An Introduction to Statistical Learning with Application in R
3. 모델이 데이터를 얼마나 잘 학습(적합)하였을까? how well does the model fit the data?
대표적인 모델의 적합도를 나타내는 수치 척도로는 RSE와 $R^{2}$가 있습니다. 이들은 이 모델로 설명할수 있는 분산, 변동성 variance의 정도로 이 모델이 데이터를 얼마나 잘 표현하고있는 정도라고 이해하면 될것 같습니다. 단순 선형 회귀에서도 이런 값들을 구할수가 있습니다.
한번 단순 회귀를 떠올려보면 $R^{2}$는 입력 변수와 반응 변수의 상관 계수의 제곱이었었죠. 하지만 다변수 선형 회귀에서는 Cor(Y, $\hat{Y})^{2}$가 되는데, 학습된 선형 모델과 반응 변수 사이의 상관계수의 제곱이라 할수 있어요. 그래서 학습된 선형 모델은 가능한 모든 선형 모델들 중에서 상관 관계가 강한 모델이라 할수있겠습니다.
$R^{2}$가 1에 가깝다는것은 이 모델이 반응 변수의 변동성, 분산의 상당 부분 설명할수 있다는 것을 의미해요. 예를들자면 표 3.6의 광고 데이터에서, 세 광고 매체로 판매량을 예측햇던 모델의 결정계수 $R^{2}$가 0.8972였었죠. 반면에 TV와 라디오만으로 판매량을 예측했던 모델에서 $R^{2}$는 0.89719가 되었었습니다. 이걸 다시 말하면, 표 3.4에서 신문 광고의 유의 확률 p value가 유의미하게 크지 않았던것을 봤음에도, TV와 라디오 데이터를 학습한 모델에 신문 데이터를 추가하여 학습시킨 경우 $R^{2}$가 약간 증가하는것을 볼 수 있었습니다.
그래서 $R^{2}$는 모델에 변수가 추가될때 항상 증가한다는것을 알수 있어요. 이런 추가되는 변수가 반응/출력에 약하게 연관되어 있더라두요. 이거는 최소 제곱 방정식에 다른 변수를 추가시킴으로서 더 정확하게 훈련 데이터를 학습(과적합이 심화될 수 있다는 얘기로 보임)할수 있기 때문인데, $R^{2}$ 통계량은 훈련 데이터로만 계산되다보니 무조건 증가해버립니다.
TV와 라디오로 학습한 모델에 신문 광고를 추가시킬때 $R^{2}$가 약간만 증가했다는 사실을 보면 신문 정보는 모델에서 제외시킬수 있다고 볼수 있습니다. 특히 신문 정보는 훈련 과정을 개선시키지도 않고, 그걸 포함시켰다가 오버피팅 문제로 테스트 시 성능을 떨어트리게 만들어버릴겁니다.
반대로 TV만 입력, 독립 변수로 사용했던 모델의 경우 (표 3.2에서) $R^{2}$가 0.61이엇었는데, 요기에 라디오를 추가함으로서 $R^{2}$가 상당히 증가하였습니다. 이거는 TV와 라디오 광고 예산을 증가시키는게 TV 광고만 했을때보다 훨씬 좋다는걸 의미해요. 그리고 (라디오와 TV를 학습한 모델의) 성능이 얼마나 개선 되는지는 모델의 라디오에 대한 p-value를 보고 알 수 있어요.
TV와 라디오를 학습한 모델의 RSE는 1.681이었고, 여기에 신문을 포함시킨 경우 (표3.6) RSE가 1.686이나왔습니다. 하지만 TV만 있는 모델의 경우 3.26(표3.2)가 나왔죠. 그래서 이 티비와 라디오를 같이 이용한 모델이 티비만 사용하여 예측한 모델보다 훨씬 정확한 결과를 얻을수가 있었어요. 게다가 티비와 라디오가 있는 모델에다가 신문을 추가시켜봣자 의미가 없었는걸 알수 있었구요. 독자 분들은 아마 신문을 추가시켰는데, RSS는 줄어들지만, 왜 RSE가 증가되었는지 궁금하실거에요.

일반적으로 RSE는 위와 같이 정의됩니다. 이걸 단순 선형 회귀일 경우 (3.15)로 간단하게 고칠수가 있어요. 변수가 늘어나면서 p의 증가보다 RSS의 감소가 작다면, RSE는 더 커지게 됩니다. p가 증가하면 RSS가 적게 나눠지다보니 RSE가 증가한다. 그래서 p가 증가하는것에 따라 RSS가 줄어들어야 RSE가 커지는것을 막을수 있지만 이걸 상쇄시키지 못해 RSE가 커진다는 보인다.
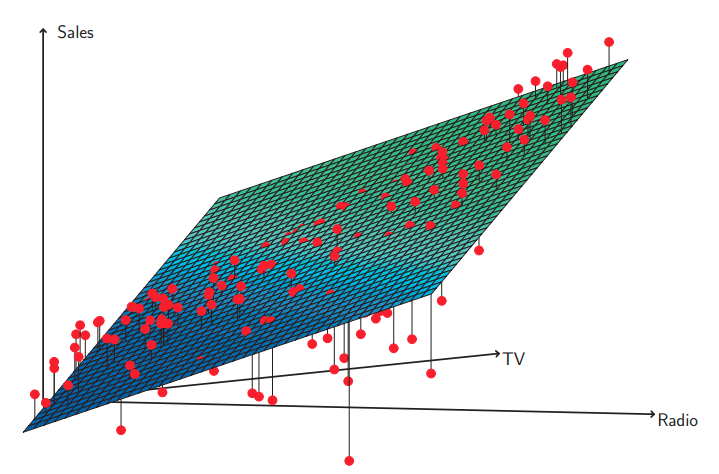
그리고 RSE와 $R^{2}$ 통계량을 이해하기 위해서 데이터를 플롯해보면 좋은데, 이걸 시각화 시키면 수치 통계량으로 볼수 없는 문제들도 볼수 있어요. 예를들면 그림 3.5는 티비와 라디오 그리고 판메량에 대한 3차원 플롯을 보여주고 있습니다. 이 그림을 보시면 어떤 관측은 최소 제곱 평면의 아래에 어떤 관측들은 최소 제곱 평면의 위에 있습니다.
특히 이 선형 모델은 티비또는 라디오 중 하나에 예산을 몰아서 많이 쓴 경우 판매량 증가가 많을거라고, 과대 추정을 하고 있으며. 두 미디어에 예산을 나누는 경우 판매량이 떨어질 것으로 과소 추정하고 있습니다. 이 비선형적인 패턴은 선형 회귀 모델로 정확하게 모델링, 표현할수가 없어요. 그래서 광고 매체 사이에 시너지 synergy, 교호작용 interaction 효과가 존재하여 미디어를 같이 사용할때 판매량이 광고 매채를 하나만 한 경우보다 훨씬 증가한다는것을 보여주고 있습니다. 이 3.3.2에서 이 선형모델을 확장시켜 이런 시너지 효과를 교호작용 항을 사용해서 포함시킬것인지를 다뤄 볼 거에요.
4. 입력 데이터셋이 주어질때, 어떤 값을 예측하여야하고 예측 결과가 얼마나 정확할까요?
Given a set of predictor values, what response value should we predict, and how accurate is our prediction?
우리가 학습된 다항 회귀 모델을 가지고 있으면 $X_{1}$, $X_{2}$, . . .$X_{p}$에 대한 데이터셋으로 Y를 예측할수 있을거에요. 하지만 우리가 구한 예측 결과에는 3가지 종류의 불확실성이 존재합니다.
1. 계수 추정치 $\widehat{\beta}_{0}$ , $\widehat{\beta}_{1}$ , . . ., $\widehat{\beta}_{p}$는 $\beta_{0}$, $\beta_{1}$, . . ., $\beta_{p}$를 추정한 것이다 보니 아래의 최소 제곱 평면 least squares plane은

참 모집단 회귀 평면 true population regression plane을 추정한 것일 뿐입니다.

