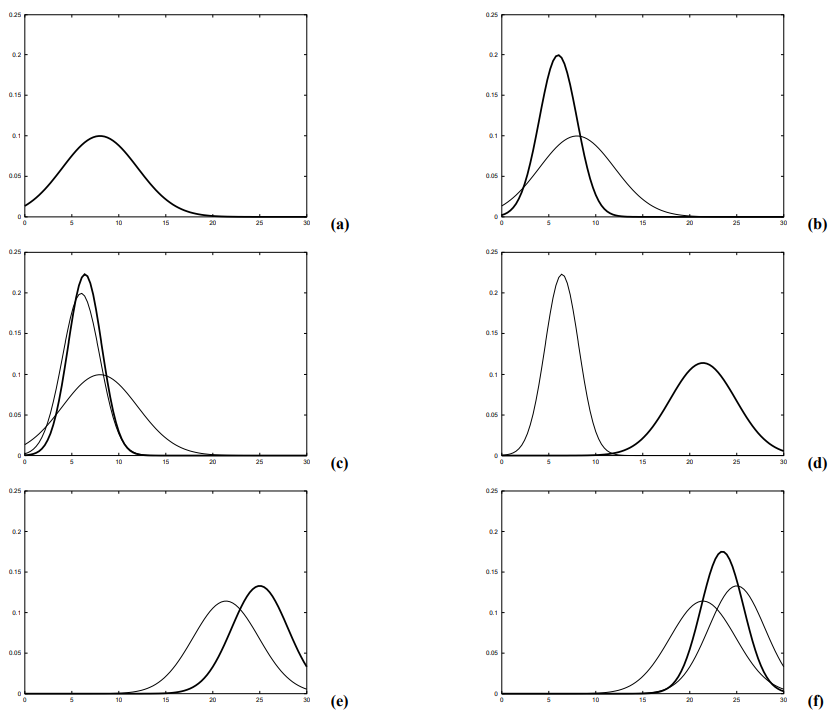
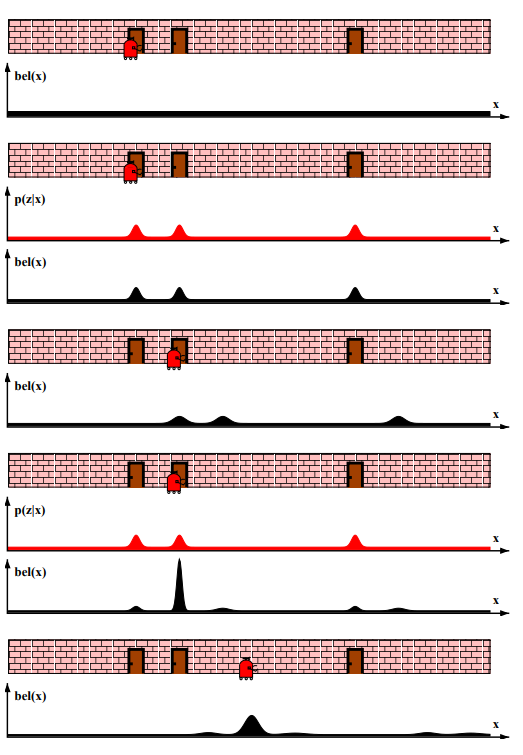
아래의 우측은 기존의 확률변수 X의 밀도 함수를 보여줍니다. 이는 확률 변수는 우측 위 그래프 함수가 적용되며(평균에서의 변환을 점선이 가르키고 있습니다.) 확률 변수 Y에 대한 결과 분포는 좌측 위 그래프에서 나타나고 있습니다.
확장 칼만필터의 핵심 아이디어는 선형화가 됩니다. 그림 3.3은 기본 컨샙을 보여주는데, 비선형 상태 함수 g가 주어졌다고 할때, 가우시안을 이함수에 사영한 결과는 비가우시안이 됩니다. 이는 비선형 함수 g가 가우시안의 형태를 바꾸도록 신뢰도를 왜곡시키기 때문인데, 선형화는 가우시안의 평균치에 g의 기울기에 대한 선형 함수로 g를 근사화 시킵니다.
이 선형 근사화에 가우시안을 사형시킴으로서 사후 확률은 가우시안이 됩니다. g가 선형화 되어지고 나서 신회도 계산과정은 기존의 칼만 필터와 동일하게 수행됩니다. 이는 측정 함수 h의 가우시안 곱 연선에서도 동일하게 적용되어 즉, EKF는 h에 대한 기울기를 나타내는 선형 함수로 h를 선형화하여 가우시안 형태의 사후 확률 신뢰도를 구합니다.
