최근 딥러닝 공부를 하면서 합성곱 신경망에 대한 전반적인 이론들을 살펴보았고, 최근 자연어 처리를 위한 순환 신경망에 대해서 정리해보고 있다. 하지만 합성곱 신경망의 경우에는 예전부터 조금씩 본적이 있었지만, 순환 신경망의 경우 합성곱 신경망 만큼 친숙한 개념이 아니어선지 생각보다 진도 나가기가 너무 힘들더라.
분명 지지난주 신경망 학습 방법들에 대해서 정리할때 까지만 해도 지금 보다는 의역이 잘 되는 편이었는데, 여기서 설명하는 로직이 잘 이해가 되지 않아서인가 의역이 제대로 되지도 않고 진행 속도가 크게 느려졌다. 그나마 다행인 점은 그동안 너무 하기 싫고 힘들었던 순환 신경망이 많이 늦어지기는 했지만 조금씩 조금씩 본 덕에 조금은 이해는 됬고, 정리하는 속도도 아주 약간은 빨라진것 같다.
하지만 이 부분에서 전에 진행하던 속도보나 너무 늦춰지다보니 시간을 너무 많이 지체해버리긴 했다. 다른 공부도 같이 병행을 하기는 해야하지만. 지금 딥러닝 이론에 나오는 내용들이 다양한 논문들에 나온 방법들을 정리한 것이기도 하고, 그렇다고 딥러닝 실습을 하자니 이런 내용을 이해하지 않고서는 왜 딥러닝 프레임워크로 신경망 모델링을 그런식으로 하는지 알수가 없으니 이 부분은 짚고 넘어갈수 밖에 없다고 생각한다.
한 강의만 가지고 몇일, 한두주씩 시간을 낭비해버리고 있으면서 차라리 다른 사람이 정리한걸 참고하면 되지 않나 생각도 들기는 하지만 괜한 고집 때문인지, 혼자서 이걸 해내고 싶어선지 남의 것을 보고 넘어가고 싶지는 않다. 분명 내것 보다 훨씬 정리 잘한 사람도 많기는 하지만, 내가 억지로 붙들고 이해하려고해서 살펴본것과 남이 이쁘게 정리한걸 보는것과 공부하는데서 느낌도 다르고..
과하게 시간을 낭비하는것 같긴한데, 아닐수도 있고 마음 먹기 나름인 문제이긴 하지만 너무 편한 환경에 놓은게 가장 큰 것 같다.
이번 주에는 그래도 설 연휴 쉬고난 직후였던 지난 주보다는 마음 잡고 조금은 더 많이 할 수 있었다.
통계적 학습 기법
이번 주 동안에는 분류 문제를 다루는 다양한 통계적 학습 기법을 살펴봤는데 대표적으로 로지스틱 회귀 모델과 선형 판별 분석, 그리고 이차 판별분석 등을 살펴 봤었고, 다양한 시나리오 그러니까 데이터들이 어떤 특성을 보이는지 분포가 어떻게 되는지와 같은 상황에 따라 비모수적 분류 모델인 KNN 분류기를 포함하여 각 방법들이 어떤 특성과 성능을 보이는지 정리할 수 있었다.
이 외에는 뭐더라.. 그 리샘플링 방법에 대해서 간단히 살펴봤는데, 대표적인 리샘플링 방법인 교차 검증이나 부트스트랩 같은 방법에 앞서 가장 간단한 방법인 홀드 아웃에 대해서 살펴보면서 일단 통계적 학습 기법을 마무리하였다. 이번 주중으로 챕터 5장은 마무리 해야지
컴퓨터 비전을 위한 딥러닝
다음으로 컴퓨터 비전을 위한 딥러닝의 경우 이번주 초에는 상당히 고생을 했었다 1시간 짜리 영어 강의를 이해하기 위해서 번역을 하면서 정리를하는데 강의 하나를정리하는데 순수하게 8 ~ 12시간 쯤 걸리는것 같다. 왜냐면 직독 직해가 가능한 간단한 표현들도 존재하지만 특히 이론적인 동작 원리를 설명하는 부분에서 직독 직해가 안될 때가 많고, 이게 실제 강의한 내용들을 정리하다 보니 구어체적인 표현들이 내가 배웠던 영어 문법과 맞지 않아 교수님이 문법을 엉터리로 하구나?라고 생각이 들기도 했었다. 사실 내가 다양한 표현들을 제대로 공부안해서 모르는거기도 하지만
하지만 내가 이 강의를 정리할 때 가장 큰 문제는 표현들을 모르는것도 있지만 너무 직역을 하려고 하고 있었더라 적당히 의역을 해야하는데, 나도 모르는세 한단어 한단어 의미를 바꿔가면서 하려고하다보니 시간도 오래걸리고 말도 덜 자연스러웠다. 거기다가 내가 이해하지 못하는 부분이 생기면 따로 검색을 하거나 파파고 번역기도 돌려보고 어떻게 하면 이걸 정리할수 있을까 삽질하느라 시간이 너무 소모가되고 붙잡고할 맨탈도 너무 무너졌었다.
