지난번에 전이 학습에 관한 내용들을 마무리 하고싶었는데 생각보다 내용들이 많아 마무리하지는 못했다.
이번에 전이학습 내용을 마무리해보자

그래서 이전까지 본 내용들이 선학습된 신경망을 이용한 가장 간단한 경우들로서, 특징 벡터들을 추출해서 이 벡터를 다른 알고리즘에 적용을 시켜보았다.
하지만 우리가 사용하고자하는 데이터셋이 더 크다면 미세 조정 fine tuning이란 과정을 통해서 더 나은 성능을 얻을수가 있는데, 일단 이미지넷 데이터셋으로 이미 학습된 모델을 가지고오고 맨 마지막 계층을 버린다음, 남은 마지막 계층을 새로운 데이터셋 데이터들의 카테고리를 분류할 수 있도록 재초기화를 시키자.
새 분류 데이터셋을 가지고 학습과정을 진행하면, 특징 추출기로 사용되던 모델이 역전파를 통해서 가중치가 갱신되고 분류작업을 더 잘할수 있도록 성능이 개선된다.
사용할 데이터셋이 선 학습 모델의 데이터셋보다 더 큰 경우 정리
- 기존의 전이 학습 : 이미지넷을 선학습한 알렉스넷 모델의 마지막 계층을 제거하여 특징 추출기로 사용하였다.
- 남은 마지막 계층을 새 데이터셋의 분류 카테고리를 다룰수있도록 다시 초기화하고, 새 데이터셋으로 학습 진행한다.
- 기존의 선학습 모델이 새 데이터셋에 맞게 갱신되어, 성능이 향상된다.

위 예시는 미세 조정을할때 가끔식 필요할수도 있는 방법들의 예시인데, 어떤 경우에는 학습률을 줄여야 할수도 있을거고, 다른 경우는 특징 추출한 이후 선형 모델을 학습시키고나서 전체 모델을 미세 조정 하는 경우도 있겠다.
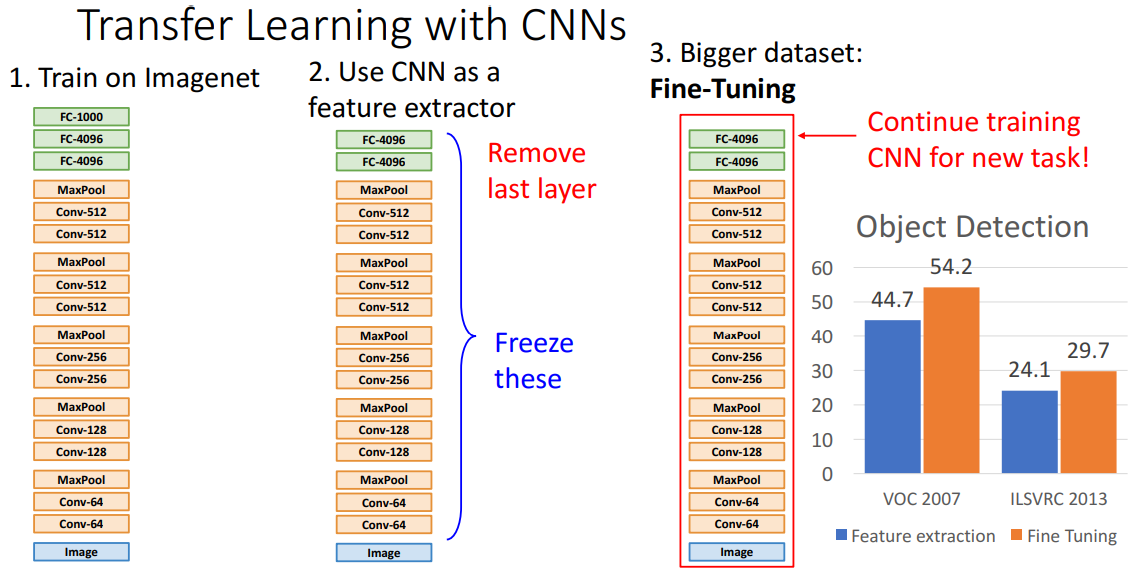
이런 미세 조정에서 추가적으로 사용하는 방법들은 실제로도 사용되고 있으며, 다양한 작업 성능을 크게 올려주었다. 위 그림은 물체 인식의 인데, 앞으로 몇 강 안에 이에 대해서 자세하게 다룰 예정이다보니 이게 어떻게 동작하는지나 수직 축의 숫자가 뭘 의미하는지 자세히 알 필요는 없다.
아무튼 여기서 파란색 막대는 서로 다른 두 데이터셋으로 물체 인식을한 전이 학습의 예시인데, 이미 학습을 마친/고정된 특징 추출기(모델)를 가지고 얻은 결과를 보여준다. 주황색 막대의 경우 새로운 데이터셋으로 전체 신경망을 학습시킨 경우로 미세 조정을 함으로서, 신경망이 특징 추출기로 사용된 전자의 경우보다 훨씬 성능이 개선되는걸 볼수 있다.