이러한 비선형 함수를 선형화하는데에는 다양한 기술들이 존재하지만, EKF에서는 1차 태일러 전개라는 방법을 사용합니다. 테일러 전개는 비선형 함수 g의 값과 기울기로 함수 g를 선형 추정 하는것으로 이 기울기에 대한 편미분은 다음과 같습니다

g의 값과 기울기는 g의 매개변수에 의해 결ㄷ정되어지며, 선형화 시간에 따라 영향을 받습니다. 가우시안인 경우 상태는 사후확률 $\mu_{t-1}$의 평균이 되며, g는 $\mu_{t-1}$에서의 값으로 근사화되며, 이 선형 추정은 $\mu_{t-1}$, $u_t$가 주어질 때 g의 기울기에 비례하게 됩니다.
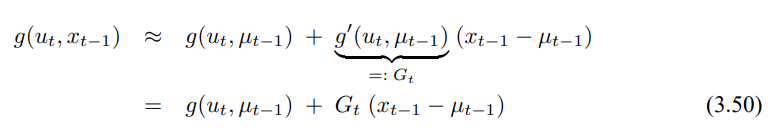
상태 전이 확률을 가우시안으로 근사화 시키면 다음과 같습니다.
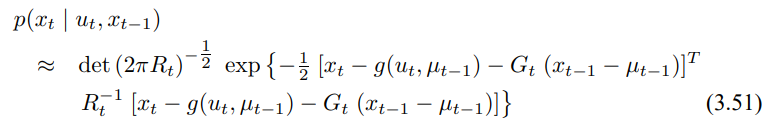
여기서 $G_t$는 크기가 n x n인 행렬로 여기서 n은 상태의 차원을 발하며 이 행렬을 자코비안이라 합니다. 자코비안의 값은 $u_t$와 $\mu_{t-1}$에 의존하는데 이는 시간에 따라 달라지게 됩니다.
EKF는 측정 함수 h에 대해서도 동일한 선형화를 수행하며 여기서 테일러 전개는 $\bar_{\mu_t}$에 대해서 수행됩니다.
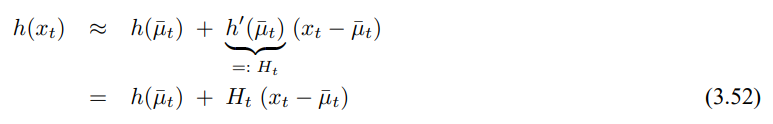
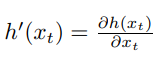
가우시안으로 이를 정리하면 다음과 같이 구할수 있습니다.
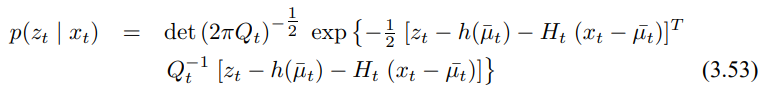
3.3.2 EKF 알고리즘
표 3.3은 EKF 알고리즘을 보여주고 있습니다. 이는 여러 부분에서 표 3.1의 칼만 필터와 비슷한 점이 많으나 가장 큰 차이점은 합이 수행되는 과정입니다.
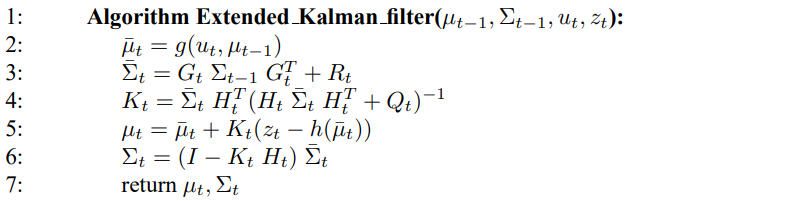
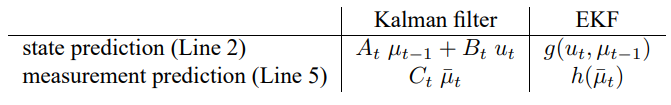
칼만 필터에서의 선형 예측 과정이 EKF의 비선형 함수로 바뀌었으며, EKF는 칼만 필터에서 선형 시스템 행렬 $A_t$, $B_t$, $C_t$ 대신 자코비안 $G_t$, $H_t$를 사용하고 있습니다. 자코비안 $G_t$는 행렬 $A_t$, $B_t$를 대신하며, 자코비안 $H_t$는 $C_t$를 대신하고 있습니다. 이에 대한 확장 칼만 필터 예시는 이후 챕터에서 살펴보겠습니다.