그렇다 보니 추정한 계수들은 불확실성을 가지고 있어 모델의 떨어지는데 이건 2장에서 이야기한 제거 가능 오차(모델 오차)라고 볼수 있을거같아요. 아무튼 우리는 $\hat{Y}$가 f(X)에 얼마나 가까이에 존재할지 결정하는 신뢰구간을 정할수가 있습니다.
2. 물론 현실에선 f(X)는 선형 모델이다! 라고 가정하는것은 현실을 선형 모델로 근사 시킨 것일 뿐이며, 현실과 모델 사이의 괴리인 모델 편향 model bias라고 부르는 제거 가능 오차가 생기게 됩니다. 그래서 우리가 선형 모델을 사용한다고 할 때, 실제 평면에 가까운 최적의 선형 근사 결과물을 추정하는것이며 여기에 존재하는 오차를 무시하더라도 선형 모델은 올바르게 동작할 거에요.
3. 우리가 f(X) 혹은 실제 계수 $\beta_{0}$, $\beta_{1}$, . . ., $\beta_{p}$를 알고있다 하더라도 출력값,반응변수의 값은 완벽하게 예측 할 수 없습니다. 왜냐하면 이 모델 (3.21)은 오차항 $\epsilon$을 가지고 있거든요.
우리는 신뢰구간 confidence interval은 판매량 평균의 불확실성 정도를 측정하기 위해 사용하는 지표인데, 예를들어 TV 광고비용으로 10만달러를 쓰고, 라디오 공과에는 2만 달러를 썻다고 해요. 그러면 95% 신뢰 구간은 [10,985 11,528] 이 되는데, 이것은 실제 f(X)의 값의 평균이 95%의 정확도로 포함하고 있을 구간을 이야기 해요.
그리고 예측 구간 prediction interval은 특정 도시에서의 판매량의 불확실성 정도를 나타내는 개념인데, TV 광고 예산에 100,000달러 라디오 광고 예산에 20,000 달러를 사용한 경우 한 도시에서 예측되는 95% 예측 구간은 [7,930 14,580]이며, 실제 Y의 한 값이 95%의 확률로 포함되는 구간을 의미합니다. 보면 예측 구간은 신뢰 구간보다 훨씬 큰데, 이는 한 도시의 판매량만을 보았을 때는 모든 도시의 평균 판매량의 불확실한 정도보다 그 불확실함이 훨씬 크다고 할 수 있기 때문입니다.
3.3 회귀 모델에서 다른 고려 사항들 Other Consideration in the Regression Model
3.3.1 질적 변수를 사용할 때 Qualitative Predictors
지금까지 살펴본 내용들을 보면 선형 회귀 모델에 사용하는 모든 변수들이 양적 변수 Quantitative라고 가정하여 보았습니다. 하지만 현실에서는 일부 입력변수, 독립변수, 예측자들은 질적 변수 Qualitative인 경우도 있어요.

예를들어 그림 3.6에 있는 신용 정보를 한번 봅시다. 여기에는 채무 잔액 balance(평균 신용 카드 채무 잔액) 뿐만이 아니라 질적 변수 quantitative로 나이와 카드 cards(카드 갯수), 학업기간 education(학업기간), 수입(천달러 단위), 한도(신용 한도), 신용 평가 점수 rating등이 있습니다. 그림 3.6의 각 판낼들은 스캐터 플롯 그러니까 산점도를 보여주고 있는데, 이 스캐터 플롯은 두개의 변수들 행과 열로 보여주고 있어요.
예를들면 "balance 채무 잔액"이란 글씨 바로 오른쪽에 채무 잔액과 나이에 대한 산점도가 있고, "age 나이" 글씨 바로 오른쪽에는 나이와 신용카드 갯수에 대한 산점도가 있습니다. 이 외에도 4개의 양적변수로 성별, 학생여부 student, 혼인 상태 martial status, 인종 ethnicity(백인, 흑인, 아시안)가 있습니다.
두 가지 경우만 존재할때 예측하는 경우 Predictors with only two levels
한번 다른 변수들은 다 무시하고, 남성과 여성에 따른 신용 카드 채무 잔액을 한번 살펴봅시다. 이렇게 남성/여성으로 질적 변수, 질적 예측자 qualitative predictor가 2가지의 경우로 나뉘는 경우는 회귀 모델에 정말 쉽게 반영시킬수가 있어요. 이 때 가 변수 dummy variable이라고 부르는 변수를 만드는데, 이 가 변수는 0또는 1 두개의 수치값가져요. 예시를 보면 우린 성별이란 변수를 가지고 있으니 이걸로 아래와 같은 형태의 새로운 가변수를 만들수가 있습니다.

그리고 이 가변수가 회귀 방정식에 입력 변수로 사용하여 아래의 모델을 만들수가 있겟죠.

그러면 $\beta_{0}$는 남성의 평균 신용카드 채무 잔액이며, $\beta_{0}$ + $\beta_{1}$은 여성의 평균 신용카드 채무 잔액가 되겠죠. 그리고 $\beta_{1}$은 남성과 여성사이 신용 카드 채무 잔액의 평균적인 차이가 되겠습니다.

표 3.7은 (3.27) 모델의 계수 추정치와 다른 정보들을 보여주고 있어요. 남성의 평균 채무 잔액은 509.80이며, 여성의 경우 19.73달러가 추가되어 총 잔액가 $509.80 + $19.73 = $529.53달러가 됩니다. 하지만 가변수의 p value를 보시면 0.6690으로 엄청 높죠. 그래서 이게 성별과 신용카드 잔액 사이에는 유의미한 관계(성별에 따른 차이)가 존재하지 않는다는 통계적인 근거가 되겠습니다.
* 이전에 단순 선형 회귀에서 가설 검정을 할때를 떠올려보세요 입력 변수 X와 종속 변수 Y간에 유의미한 관계가 존재하는 경우 p value가 낮았었고, 귀무가설(X와 Y는 유의미한 관계를 갖지 않는다.)을 기각하는 대신 대립 가설(X와 Y는 유의미한 관계를 갖는다)를 채택하였엇죠.
아까 (3.27)에서 여성은 1, 남성은 0로 인코딩을 시켰지만 이건 회귀 적합에 영향을 주지는 않고 대신 계수의 해석 과정이 조금 달라질수는 있어요. 남성이 1이고, 여성이 0인 경우 $\beta_{0}$ = 529.53 그리고 $\beta_{1}$ = -19.73이 되어 남성은 $529.53 - $19.73 - $509.80이 되고, 여성은 $529.53으로 해석만 조금 달라지지 같은 결과가 나오게 됩니다.
0/1로 인코딩하는 대신에 가변수를 아래와 같이 사용할수도 있는데

이 가변수를 사용하면 회귀 방정식이 아래와 같이 바뀌겠죠.