다른 관점으로 전이학습을 보자면, 이미지넷 데이터셋으로 한 모델을 학습시켜서 사용했는데, 어떤 모델을 학습시키느냐도 중요한 문제라고 할수 있겠다. 이미지넷셋에서 일반화 성능이 좋은 모델일수록 다양한 컴퓨터 비전 문제들을 더 좋은 성능으로 해결할수가 있다.
여기서 컴퓨터 비전 분야를 연구하는 사람들이 이미지넷에 대한 모델들을 다루고자하는 이유는 이미지넷을 좋아해서가 아니라, 수년간 이미지넷 셋으로 좋은 성능을 보인 모델들이 보통 다른 모든 문제들에서도 잘 동작했기 때문이다. 그래서 이미지넷을 다루는 가장 최신, 좋은 성능을 보이는 최적의 모델을 사용해서 우리가 다루고자 하는 문제에서 사용할때 더 좋은 성능을 얻을수가 있겠다.

이번 예시로 다시 객체 인식 문제로 돌아와서 보면, 이미지넷 데이터셋을 학습한 다양한 모델들을 비교한 논문을 찾기 어려워서 틀릴수도 있긴한데 물체 인식 성능 비교한 그림을 보여주고 있다. y축은 물치 인식 성능으로 0인 경우 나쁘고, 100에 가까울 수록 좋은 성능이라고 할수 있다.
2011년부터 시작하여 딥러닝 이전의 방법 Pre DL을 사용한 경우 5 정도를 얻었고, 알렉스넷을 학습후 같은 객체 인식 방법을 사용한 경우 15를 얻었으며, 알렉스넷보다 더 큰 신경망인 VGG-16으로 바꾸었을때 19로 증가하였다. Faster R-CNN이라고 부르는 새로운 방법을 사용한 경우에는 29로 증가하였고, ResNet-50을 사용시 36으로 증가하였다.
이런 추세가 계속 진행되서 이미지넷에서 더 나은 성능을 보이는 모델을 사용할수록 적은 노력을 들이고도 수많은 컴퓨터 비전 문제를 풀수가 있겠다.

어떻게 CNN에서 전이학습을 다룰지를 한번 살펴본다고하면, 우리가 풀고자하는 문제를 사용하고자 하는 데이터셋이 이미지넷과 비슷하냐 아니냐와 새로운데이터셋이 큰지 작은지에 따라 다음의 2 x 2 행렬로 분류하여 다뤄보자.

우리가 사용하는 데이터셋이 이미지넷과 비슷한경우, 그러니까 이미지넷과 비슷한 물체들을 포함한 셋인경우이나, 한 카테고리당 수십 ~ 수백개로 데이터가 적은 경우라고해보자. 그러면 선 학습된 특징 추출기 맨 위에다가 선형 학습기 같은것을 적용시키면 잘 동작하게 되겠다.
이번에는 한 카테고리당 수백 ~ 수천개의 샘플로 꽤 큰 데이터셋을 가진경우, 이미지넷으로 학습한 모델을 새 데이터셋으로 미세조정을 시킬것이고 더 잘 동작하게 된다.