3.4 정보 필터
생략
3.5 정리
이번 장에서는 다변수 가우시안을 이용하여 사후확률을 나타내는 효율적인 베이즈 필터 알고리즘들을 살펴보았습니다. 여기서 다음과 같은 내용들을 살펴볼수 있었는데
- 가우시안은 2가지 방법으로 표시할 수 있었습니다. 모멘트 표현법과 표준 표현법으로 모멘트 표현법은 가우시안의 평균(1차 모멘트)와 공분산(2차 모멘트)으로 이루어집니다. 표준 표현법은 정보 행렬과 정보 벡터로 나타냅니다. 두 표현법다 동일하며 매트릭스 변환을 통해 되돌릴 수 있습니다.
- 베이즈 필터는 두 표현법으로 구현할 수 있으며, 모멘트 표현법을 사용한 경우 필터를 칼만 필터라 부르며, 표준 표현법으로 사후확률을 나타낸 것을 정보 필터라 합니다. 칼만 필터에서 제어 갱신은 간단하나 측정치 통합 과정은 어렵습니다. 반대로 정보 필터의 경우 측정치 통합은 간단하나 제어 갱신은 어렵습니다.
- 두 필터 다 올바른 사후확률을 구하며 3가지 가정이 성립되어야 합니다. 첫번째로 초기 신뢰도는 가우시안이여야 하며, 두번째는 상태 전이 확률이 가우시안 노이즈를 가지는 선형 함수여야 합니다. 세번째는 똑같은 점이 측정 확률에도 적용되어야 합니다. 이러한 세가지 가정이 적용된 시스템을 선형 가우시안 시스템이라 할 수 있습니다.
- 두 필터 다 비선형 문제를 다룰수 있도록 확장할수 있는데 이 챕터에서 비선형 함수에서의 기울기를 계산하는 과정을 살펴보았습니다. 탄젠트 기울기는 선형이되어 이 필터를 적용할수있도록 도와줍니다. 이 기울기를 찾는 기술을 태일러 전개라 하며 태일러 전개를 통해 기울기 함수의 일차 미분을 계산하여 특정 지점에 대해서 구하는 과정을 다룹니다. 이 동작의 결과로 자코비안 행렬을 구하며, 이 필터를 확장되었다고 할 수 있습니다.
- 테일러 급수 전개의 정확도는 두가지 요소에 의존합니다. 시스템의 비선형성 정도와 사후확률의 폭으로, 확장된 필터는 시스템의 상태에 대해서 잘 알고있다면 좋은 결과를 얻어 결과 공분산은 작게 됩니다. 불확실 성이 클수록 선형화 시 오차가 커지게 됩니다.
- 가우시안 필터의 주요 이점으로 계산상에서 장점을 가지고 있습니다. 갱신 과정은 상태 공간 차원에 대해 다항식 시간이 필요하나 이는 다음장에서 설명할 기술들의 경우와는 다릅니다. 가우시안의 단점은 유니모달 가우시안 분포를 이용해야만 하는것이 됩니다.
이번장에서 설명한 내용들은 로봇공학에서 가장 많이 사용하는 내용들을 기반으로 정리하였습니다. 여기서 소개한 가우시안 필터를 기반으로 수많은 바리에이션들이 있지만 여기서 가장 큰 문제점은 사후확률이 단일 가우시안으로 표현되는것이고, 이는 사후 확률이 유니모달인 경우에만 이러한 필터를 사용할수 있게 됩니다. 이는 불확실성이 제한된 로봇이 상태를 추적해 나가는 트래킹 어플리케이션에 적합할 수 있으나, 불확실성이 전역으로 증가하는 경우 단일 모드로는 불충분하여 가우시안이 실제 사후확률을 추정하는데 문제가 될수있습니다. 이러한 제한점은 잘 알려져있으므로 가우시안을 조합한 멀티모달 신뢰도를 이용하는 방법을 사용하거나 다음 챕터에서 설명할 비가우시안 방법들이 주로 사용되고 있습니다.
'번역 > 구)확률적로봇공학' 카테고리의 다른 글
| 확률적 로봇공학 - 4.1.4 정적 상태와 이진 베이즈 필터 (0) | 2020.06.22 |
|---|---|
| 확률적 로봇공학 - 4 비모수적 필터 (0) | 2020.06.22 |
| 확률적 로봇공학 - 3.2.2 칼만 필터 알고리즘 (0) | 2020.06.22 |
| 확률적 로봇공학 - 3 가우시안 필터 (0) | 2020.06.21 |
| 확률적 로봇공학 - 2.4.4 마르코브 가정 (0) | 2020.06.21 |