그런 이유로 어떻게 하면 리딩을 잘 할수 있을가 검색하다가보니 내 문제는 리딩 보다는 분명 아는 단어들인데 왜 해석을 해도 이해가 안되는 말들이 나오는지가 문제였고, 이에 대한 유튜브 검색을 하다가 내가 의역을 잘 하지 않는다는걸 알게되었다. 그 덕분에 이후에는 교수님이 문법에 맞지 않는 단어들을 사용한다 해도 거기에 큰 의미를 두지 않고 나름대로 의역을 하려고 신경 쓴 덕분에 이전 보다는 내용을 정리하는데 약간은 시간이 더 빨라진것 같았다.
그리고 이전까지는 PPT에다가 정리를 해왔었는데 이걸 정리하는데 낭비하는 시간이 너무 많아서 아예 블로그에다가 올리고 있고, 지난번에 다 못뽯었던 신경망을 잘 학습시키기 위해서 학습전에 설정해야 할것들, 활성화 함수, 데이터 전처리, 가중치 초기화, 규제 방법들에 대해서 전체적으로 살펴 볼수 있었다. 또 다음 강의에서는 신경망을 잘 학습하기위해서 알아야 할 것들 중에 가중치 감쇄에 관한 내용들을 살펴 보았다.
기타
이 외에는 알고리즘 공부를 하던중 이번에는 그래프에 대해서 정리해보았다. 이전부터 SLAM에 대해 관심을 가져오다보니 그래프에 대해서 제대로 공부를 하고 싶어했었는데, 오랜만에 그동안 공부했던 내용들을 한번에 다 정리해볼 수 있었다.
간단하게 그래프가 무엇인지 어떻게 생겼는지, 그리고 그래프를 어떻게 표기를 할수 있는지, 그래프에 대한 종류, 그래프를 저장하는 방법과 그래프의 사용 예시까지 우선 첫번째 글에서 다루었고
그 다음으로는 그래프 이론에 대한 배경 쾨니히스베르크의 다리 이야기에서 부터 시작하였다. 쾨니히스베르크의 다리, 해밀턴 경로, 외판원 문제 TSP에 대해서 살펴보면서 TSP가 NP-완전 문제였는데, 이전 부터 도대체 NP-완전이 뭔지 NP가 뭔지 감이 잘 잡히지를 않았었다
그렇다보니 이번에 이 개념들을 한번 정리해보자 해서 NP에 대한 글을 찾아봤고, NP가 비결정론적 튜링머신으로 다항식 시간에 풀수 있는 문제라는걸 알게 되어 그러면 튜링 머신이 뭔지 비결정론적인 튜링 머신이랑 뭐가 다른지를 그리고 다항시간이 뭔지 등을 나오는 개념들 중에서 내가 NP-완전이라는 단어를 한번에 정리할수 있을 만큼 모르는 개념들을 계속 파고파고 들어갔다.
그 덕분에 튜링 머신이 무엇인지, 추상 기계의 한 종류이며 사고 실험을 하는데 사용하는 것인걸 알 수 있었고, 비결정론적인 튜링머신이란게 튜링 머신이 한번의 상태에 대한 연산만 가능했다면 아무것도 안하거나 여러가지를 동시에 할수 있는 튜링머신이란걸 알수 있었고 실제로 구현을 할수가 없어 비결정론적인 튜링 머신으로 풀수 있는 문제들은 정확한 해를 구하지 못하고 근사적인 방법으로 푼다는 것을 알 수 있었다.