여기서 $\beta_{0}$는 전반적인 평균 신용카드 채무 잔액(성별의 영향을 무시한)이고, $\beta_{1}$은 여성일 경우 평균 보다 떨어트리고, 남성일 경우 평균보다 높이는 값일 거에요. 이 예시에서 $\beta_{0}$ 추정치는 $519.665으로 남성과 여성의 평균치가 됩니다. $\beta{1}$ 추정치는 $19.73의 절반인 9.865가 되어요.
여기서 여러분들이 알아야 할 점은 인코딩 방식이 좀 달라지더라도 남성과 여성에 대한 신용카드 채무 잔액 예측치는 동일하다는 점이고, 그냥 계수를 이해하는 과정만 조금 바뀔 뿐입니다.
질적 변수가 여러 가지의 경우의 수를 갖는 경우 Qualitative Predictors with More than Two level
아까는 한 성별이라는 입력/질적 변수가 남자, 여자 2가지 경우의 값만을 가지고 있었는데, 이번에는 질적 변수가 2개 이상의 값을 가졌다고 해봅시다. 그러면 하나의 가변수(0, 1) 만으로는 모든 경우를 나타내지는못할거에요. 이런 경우 가변수를 여러개를 사용해야 합니다. 예를들어 인종 변수의 경우 2개의 가변수를 사용하여야 합니다. 첫번째는

두번째는

이 두 가변수들을 회귀 방정식에다가 적용하여 다음의 3가지 경우에 대한 모델을 만들어 낼 수가 있어요.

여기서 $\beta_{0}$는 흑인의 평균 신용 카드 채무 잔액, $\beta_{1}$은 흑인과 아시안의 평균 채무 잔액 차이, $\beta_{2}$는 백인과 학은의 평균 채무 차이를 나타낸다고 볼수 있을거에요. 이처럼 가변수는 경우의 수 혹은 카테고리 갯수보다 1개 적은 개수의 가변수가 필요합니다. 카테고리가 3개라면 가변수가 2개, 지금 예시처럼요. 이 예제에서 가변수가 존재하지 않은 흑인이 베이스라인이라고 할수 있겠습니다.

표 3.8을 보시면 흑인의 채무 잔액 추정치가 베이스라인이(절편 intercept에 있는데) $531달러인것을 볼수 있어요. 그리고 아시안인 경우 흑인 보다 $18.69 달러가 적다고 추정하고 있으며, 백인의 경우 흑인보다 $12.50$달러 적다고 나오고 있습니다. 하지만 두 계수 추정치의 p value가 상당히 높게 나오고 있어요. 그러므로 인종은 신용 카드 채무 잔액을 추정하는데 (관계성을 가지는) 유의미한 변수가 아니라고 판단할 수 있겠습니다. 인종에 따라 구한 채무 잔액 예측을 해도 거의 같다? 혹은 인종이 상관없이 비슷한 채무 잔액 예측치가 나온다는 얘기입니다.
하지만 이 계수와 pvalue들은 가변수의 어떤 카테고리에 속해있느냐에 따라 영향을 받고 있다보니, 이보다는 귀무 가설 $H_{0}$ : $\beta_{1}$ = $\beta_{2}$ = 0을 F검정으로 검정을 하면, $\beta_{1}$과 $\beta_{2}$가 0이다 즉 영향이 존재하지 않는다는 것을 귀무가설로 가설 검증을 하는것으로 볼 수 있는데, 이 경우 유의 확률이 0.96가 되어 인종과 채무 잔액 사이에 관계가 존재하지 않는다는 귀무가설을 채택할 수 있습니다.
* 표 3.8은 각 카테고리별 계수와 p value를 구하다 보니 좀 다르지만, 이걸 합쳐 $\beta_{1}$ = $\beta_{2}$ = 0을 귀무가설로 가설 검증할때는 유의 확률 p value가 0.96으로 또 바뀜.
질적 변수랑 양적 변수를 둘다 사용할때도 가변수는 쉽게 사용할수 있어요. 예를 들자면 채무 잔액을 수입이란 양적 변수와 학생 여부에 대한 질적 변수로 회귀, 추정할때 그저 수입 변수에다가 학생에 대한 가변수만 추가시키고 다변수 회귀 모델을 사용하면 되요.
가변수 말고도 질적변수를 코딩하는 많은 방법들이 있지만, 모든 방법들은 다 모델 학습 결과는 똑같고 모델을 어떻게 이해하면 될지만 조금씩 달라집니다.
3.3.2 선형 모델의 확장 Extensions of the Linear Model
기본 선형 회귀 모델 (3.19)는 이해하기 쉽고 다양한 형실 세계 문제들에서도 잘 동작하고 있습니다. 하지만 이 선형 모델에는 현실 세계를 종종 무시하는 강한 가정들이 존재하는데, 가장 중요한 두 가정으로 입력과 출력 사이의 관계가 선형 linear적이고, 가산적 additive이어야 한다는 가정이 있습니다.
가산 가정 additive assuption은 입력 $X_{j}$가 변할때 반응 변수 Y에 주는 영향력이 다른 입력변수의 값에 독립적이어야 한다는 가정입니다. 다시 말하면, $X_{j}$에 의한 Y의 변화량은 다른 변수의 영향과는 상관없어야 한다는 얘기에요. 다음으로 선형 가정 liear assumption은 $X_{j}$가 바뀔때 Y도 상수배 만큼 변해야 한다는 말로, 입력 변수와 종속 변수 간에 직선, 그러니까 선형적인 관계를 가져야 한다는 가정입니다. 이 자료에서 이 두가정들을 완화시키는 방법들을 볼건데, 우선 선형 모델을 확장시킨 고전적인 방법들 부터 살펴봅시다.
가산 가정을 완화시키기 Removing the Additive Assuption
이전에 광고 데이터를 보면서 우리는 티비와 라디오 광고가 판매량과 연관성을 가지고 있다고 결론을 내렸어요. 선형 모델은 이 결론을 가지고 만들어 지는데, 한 매체의 광고 예산을 증가시켜 판매량을 늘린 영향이 다른 매체의 광고비용에 독립, 영향을 받지 않는다고 가정합니다. 예를 들면 (3.20)의 선형 모델을 보면 TV가 1 만큼 증가할때 판매량에 미치는 평균적인 영향이 $\beta_{1}$인걸 보여주고 있어요. 라디오 광고 예산과는 상관없이요. 뒤집어 말하면 라디오 광고 예산이 얼마던 간에 TV 광고 비가 1이 오르면 판매량이 $\beta_{1}$이 늘어난다고 할수 있을거같네요.
하지만 이 가정은 잘못되었습니다. 라디오 광고를 늘리면 TV 광고 효과도 증가해서(교호작용 혹은 시너지 효과) 라디오에 의한 계수, 기울기 항 베타가 증가할때 TV의 기울기 항 beta도 증가하거든요. 100,000달러의 예산이 주어졌고, 우리가 라디오에 절반, 티비에 절반 놓고 광고를 했다고 합시다. 그러면 TV나 라디오 둘중 하나에 10만 달러 광고를 한것 보다 더 큰 판매 효과를 얻을수가 있어요.

시장에선 이걸 시너지 효과 synergy effect라 부르고, 통계학에서는 이것을 교호작용 interaction effect라고 부릅니다. 그림 3.5는 광고 데이터 셋에서 교호 작용이 어떻게 일어나를 볼수 있었어요. TV나 라디오 둘 중 하나의 광고 비용이 낮았다면 실제 판매량은 선형 모델이 예측한 것 보다 낮았었죠.(다중 선형 회귀 평면 아래에 실제 관측치가 존재함) 하지만 두 매체로 나눠서 광고 할때는 실제 판매량이 더 높은데 모델은 낮게 판매하는 과소 추정하는 경향이 있었습니다.(판매량 관측치, 빨간점보다 다중 선형 회귀 평면이 아래에 있었음)
아래와 같이 두 변수가 주어진 표준 선형 회귀 모델이 주어질때,

이 모델에 따르면 $X_{1}$을 한단위 혹은 1을 증가시키는 경우 Y는 $\beta_{1}$만큼 증가하게 될겁니다. 하지만 $X_{2}$는 무슨 값이 오더라도 Y가 변하는데 추가적인 영향을 주지 못해요. 그래서 교호 작용을 반영하도록 이 모델을 확장시키는 방법은 3번째 입력 변수로 교호작용 항 interaction term을 추가시키는 것입니다. 이 항은 $X_{1}$과 $X_{2}$의 곱으로 계산할 수 있어요. 그러면 이 모델은 아래와 같이 정리 할수 있겠죠.