하지만 이번에는 사용하려는 데이터셋이 이미지넷과 다른 경우를 보면, 데이터셋이 다르지만 많이 가지고 있는 경우에는 어떻게 해야할지 명확하게 구분되어있지는 않지만 이미지넷 모델을 초기화해서 미세조정을 하면 되겠다.

다음으로는 이미지가 다른 타입이고, 데이터셋이 작은 경우가 문제가 될수 있는데, 선학습된 모델로부터 얻은 특징으로 선형 분류기를 사용하거나 미세 조정하는 방법들은 꽤 괜찬게 동작하기는 하지만 잘못될수 있으니 주의하여야 한다.

이런 전이학습이란 방법은 컴퓨터 비전 분야에서 수 많은 문제들을 풀기위해서 수년간 사용되면서 특별한 경우에만 사용한는게 아니라 일반적이며, 주류가 되었다.

오늘날 수 많은 컴퓨터 비전 논문에서 전이 학습을 사용하고 있으며, 이미 객체 인식 문제에서 이미지넷을 선학습한 모델을 사용한 경우를 보았다. 이미지 캡셔닝이라는 분야에서도 이미지넷을 선학습한 모델 일부를 사용하고 있으며,

연구자들이 과감하게 다른 데이터셋으로 선학습된 모델들을 사용해서 다양한 경우의 이미지 캡셔닝 모델을 만들수가 있었는데, 이러한 일부 모델이 이미지넷을 선학습 되고, 다른 일부가 다른 데이터셋으로 선학습시켜 같이 사용해서 학습하고 작업을 수행하는 경우에 대해서 자세히 다루어보자.
최근 몇년간 컴퓨터 비전 분야에서 있었던 중요한 변화 중 하나는 문제를 해결할수 있는 모델을 만들수 있도록 여러번 반복해서 선학습 모델과 미세 조정 과정에 대한 파이프 라인을 찾는 것이 되었다.

컴퓨터 비전 분야에 있었던 이런 변화를 보여주는 좋은 예시로 최근 투고된 논문인데,
첫번째 단계에서 CNN을 이미지넷으로 학습시킨다.
두 번째 단계는 Visual Genome이라고 부르는 데이터셋으로 객체 인식을 하도록 CNN을 미세 조정 시킨다.
세번째 단계에서는 BERT라고 부르는 언어 모델을 학습시키는데 여기에 대한 자세한 설명은 중요치 않으니 넘어가자.
넷째 단계에서는 2, 3번째 단계의 결과를 합치고 결합된 이미지/언어 모델을 미세조정을 시키자.
다섯째 단계에서는 이미지 캡셔닝 혹은 시각 질의응답 혹은 다른 다운스트림 작업에 대해서 미세조정을 시키자.
이 모델에서 전체 과정이 어떻게 돌아가는지는 이해할 필요는 없고 이런 식으로 미세 조정과 선학습 모델들이 사용되고 있으며, 이런 식으로 전이 학습이 컴퓨터 비전 연구에서 주류가 되었고 할수 있겠다.
'번역 > 컴퓨터비전딥러닝' 카테고리의 다른 글
| 딥러닝비전 12. 순환 신경망 - 2. 순환 신경망과 계산 그래프 (0) | 2021.03.11 |
|---|---|
| 딥러닝비전 12. 순환 신경망 - 1. 이전 시간 복습과 순환 신경망 활용 (0) | 2021.03.09 |
| 딥러닝비전 11. 신경망 학습하기 파트 2 - 3. 학습 후 할 수 있는 일 (0) | 2021.03.07 |
| 딥러닝비전 11. 신경망 학습하기 파트 2 - 2. 하이퍼 파라미터 찾기 choose hyperparameter (0) | 2021.03.06 |
| 딥러닝비전 11. 신경망 학습하기 파트 2 - 1. 학습률 스캐줄 learning rate schedule (0) | 2021.02.26 |