이 외에도 이러한 개념들이 계산 이론, 계산 복잡도 이론에 관한 것이다 보니 결국에 계산 복잡도 이론이 현실에 존재하는 수 많은 문제들을 다양한 복잡도를 기준으로 분류하기 위한 문제 집합에 대한 연구 분야라는걸 알 수 있었고 EXPSPACE, EXPTIME, PSPACE, PTIME, NP 등과 같은 용어들이 문제 집합이라는것을 알 수 있었다. 그래서 대략적인 NP완전에 대한 개념들을 이애 할 수 있었다.
마지막으로는 그래프를 이용한 탐색 방법이 어떤것들이 있는지 DFS, BFS가 있는지를 간단하게 보고, 백트래킹이 무엇인지 보고 제약 충족문제 CSP가 어떤것들이 있는지 살펴보면서 마무리할수 있었다.
전에는 거의 매일 영어 로그도 쓰고, 막 뭔가 열심히 했던거 같은데 다시 전처럼 하기가 쉽지 않다.
오는 주에는 이전 페이스를 되찾으려고 좀 노력해야할거 같다.
이전에 내가 생각하던 목표는 매주 논문도 읽고, 영어 공부도 하고, 통계/딥러닝도 같이 공부하려고는 했지만 딥러닝 정리할떄 까지만 했어도 할만 했지만 통계 정리가 추가되는 순간부터 쉴시간이 전혀 없어지니 계획대로 하기가 너무 힘들더라
그래서 글을 남기지는 못했는데 어짜피 딥러닝, 통계 이론들이 다 논문에서 나온거니 굳이 논문을 읽을 필요가 있나? 싶더라. 지난 주말에 내가 정리한 신경망 아키텍처에 관한 강의에만 해도 제대로 본 신경망 아키텍처만 AlexNet, ZFNet, VGG, GoogLeNet, ResNet 5개 정도를 봤고, 그 외에도 간단하게나마 ResNext, SENet, MobileNet, Network Architecture Search 까지 볼수 있었으니 이 강의에 논문 여러개가 정리 되어 있으니 말이다. 추가 논문 보는건 이 강의 모든 내용을 정리하고 여유가 생길때 보는게 좋을것 같다.
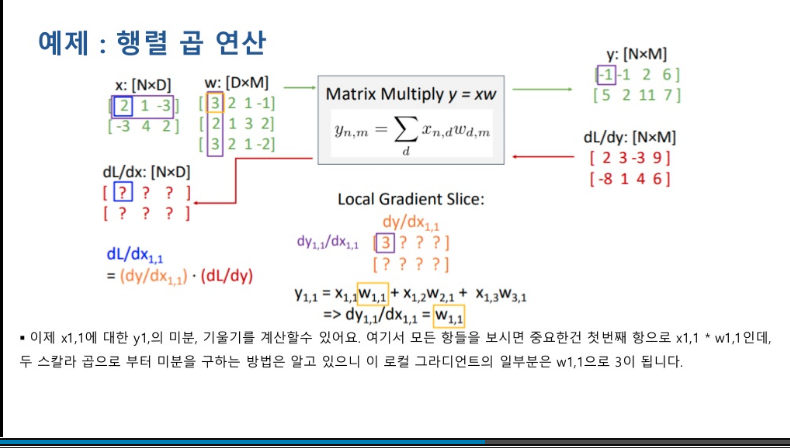
추가로 딥러닝에 관해 매주 문제를 몇 개씩 만들고 있었는데, 이런 문제를 만들면서 내가 이전에 몰랐던 내용들을 한번 더 다시 정리하면서 많이 도움이 되는걸 느끼고 있다. 특히 이번주에 5문제를 만들면서 sigmoid와 tanh를쓰다가 왜 relu를 사용하게 되었는지 그리고 reaky relu인가 이 함수를 왜쓰게 되었는지 이해한 점이나 드랍 아웃과 internal covariate shift에 대한 개념을 다시 살펴보면서 조금더 명확히 이해되어 많이 도움되었다.