그러면 이 교호작용향을 추가시킬때 가산 가정을 얼마나 완화시킬수 있을까요? 위 식 (3.31)을 아래와 같이 $\widetilde{\beta}_{1}$ = $\beta_{1}$ + $\beta_{3}$ X 로 하여 고칠수가 있어요.

여기서 $\widetilde{\beta}_{1}$는 $X_{2}$에 의해 변할수 있기 때문에 $X_{1}$이 Y에 미치는 영향이 더 이상은 (직선의 기울기 처럼)상수가 아닌 변수로 영향을 주게 됩니다. 그러면 $X_{2}$를 조절시킴으로서 $X_{1}$이 Y에 주는 영향력을 바꿀수가 있어요.
한번 제품을 생산한느 공장의 예시를 들어 볼게요. 우리는 직원의 수와 생산 라인의 수로 생산할수 있는 제품 양을 예측하고 싶다고 합시다. 아마 생산 라인은 직원의 수에 의존한다고 볼수 있을 겁니다. 왜냐면 직원들이 없으면 생산 라인을 돌릴수가 없잔아요. 그래서 생산 라인의 수만을 늘린다고해서 제품 생산이 늘어나지는 않을 거에요.
이를 고려하면 선형 모델에는 생산 라인과 직원 수 사이에 교호작용을 나타내는 항을 추가를 해야 선형 모델이 생산량을 더 잘 예측할수 있을거에요. 그렇게 모델을 학습시켜 아래의 식을 얻었습니다.

다시 정리하자면 생산 라인을 늘리면 '3.4 + 1.4 x 직원의 수'만큼 생산량이 증가하게 될거에요. 이렇게 정리하면 우리가 직원을 더 많이 고용하고 있을수록 생산라인의 제품 생산량도 더 많아지겠죠.
그러면 우리가 계속 보던 광고 예시로 돌아갑시다. 라디오와 티비로만 있던 선형모델에 두 매체의 교호 작용 향을 추가하여 판매량을 예측한다면 아래의 형태가 되겟죠.

그러면 역서 $\beta_{3}$을 TV 광고를 늘릴떄 라디오 광고를 늘리는 효과 혹은 그 반대로도 볼수 있겠죠. 식 (3.33)의 모델을 학습한 결과는 표 3.9에서 볼수 있겠습니다.

표 3.9의 결과를 보면 교호 작용을 포함 시킨 모델이 그렇지 않은 모델보다 더 뛰어나다는것을 알 수 있어요. 교호 작용 항 TV x 라디오의 p value가 엄청 낮은데, 이건 대립 가설 $H_{a}$ : $\beta_{3}$ $\neq$ 0이라는 강한 통계적 증거이죠.($beta_{3}$은 판매량과 큰 관계를 가지고 있다.) 즉, 다시 말하자면 입력 변수와 판매량 사이의 실제 관계, 실제 모델은 가산적이지는 않다는 얘기이죠.
식 (3.33) 모델의 $R^{2}$는 96.8%인데, 교호작용없이 티비와 라디오만으로 판매량을 예측한 모델이 89.7%였던것에 비해 데이터의 설명력이 커졌다는것을 알수 있습니다. 이것은 (96.8 - 89.7)/(100 - 89.7)= 69%, 가산 모델만을 학습하였을때 판매량에 대한 변동성의 69%를 교호 작용 항을 추가시킴으로서 설명할수 있게 되었다는 얘기입니다. * 교호작용이 기존 가산 모델이 설명 못하던 부분의 상당 부분을 설명할수 있게 만들었습니다.
표 3.9에서 추정한 계수들을 보면 TV 광고 예산 1000달러가 증가할때 ($\widehat{\beta}_{1}$ + $\widehat{\beta}_{3}$
x 라디오) x 1,000 = 19 + 1.1 x radio만큼 판매량이 증가하게 됩니다. 라디오 광고 예산이 1000달러 증가하는 경우 ($\widehat{\beta}_{2}$ + $\widehat{\beta}_{3}$ x TV) x 1,000 = 29 + 1.1 x TV만큼 판매량이 증가하게 되구요.
이 예시에서 TV, 라디오, 교호작용 항에 대한 p value는 (표 3.9) 모두 통계적으로 유의미한 값을 가지고 있어, 이 세 변수들이 모두 모델에 포함되어있어야 한다고볼수 있습니다. 하지만 교호작용 항의 p value가 매우 작은데, 주 변수들(지금의 경우는 TV와 라디오)의 p value가 작지 않은 경우도 존재합니다.
계층적 원칙 hierachical principle에 따르면 모델에 교호작용 항을 포함시킨다면, 주 변수들의 p value가 낮아 유의미 하지 않더라도, 당연히 주 변수들도 포함시켜야 합니다. 다시 말하자면, $X_{1}$가 $X_{2}$의 교호작용 항이 중요한 경우 $X_{1}$, $X_{2}$의 계수 추정치가 유의미 하지 않더라도 둘다 모델에 포함시켜야 한다는 이야기 입니다.
이 이론적인 원칙의 근거는 $X_{1}$ x $X_{2}$가 반응에 영향을 준다면, $X_{1}$ 또는 $X_{2}$의 계수가 0이더라도 상관없기 때문입니다. $X_{1}$ x $X_{2}$는 $X_{1}$과 $X_{2}$사이에 상관관계가 존재한다는걸 의미하다보니 이 영향을 없앤다면 상호작용의 효과가 사라지게 될겁니다.
이전 예시에서 둘다 질적 변수인 TV와 라디오 사이의 교호작용, 상호작용에 대해 이야기 했는데, 상호작용의 개념은 질적 변수와 양적 변수 사이에도 존재합니다. 질적 변수와 양적 변수의 상호작용은 이해하기 쉬운데, 3.3.1에서 봤던 신용카드 데이터셋으로 양적 변수인 수입과 질적 변수인 학생 여부 두 변수를 사용하여 카드 채무 잔액 balance를 예측하여 봅시다.
교호작용 항이 없는 경우 이 모델은 아래의 형태가 되겠죠.

위를 보시면 카드 채무 잔액이 학생인 경우와 학생이 아닌 경우 두 경우로 데이터를 학습하고 있는게 보이는데, 학생인 경우와 학생이 아닌 경우는 $\beta_{0}$ + $\beta_{2}$와 $\beta_{0}$로 서로 다른 절편 intercept을 가지고 있습니다. 하지만 같은 기울기 slope $\beta_{1}$을 가지고 있죠.

이걸 그림 3.7의 왼쪽 판낼에서 볼 수 있어요. 두 직선이 평행한 이유는 수입이 증가함에 따라 채무 잔액의 변화 정도가 학생 여부에 상관없이 동일하기 때문입니다(쉽게 말하면 기울기가 같다). 하지만 실제로는 수입에 변화가 생기면 학생과 학생이 아닌 경우의 신용 잔액에 영향을 미칠수 있기 때문에 이 모델은 한계가 있다고 볼수 있어요.
이 한계를 (수입과 학생에 대한 가변수를 곱함으로서 모델에 반영시키는) 교호작용 변수를 추가하여 모델에서 고려할수 있게 되는데, 그려면 기존의 모델은 아래와 같이 바뀌게 될 거에요.