영어 공부도 도저히 할 여력이 없어서 별도로 시간 내서 하는 대신 밖에 나갈 때 마다 BBC 라디오를 들으며 돌아다니고 있다. 확실히 라디오가 듣기 좋은게 유튜브에서 올라오는 공부 영상은 듣기 너무 쉽거나, 듣기 너무 힘든게 많더라 특히 드라마가 문화적인 표현도 많고 발음도 듣기 힘들었다. 하지만 라디오 같은 경우에는 다양한 인종 사람들이 나오고 이런걸 고려해선지 발음이 훨씬 듣기는 수월하더라.
그래서 꾸준히 BBC 라디오를 듣고 있는데 처음 들었을때 말의 6~70%가 그냥 흘러가거나 잘 안들렸다면 지금은 3~40% 정도로 줄어들어 이해를 하고 안하고를 떠나서 편하게 들리는 정도가, 청취력이 많이 늘어난것 같아 다행이다. 만약 계속 유튜브에 어려운 영어 공부 드라마 같은거를 틀어 놓고 보려 했으면, 쉽게 쉽게 하다가 가끔식 어려운걸 해야지 라디오에서 거의 사용하지도 않는 어려운 표현들을 연달아서 들었으면 진작에 포기해버렸을거같다.
이번 주에는 전보다 제대로 공부하지 못한것 같다. 통계 스터디를 참여하게 되었는데 목요일날 처음 참여하고, 이번주 부터는 월요일에 하다보니 주말에 다른걸 못하고 통계 정리를 급하게 먼저 하는 바람에, 딥러닝도 절반 조금 안되는 내용을 정리하기는 했다만은 지난주 보다 시간을 써야 하게 되었다.
지난주 목요일에는 통계적 학습 기법이 어떤것들이 있었는지 봤다면 이번 주 월요일에는 선형 회귀 모델에 대해 보다보니 단순 선형 회귀, 다중 선형 회귀, 분산과 편향 트레이드오프, 변수 선택, MSE, 선형 회귀 평가를 위한 RSE나 R2같은 것들을 보았다. 그래서 이걸 하느라 토요일 대부분 시간을 쓰고
https://throwexception.tistory.com/1158
일요일에는 딥러닝에 대해서 정리하는데, 이번에는 주제가 역전파였다. 그동안 선형 분류기가 어떤 관점들로 볼수 있고, 최적화 기법이 어떤게 있고, 신경망이 어떻게 구성되는지 등을 보았고 이 신경망의 전체 파라미터를 학습시키는 벙법인 역전파에 대해서 보았는데, 계산 그래프 부터 스칼라 값에 따른 그라디언트, 벡터에 따른 그라디언트, 텐서에 대한 그라디언트, 그리고 순방향 미분 자동 계산과 역방향 미분 자동 계산 등 내용들이 너무 많더라 그래서 월요일에는 절반 조금 안되게 정리를 하였고 나머지 내용을 하는데 수요일 까지 해버리고 말았다. 계속 밀려지니 하기 싫어지더라
https://throwexception.tistory.com/1161
원래는 딥러닝 내용만 정리해도 주말을 다 써버리는데 통계까지 해버리니 정말 쉴 시간이 없었다 그렇다고 통계 내용이 머신러닝 모델 설계가 어떻게 되는지, 변수들이 어떻게 출력에 영향을 주는지, 모델 설계하는지등을 파악하면서 이게 너무 유익하다보니 안할수도 없고, 그래서 원래는 리트 코드에서 프로그래밍 공부도 하기는 했지만 이제는 자료 구조 내용위주로 하고, 넌센스 문제는 시간 낭비인것 같아 가능한 안하려고 한다.
이런 일로 영어 공부도 제대로 못하고 있었다. 그런데 요즘 영어 쓰기는 문법 어휘가 엉터리더라도 쓰는게 많이 편안해졌고, 프렌즈처럼 너무 미국적인 내용들을 보면 잘 알아듣지 못할때가 많으나 밖에 나갈때마다 BBC 뉴스를 틀어놓고 돌아다닌다. 그런데 이걸 계속 듣고 있어선지 그동안 놓치던 단어들이 조금씩 들리기 시작하게 되더라. 특히 수요일날 외출하면서 오랜 시간 뉴스 라디오를 들으면서 직독 직해까지는 아니더라도 러시아 시위가 어떻게 되어가는지 신장에서 어떤일이 일어나는지 같은 내용이 나오는데 그게 조금식 이해하기가 시작했다.
또한 정신없이 금요일이 되어버렸고 여전히 많이 햇갈리지만 영어 정리 하는 과정이 전보다는 조금 자연스러워 지고, 이해 안가던 표현들이 이해가기 시작한것 같아서 조금 위안이 된다.
어제는 캐글 집값 예측 대회에 참여하면서 삽질을 좀 많이 했는데, 책에서 보여주는 스태킹 기법을 사용하려고 했지만 삽질하는 과정에 중간에 있는 코드들이 스파게티가 되어선지 맨 마지막에 넣은 스태킹 모델이 정상적으로 동작하는것 같지 않더라, 기본 모델도 뭔가 이상했다.
그래서 원래 쓰던 엉망이 된 코드를 버리고, 다시 처음부터 시작해서 디폴트 회귀모델이 집값을 잘 예측하는걸 확인하고, 파라미터 튜닝 과정을 거쳤다. 파라미터 튜닝 과정을 통해서 분명 성능이 향상도 시키고, 베이스라인 모델에서 사용하는 전체 모델의 평균 회귀 값을 이용하는 평균 모델을 만들어 사용했으나 베이스라인의 모델과 거의 비슷한, 크게 성능이 향상되지 않은 모델이 만들어 지고 말았다.
전부터 이해가 안가던게 데이터 분포가 치우쳐진 경우 왜도가 있는 경우, 로그 변환을하면 정규 분포에 가까운 형태로 바꾸면 성능이 개선된다고 한다. 그런데 실제로 로그 변환을 수행후 앙상블 모델에 적용시키면 오히려 오차가 증가해 버리더라. 내가 이해한건 데이터의 분포가 정규 분포가 따라야 성능이 개선되는것은 그 추정 모델의 오차가 정규성을 가지는 경우, 선형 회귀 모델갖이 회귀선을 중심으로 데이터가 일정하게 분포한 경우 성능이 개선되는것이지, 그런 방식이 아니라 결정 규칙을 만들어 나누어 가는 트리 기반 방법들에는 성능 개선이 안되는 것으로 알고 있다.
내가 잘못이해하고 있는건지 잘 모르겟다. 아무튼 오늘부터 주말까지 통계, 딥러닝도 잘 정리하고, 정말 논문 리뷰 할 시간이 남았으면 좋겠다ㅠㅜ
unfortunately, yesterday, i was too tired to write anything and just fall in a sleep at a night. becaus i went to the hospital and the other place because of meeting reservation. altough i did hang around a long time, you know i did work out well, got exhauseted too much. nevertheless, i did tried to watch any video and seaching anything. i found one, altough i didn't want to watch learning english with blabla, there was shipsons! i was about to watch that, but fall in a sleep.
so, i could wake up ealry in this morning. then i tried to do my homework behinds me. i finished one as soon as possible, there are many things i didn't. plus, i have to participated in kaggle competition and i need to minimize rmse root mean squared error of the dataset, i tried all of thing i know but i'm not professional in kaggle, and my technique and comprehension about it was poor. that't really frustrating me despite of my hardship. i know i just see it and typing. then that looks like working well, and i passed it. but i did several times it but my comprehension is not better as much as i wish.
i coun't be depressed, should stand it. i spend all of times to do ti, after submit my prediction result, there are some lower bound i have to minimized my prediction rmse less than. that was big problem for me. i made a default estimators like random forest, gradient boosting, xgb, and made some stacking models. but my stacking models doesn't seems like working, and output was something wrong. so, i abandon it. instead, i try to used average model in base line. fortunately, the average model are working well. and i tuned hyper parameters of the models, and mixed up that models, my models become imporved.
neverthese, my average model's rmse did not reach to the bound but it could be very closer at that. anyway, today i was about to practice some writing using a english book that i borrowd, but i don't have any more time for that. so i wish i can write my dialog tomorrow too.