그러면 학생인 경우와 학생이 아닌 경우 다른 회귀직선이 만들어 졌습니다. 두 회귀 직선은 서로 다른 절편 $\beta_{0}$ + $\beta_{2}$와 $\beta_{0}$을 가지고 있고, 또 서로 다른 기울기 $\beta_{1}$ + $\beta_{3}$ 과 $\beta_{1}$을가지게되요. 이렇게 하여 학생과 학생이 아닌 경우 수입의 변화가 신용 카드 채무 잔액에 어떻게 영향을 미치는지를 반영시킬수가 있게 되었습니다.
그림 3.7의 오른쪽 판낼이 모델 (3.35)의 학생 여부에 따른 수입과 채무 잔액 사이의 추정한 관계를 보여주고 있습니다. 이 그림을 보면 학생의 기울기가 학생이 아닌 사람들의 것보다 낮은데, 이걸 보면 학생들은 소득이 증가한다고 해도 학생이 아닌사람들 보다는 채무 잔액이 덜 증가한다는 의미가 되겠습니다.
비선형 관계 Non Linear Relationhips
이전에도 이야기 한거지만 (3.19)의 선형 회귀 모델은 입력과 출력 사이에 선형 관계를 가진다고 가정을 하고 있습니다. 하지만 입력과 출력 사이의 실제 관계 true relationship가 비선형일 수도 있습니다. 하지만 선형 회귀를 확장시켜 비선형 관계를 다룰수 있는 간단한 방법으로 다항 회귀 polynomial regression가 있습니다. 차후에는 더 일반적인 환경, 상황에서 비선형 학습이 가능한 복잡한 방법들을 봅시다.

그림 3.8은 차량 데이터셋에서 구한 차량들의 mpg(1갤런당 마일)와 마력 정보들을 보여주고 있어요. 주황색 적선은 선형 회귀 모델인데, mpg와 마력에는 선형 보다는 복잡한 비선형 관계가 있는걸로 보이내요. 그래서인지 데이터가 커브드 된 형태로 보이고 있습니다. 비선형성을 선형 모델에 반영시키는 간단한 방법은 입력 변수의 변형을 모델에다가 추가시키면 됩니다.
예를 들어 그림 3.8의 점들이 이차적인 quadratic 형태를 보이다보니 이 모델의 형태를 아래와 같이 만들면 더 적합할 거에요.

식 3.36은 마력에 대한 비선형 함수로 mpg를 예측하고 있어요. 하지만 이건 여전히 선형 모델입니다! 식 (3.36)은 간단하게 말하자면 $X_{1}$ = 마력, $X_{2}$ = $마력^{2}$인 다중 선형 회귀 모델이라고 할 수 있거든요. 그림 3.8의 파란색 커브는 데이터를 이차적으로 이차 모델로, 적합/학습시킨 결과라고 볼 수 있겠습니다.
그래서 선형 항만 사용하여 학습했을때보다 이차 항을 포함하여 학습했을때 훨씬 좋아질수 있었습니다. 이차 적합 모델의 $R^{2}$는 0.688이고, 선형 학습 모델의 경우 0.606이되며, 유의확률은 표 3.10에서 볼수 있는데, 이차 항의 p value를 보면 이차항이 상당히 유의미하다는 걸 알수 있어요.

그림 3.8의 녹색 커브는 모델 (3.36)을 5차 다항식까지 차수를 올려 학습시킨 결과인데, 학습 결과가 너무 과하게 데이터와 가까워져 있는것을 볼수 있습니다. 그래서 항상 항을 추가시킨다고 해서 데이터를 학습하는데 도움이된다고는 할순 없습니다.
이런식으로 선형 모델을 비선형적인 관계도 다룰 수 있도록 확장시키는 방법을 다항 회귀 polynomial regression이라 부릅니다. 회귀 모델의 입력 변수로 다항식을 만들었기 때문이거든요. 이 방법과 다른 선형 모델을 확장판들을 7장에서 보겠습니다.
3.3.3 잠재적으로 존재하는 문제들 Potential Problems
우리가 특정한 데이터셋에 선형 회귀 모델을 학습시킨다고 할때, 많은 문제가 발생 할 수가 있어요. 가장 흔한 문제들로 아래의 것들이 있습니다.
1. 입력과 출력사이 비선형 관계
2. 오차항의 상관관계 correlation of error terms
3. 오차항의 상수가 아닌 분산 non constant variance of error terms
4. 아웃라이어 outlier
5. 아주 강한 데이터들(모델이 학습하는 과정에 큰 영향력을 준다고 해석하여 이렇게 적음) High leverage point
6. 공선성 collinearity
현실에서는 이런 문제들이 존재하는지를 찾아내고 극복하는것이 과학의 예술이라 할수 있으며 수많은 책들이 이 주제들을 다루어 왔어요. 선형 회귀 모델은 우리가 다루고자하는 핵심은 아니다보니 중요한 내용들을 간단하게만 보겠습니다.
1. 데이터의 비선형성 Non linearity of the Data
선형 회귀 모델은 입력과 출력 사이에 직선/선형적인 관계를 갖는다고 가정하고 있습니다. 하지만 실제 모델, 실제 관계가 선형이 아닌 경우, 학습한 모델로 구한 모든 예측치/결론들이 잘못되지 않았는가 의심하여야 합니다. 게다가 이 모델의 추정 정확도는 크게 떨어질거에요.
잔차 Residual(실제 측정값 - 예측/추정한 값) 플롯은 비선형성이 존재하는지를 확인하는데 좋은 시작적인 도구입니다. 단순 선형 회귀 모델이 주어지면, 입력 $x_{i}$에 대한 잔차 $e_{i}$ = $y_{i}$ - $\widehat{y}_{i}$를 그려낼수가 있어요. 또 다중 회귀 모델의 경우에는 입력 변수가 다양하다 보니 잔차 플롯에서 입력과 잔차를 사용하는 대신 예측값 $\widehat{y}_{i}$과 잔차를 이용하여 플롯 시킵니다. 이상적으로 모델이 현실과 동일하다면 잔차(실제와모델의 예측의 차이) 플롯에서는 눈에띄는 패턴이 존재하지 않을것입니다. 하지만 패턴이 존재한다면 선형 모델이 어떤 점에서 문제를 가지고 있다는 얘기가 되겠죠.

그림 3.9의 왼쪽 판낼에서는 차량 데이터셋에서 마력으로 mpg를 선형 회귀한 모델로 만든 잔차 플롯을 보여주고 있습니다. 빨간 선은 잔차를 학습한 것으로 데이터의 트랜드를 더 쉽게 파악하는데 도움이 되는데, 잔차들이 명확하게 U 형태로 존재하는걸 보면 데이터에 강한 비선형성이 있다는것을 알 수 있습니다. 반면에 그림 3.9의 우측 판낼은 이차항이 들어간 모델 (3.36)으로 만든 잔차 플롯이다 보니 잔차가 크지않은 패턴을 보이고 있으며, 이는 이차 항 덕분에 데이터의 학습이 개선되었다는 걸 알 수 있어요.
잔차 플롯으로 데이터에 비선형적인 관계가 존재하는것을 확인했다면, 간단한 방법은 입력 변수를 log X, $\sqrt{X}$, $X^{2}$ 비선형으로 변환하여 사용하면 반영 시킬 수 있습니다. 차후에는 더 개선된 다른 비선형 방법들도 배워봅시다.
2. 오차항의 상관관계 Correlation of Error terms
선형 회귀 모델에서 중요한 가정은 오차항 $\epsilon_{1}$, $\epsilon_{2}$, . . ., $\epsilon_{n}$는 상관관계가 존재하지 않는다는 것입니다. 이게 무슨 소리일까요? 예를 들면 오차가 서로 상관관계가 없다면 오차 항 $\epsilon_{i}$는 다음 오차 $\epsilon_{i+1}$에 대해 아무런 정보를 주지않는다는 말입니다. 표준 오차는 추정된 회귀 계수나 오차항의 비상관성을 따르는 학습 값으로 계산 할 수 있습니다.
하지만 오차항에 상관관계가 존재한다면, 추정된 표준 오차는 실제 표준 오차를 과소추정하는 경향을 가지게 됩니다. 그 결과 계수와 예측 사이의 간격은 더 넓어지게 될거에요. 다시 정리하면 오차 간에 상관관계가 존재할 경우, 오차끼리의 영향으로 오차가 더 강해질 것이고 실제 오차보다 큰 오차가 생기겠죠(실제 오차가 추정 오차보다 훨씬 작아진다). 그래서 추정된 표준 오차가 실제 표준 오차를 과소 추정한다는 말로 보여요.
예를 들어 현실에서 95%의 신뢰 구간을가지고 있어나 실제 값을 그 구간 안에 가질 확률이 95%보다 떨어질 수 있습니다. 게다가 모델의 p value는 기존의 것보다 더 떨어지게 될거에요. 이는 통계적으로 유의미함을 판단하는데 에러를 야기시킬수가 있어요. 정리하자면 오차항이 서로 상관관계를 가질때 우리가 만든 모델을 신뢰할수 없게 됩니다.
구체적인 예를 들면 우리가 가지고 있는데이터가 사고로 2배가 되었다고 해봅시다. 관측과 오차항은 동일하구요. 하지만 이 사실을 무시하여 복사된 데이터의 관측치와 오차항이 동일하지 않다고 하면, 표준 오차를 계산시에 샘플 수가 2n인것 처럼 될것입니다. 또, 이 데이터로 구한 모델의 파라미터 추정치는 2n개의 샘플로 구한것과 n개의 샘플로 구한것이 동일하나 신뢰 구간은 $\sqrt{2}$의 배수(by a factor of)만큼 좁아지게 됩니다
오차항 사이에 왜 상관관계가 발생할까요? 상관 관계가 자주 발생하는 경우가 시계열 time series 데이터인데, 이산적인 시간 간격으로 얻은 관측치들로 이루어져 있습니다. 많은 경우 인접한 시간때 구한 관측치들이 양의 상관관계를 갖는 오차들을 가지게 됩니다.
주어진 데이터셋에서 오차 항에 상관관계가 존재하는지를 판단하기 위해서는 시간 변화에 대한 모델의 잔차를 플롯시켜보면 됩니다. 오차가 상관관계를 갖지 않는 경우 눈에 띄는 패턴이 발생하지 않을 겁니다. 하지만 오차항이 양의 상관 관계를 갖는다면, 잔차 상으로 추적해갈수 있는 무언가가 보이게 되는데, 그게 인접 잔차 adjacent residual로 비슷한 값을 가지고 있을거에요.
다시 말하면 오차가 상관관계를 갖는 경우 시계열 데이터 잔차 플롯 상에서, 오차가 서로 상관되다보니 서로 비슷한 값을 보이는 인접 잔차들이 존재함. 오차항이 상관되지 않다면 인접 잔차가 비슷한것끼리 뭉치지 않고 들쑥날쑥 하겠죠!

그림 3.10의 그림을 보시면 가장 위의 판낼의 경우 상관관계가 존재하지 않는 오차 데이터를 선형 회귀 모델로 학습시킨 경우의 잔차들을 보여주고 있어요. 이 잔차들에는 시간 관련된 어떠한 추세도 보이지를 않습니다. 하지만 바닥의 판낼 잔차들은 인접한 오차들끼리 상관 계수가 0.9 정도 있죠. 그리고, 오차항의 상관 계수가 클수록, 인접 잔차들끼리 비슷한 값을 가지는걸 볼 수 있어요. 마지막으로 중앙의 판낼을 보시면 오차 상관계수가 0.5로 완만한 경우인데, 여기에도 눈에 띄지만 패턴이 덜한걸 볼수 있습니다.
시계열 데이터에 존재하는 오차항의 상관관계를 다루는 많은 방법들이 개발되어 있지만 오차항 사이의 상관관계는 당연히 시계열 데이터 이외에도 존재하죠. 예를 들면 개인의 키로 그 사람의 몸무게를 추정하는 연구를 한다고 해봅시다. 만약 연구에 참여하는 사람들이 서로 같은 가족이거나 식단이 같거나, 같은 환경적인 요소에 노출된다고 하면 오차항끼리 상관관계를 갖지 않는다는 가정이 위반될 수 있겠죠.
일반적으로 오차는 상관관계를 갖지 않는다는 가정은 선형 회귀나 다른 통계적 학습 방법에서 매우 종요하며, 좋은 실험적 설계하기 위해서는 이런 상관관계의 위험을 제거시키는게 중요합니다.
3. 오차 항의 분산이 고정 되지 않았을 때(상수가 아닐때) Non constant Variance of Error Term
선형 회귀 모델에서 다른 중요한 가정은 오차 항은 상수값인 분산 Var($\epsilon_{i}$ = $\sigmia^{2}$)을 가져야 합니다. 선형 모델과 관련있는 표준 오차, 신뢰도 구간, 가설 검정들은 모두 이 가정을 따르고 있어요.
불행히도 오차항의 분산이 변하는 경우도 있습니다. 예를 들면 반응 변수의 값과 함께 오차 항의 분산이 증가하는 경우도 존재합니다. 한 경우에서는 오차들의 분산이 고정되지 않은 경향, 잔차 플롯에서 깔대기 모양으로 보이는 이분산성을 볼수가 있어요.

그림 3.11의 왼쪽 그림의 예시를 보시면 잔차들의 크기가 점점 증가하고 있는것을 볼수가 있어요. 이 문제를 만날때 한가지 해결 방법은 출력 Y를 log Y 나 $\sqrt{Y}$같은 함수로 변환시키면 됩니다. 이런 변환을 수행하면 Y의 값이 크게 줄어들어 등분산성을 줄일수가 있어요. 그림 3.11의 우측이 log Y 함수로 출력을 변한시켜 구한 잔차 플롯이에요. 이제서야 상수 분산 constanct variance 혹은 잔차의 분산이 변하지 않는걸 볼수가 있어요.
각 반응, 출력의 분산을 다루는 좋은 방법들이 몇가지가 또 있는데, 예를 들어 i번째 반응, 츌력이 가공하지 않은 관측치 $n_i$의 평균이라고 해요. 각각의 가공되지 않은 관측치들이 분샨 $sigma^{2}$이며 상관 관계를 갖지 않는다고 합시다. 그러면 이들의 평균, 즉 i번째 반응, 출력의 분산은 $\sigma^{2}_{i}$ = $\sigma^{2}$/ $n_i$가 되어 변할수 있죠(상수가 아니다).
이 문제를 해결할수 있는 간단한 방법은 가중화된 최소 제곱법 weighted least squares을 사용하여 모델을 학습 시키면 됩니다. 여기서 가중치를 역분산에 비례하도록 $w_{i}$ = $n_{i}$로 지정하면, 반응 변수의 분산 변동 상쉐되어 사라지게 되겠죠. 그리고 대부분의 선형 회귀 소프트웨어에서 이런 관측치에 대한 가중을 사용할수가 있습니다.
4. 아웃라이어 outliers
아웃 라이어는 예측한 모델로부터 아주 멀리 떨어진 $y_{i}$를 말합니다. 아웃라이어는 다양한 이유로 발생하는데, 데이터 관측 기록이 잘못됫다거나 심각한 노이즈가 발생하거나 그런 이유루요.

그림 3.12의 왼쪽 판낼의 빨간점(관측 20)이 전형적인 아웃라이엉요. 여기에 최소제곱 회귀로 구한 빨간 직선이 있는데, 파란 점선은 이 아웃라이어를 제거한 후에 구한 선이에요. 아웃라이어를 제거한 경우에는 최소 제곱 직선이 약간 변한걸 볼 수가 있는데, 경사도 크게 변하지 않고, 절편도 약간 줄어들었습니다. 이 경우는 아웃라이어가 최소 제곱법을 이용한 학습 과정에 큰 영향을 주지않는 경우에요.
하지만 아웃라이어가 최소 제곱 학습과정에서 큰 영향을 주지 않더라도, 다른 문제를 발생시킬수도 있습니다. 예를들어 아웃라이어가 회귀 모델에 포함되어있을때 RSE는 1.09가 되며, 제거된 경우에는 0.77밖에 되지 않습니다. 이는 RSE가 모든 신뢰 구간과 p value 등을 고려하여 계산하기 때문인데 하나의 데이터 만으로도 큰 상승이 발생하고, 학습 결과를 분석하는데 영향을 줄수가 있어요. 비슷하게 $R^{2}$도 0.892에서 0.805으로 줄어들었습니다.
잔차 플롯을 이용하면 아웃라이어를 쉽게 식별할수 있습니다. 예를 들면 그림 3.12의 중간 판낼에서 잔차 플롯을 쉽게 볼수 있어요. 하지만 현실에서는 한 점을 아웃라이어로 판단하기 전에 얼마나 많은 잔차들이 필요할지부터 정하는것 부터 어려워요. 이 문제를 해결하기 위해 잔차들을 그대롤 플로팅하기 보다는, 스튜던트화된 잔차를 플롯시킬수 있습니다. 이 스튜던트화된 잔차 값들은 각 잔차 $e_{i}$를 추정된 표준 오차로 나눠서 계산할수 있어요. 스튜던트화된 잔차들의 관측치가 3보다 크다면, 아웃라이어로 볼수 있게 됩니다. 그림 3.12의 우측 판낼을 보면 아웃라이어의 경우 스튜던트화된 잔차가 6을 넘기고 있죠. 반면에 다른 관측치들은 -2와 2사이에 있습니다.
우리들이 아웃라이어가 데이터 수집이나 측정과정에서의 에러 때문에 발생한다고 생각하면, 해당 관측치를 제거하면되니 해결하기는 쉽습니다. 하지만 입력 변수 중 하나로 모델링하지 못해 놓쳣거나, 모델의 부족한 부분을 알려주는 값들일수 있다보니 조심히 다루어야 합니다.
5. 아주 강한/래버리지가 큰 데이터들 High leverage point
방금 $x_{i}$가 주어질때 나오는 흔치 않은 출력 $y_{i}$인 아웃라이어를 봤습니다. 하지만 아웃라이어 말고도 특이한 값을 가지는 래버리지가 큰(모델을 크게 바꿀수 있는) 관측치도 존재해요.

예를들어 그림 3.13의 좌측 패널에서 관측치 41번은 매우 큰 래버리지를 가지고 있습니다. (그림 3.13의 데이터들은 그림 3.12의 것과 동일하지만 래버리지가 큰 관측치 하나만 추가하였습니다.) 빨간 직선은 최소제곱법으로 학습한 것이고, 파란색 점선은 41번 관측치를 제거한 후 모델을 보여주고 있습니다. 그림 3.12와 그림 3.13의 좌측 모델을 비교해보면 래버리지가 큰 관측치를 제거하는게 아웃라이어보다 큰 영향을 주는걸 확인할 수 있어요.
래버리지가 큰 관측치는 추정 회귀선에 많은 영향을 끼치는데, 최소 제곱 직선이 이런 관측치들의 영향을 크게 받는다면 일부 데이터때문에 전체 학습이 엉망이 될수 있어 주의하여야 합니다. 그렇다보니 래버리지가 큰 관측치를 찾는게 중요한 일이에요.
단순 선형 회귀에서 래버리지가 큰 데이터는 찾기 쉽습니다. 그저 일반적인 관측치 범위 밖에 있는지 확인하면 되거든요. 하지만 다중 선형 회귀에선 입력 변수가 많다보니 래버리지가 큰 관측치가 개별 입력 변수의 값 범위에는 잘 들어가더라도 데이터셋 전체적으로는 그렇지 않을수도 있습니다.
예를 들면 그림 3.13의 중앙 판낼을 봅시다. 입력 변수가 2개인경우인데, 대부분의 관측된 입력값들이 파란색 점 타원 안에 들어가요. 하지만 빨간색 관측치는 이 범위 밖에 나와있습니다. 하지만 $X_{1}$에도 $X_{2}$에도 속하지 않아요. 만약 여러분이 $X_{1}$혹은 $X_{2}$ 한쪽으로만 봤다면, 이게 래버리지가 높은 데이터인지 찾지 못했을 거에요. 이게 입력 변수가 많은 다중 회귀일 수록 더 어려워 집니다. 데이터의 모든 차원을 동시에 플롯 시킬 쉬운 방법이 없거든요.
그래서 관측치의 래버리지 정도를 수치화하기 위한 방법으로 래버리지 통계량 leverage statistic을 계산하면 됩니다. 이 통계량의 값이 크다면 해당 관측치는 래버리지가 크다는 얘기겠죠. 단순 선형 회귀 모델은 아래와 같아요,

$h_{i}$는 $x_{i}$가 $\bar{x}$로부터 멀면 멀수록 증가하니까 이 방정식을 보면 명확하죠. 그리고 이 $h_{i}$를 입력 변수가 여러개인 경우로 확장한 예시도 있는데, 여기다가 공식은 안올릴게요. 일단 레버리지 통계량 $h_{i}$는 항상 1/n ~ 1사이의 값이 되고, 모든 관측치의 평균 래버리지는 (p + 1)/n가 됩니다. 그래서 주어진 관측치의 래버리지 통계량이 (p + 1)/n을 초과한다면, 래버리지가 큰 데이터가 아닌지 의심해야 합니다.
그림 3.13의 우측 판낼은 좌측 판낼의 데이터로부터 스튜던트화된 잔차와 $h_{i}$의 플롯을 보여주고 있어요.41번 관측치가 큰 래버리지 통계량을 가질 뿐만아니라 높은 스튜던트화 잔차도 가지고 있죠. 다시 말하자면 이 관측치는 아웃라이어인데다가 래버리지가 큰 데이터입니다. 그래서 이 데이터를 포함시키는건 위험할 수 있어요. 그리고 이 그림을 보면 관측치 20번이 래버리지가 낮다보니 최소제곱 적합에 큰 영향을 주지않는걸 알수 있겠습니다.
6. 공선성 collinearity

공선성은 두 입력 변수가 서로 강하게 상관관계를 가지고 있는 경우를 말합니다. 그림 3.14의 신용카드 데이터셋에서 공선성의 개념을 볼수 있는데, 그림 3.14의 두 입력변수 나이와 한도에는 명확한 관계가 존재하지 않습니다. 하지만 우측 판낼에서는 한도와 신용 평가 사이에 강한 상관관계가 존재하는것을 볼수있는데 이게 다중공선성을 가지고있다고 할수있겠습니다.
공선성은 회귀 시에 문제를 발생시키는데 왜냐면 공선성을 가진 변수들을 따로따로 분리해내기가 힘들거든요. 다시말하면 평가와 한도는 같이 증가하거나 같이 감소하다보니, 따로따로 출력 변수 채무 잔액에 얼마나 연관성을 가지고있는지 판별하기가 어렵습니다.

그림 3.15는 공선성으로 발생할수있는 어려운 점들을 보여주고 있어요. 그림 3.15의 왼쪽 판낼에는 한도와 나이 사이의 채무 잔액에 대한 회귀 계수 추정들과 이 계수에 대한 (3.22) RSS를 윤곽선 플롯으로 보여주고 있어요. 각 타원들은 해당 계수일때 같은 RSS 값을 가진다는 의미이고, 중앙에 가까운 타원일수록 RSS가 작아지고 있습니다. 검은 점과 이 점에 대한 점선은 RSS가 최저가 되는 계수 추정치를 나타내고 있어요.
한도와 나이에 대한 축은 표준 오차를 고려하여 최소 제곱 추정으로 나올수 있는 추정량들로, 이 플롯이 모두 계수가 될수 있는 값의 경우를 포함시키고 있다고 봐도 되요. 지금 보시는 경우에는 실제 한도 계수가 0.15와 0.20 사이에 있다고볼수 있겠죠.
하지만 그림 3.15의 오른쪽 판낼에는 (강한 공선성을 가진) 한도와 신용 평가 사이 채무 잔액에 대한 회귀 모델의 가능한 계수 추정량들과 그에대한 RSS를 보여주고 있습니다. 윤곽선이 아주 좁은 계곡 처럼 생겼는데, 계수 추장치로 구한 RSS 값의 범위가 매우 넓은걸 볼수 있어요. 그래서 이 데이터가 조금만 변하더라도 계수 추정량이 이 계곡의 어딘가로 이동하게 될겁니다. 그 결과 계수 추정에서 불확실성이 커지게 되요. 여기를 보시면 한도 계수가 -0.2에서 0.2까지 스케일이 나오고 있는데, 한도와 나이제한 모델에서 한도의 계수보다 10배 이상 증가한 샘이죠.
놀랍게도 한도와 신용 평가 계수가 더 큰 불확실성을 가지고 있더라도, 추정한 계수들이 이 계곡의 어딘가 있다는 점이에요. 따로 따로 보면 각 계수가 옳더라도 이 윤곽선 플롯에 따라 우리는 실제 한도 -0.1 그리고 신용 평가 계수가 1은 인 경우는 존재하지 않는다고 볼수 있습니다.

공선성이 회귀 계수 추정량의 정확도를 떨어트리기 때문에 $\widehat{\beta}_{j}$의 표준 오차가 커지게 됩니다. 한번 각 변수의 t통계량이 $\widehat{\beta}_{j}$를 표준오차로 나눠서 구했던걸 떠올려봅시다. 표준 오차가 커지는 만큼 t 통계량은 줄어들갰죠. 그 결과 공선성의 존재로 인해 귀무 가설 $H_{0}$ : $\beta_{j}$ = 0이라는 귀무가설을 기각하지 못하게 될수 있습니다. 이는 가설 검정의 검증력 the power of the hypothesis test(올바르게 0이 아닌 계수를 추정할 확률)가 다중공선성때문에 떨어진다고 볼 수 있어요.
표 3.11은 두 다중 회귀 모델로 얻은 계수 추정량을 비교하고 있습니다. 첫번째 모델은 나이와 한도에 대한 채무 잔액의 회귀 모델이고, 둘째는 신용 평가와 한도에 대한 채무 잔액의 회귀 모델이에요. 첫째 회귀 모델에서는 나이와 한도 둘다 p value가 매우 낮아 유의미한 변수로 보고 있어요.
둘때 모델의 경우 한도와 신영 평가사이 다중공선성이 존재하여 한도 계수 추정량의 표준 오차가 (모델 1 한도의 표준 오차보다)12배 정도 증가하였고, p value는 0.701로 증가하였습니다. 다시 말하자면 한도 변수의 중요도가 다중공선성 때문에 가려지게 됩니다(maked). 그래서 이 상황을 피하기 위해서 모델을 학습하는 중에 공선성 문제가 잠재적으로 존재하는지 파악하고 이를 다루어야 합니다.
공선성을 찾아내는 쉬운 방법은 입력 변수의 상관계수 행렬을 보면 되요. 이 행렬의 한 원소 값이 항당히 크다면 해당 변수들은 강한 상관관계를 가지고 있다고 볼수 있습니다. 불행이도 공선성은 상관계수 행렬만으로는 전부 파악하기는 어렵습니다. 왜냐면 두 변수의 쌍이 높은 상관관계를 갖지 않더라도 3개 혹은 그이상의 변수들사이에 존재할수도 있거든요. 이걸 다중공선성 collinearity이라고 부릅니다.
그래서 상관 계수 행렬을 보기보다 다중공선성을 파악하는 더 나은 방법은 분산 팽창 지수 Varaicne Inflation Factor(VIF)를 계산하면 됩니다. VIF는 $\widehat{\beta}_{j}$의 분산의 비율이며 VIF에서 가장 낮은 값은 1로, 이 경우 다중 공선성이 존재하지 않게 되요. 하지만 현실에서 입력변수들은 약간씩의 공선성을 가지고 있어요. 원칙적으로 VIF가 5 ~ 10을 넘는다면 공선성의 위험이 있다고 볼수 있겠습니다.
각 변수에 대한 VIF는 아래의 공식으로 구할 수 있어요.
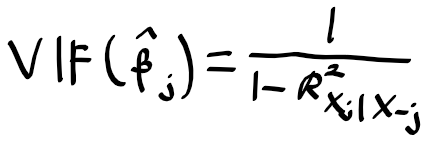
여기서 $R^{2}_{X_{j} | X_{-j}}$는 다른 모든 입력 변수로 $X_{j}$를 회귀 시킨 모델의 $R^{2}$인데, $R^{2}_{X_{j} | X_{-j}}$가 1에 가깝다면 공선성이 존재하게 되는 것이고, VIF는 엄청 커지겟죠.
신용 카드 데이터셋에서 나이, 신용평가, 한도의 채무 잔액에 대한 회귀 모델을 구하면 VIF는 1.01, 160.67, 160.59로 이 데이터에 상당히 큰 공선성이 존재하는걸 알 수 있어요.
이런 공선성 문제가 생길때 간단한 해결방법으로 두가지가 있습니다. 첫째는 문제가 발생하는 변수를 회귀 모델에서 제거하면 됩니다. 어짜피 공선성을 가진 다른 변수가 제거한 변수의 정보를 가지고 있기 때문에 크게 고민하지 않고 제거해도 괜찬아요.
예를들면 신용 평가에 대한 변수 없이 나이와 신용 평가의 채무 한도에 대한 회귀 모델을 만든다면 VIF는 1에 가까워 지고, $R^{2}$는 0.754에서 0.75까지 떨어질거에요. 신용 평가 변수를 제거하는것으로 공선성을 효과적으로 제거할수 있겠습니다.
'번역 > 통계적학습법개론' 카테고리의 다른 글
| [통계기반학습개론] 4. 분류 Classification 와 로지스틱회귀모델 (0) | 2021.02.19 |
|---|---|
| [통계기반학습개론] 3.4 마케팅 전략/3.5 KNN과 선형 회귀 모델 비교 (0) | 2021.02.06 |
| [통계기반학습개론] 3.2 다중 선형 회귀 Multiple Linear Regression (0) | 2021.01.31 |
| [통계기반학습개론] 3. 선형 회귀 Linear Regression (0) | 2021.01.30 |
| [통계기반학습개론] 2.1.5 회귀 문제와 분류 문제 (0) | 2021.01.28 |