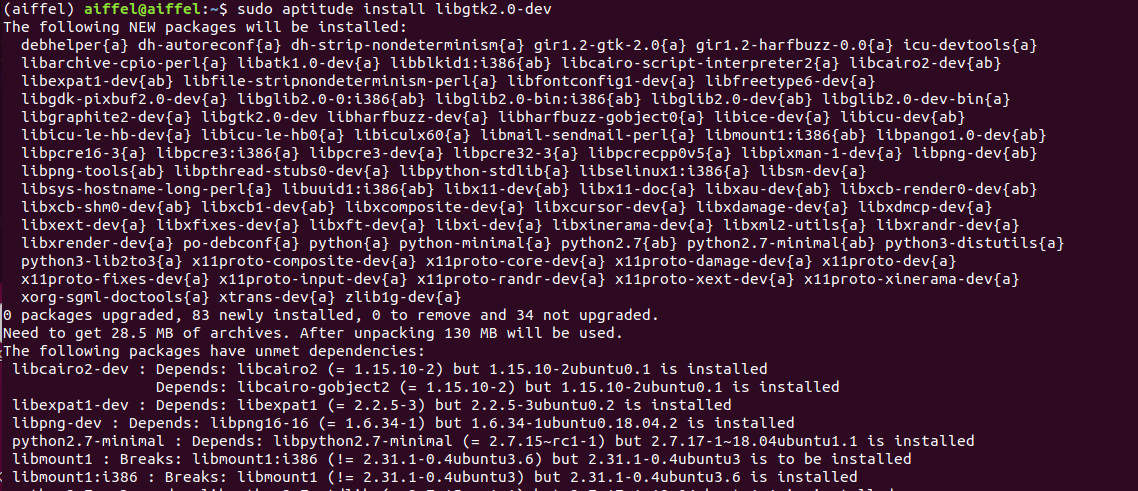
이번 시간에는 잔차 블록을 통해 훨씬 깊게 만들어진 신경망인 ResNet에 대한 논문을 정리해보고자 합니다. 매번 논문들을 번역하는 식으로만 공부했지만 이번에는 가능한 번역보다는 내용 흐름을 정리해보겠습니다.
1. 신경망의 층을 깊게 할 때 문제점.
1.1 신경망을 깊게 만드는 것의 중요성
우선 심층 합성곱 신경망은 이미지 분류 작업을 시발점으로 널리 사용되었는데요. 이런 심층 신경망은 저수준/중수준/고수준 특징들을 모아서, 분류기로 end-to-end 학습을 시키게 됩니다. 여기서 특징의 복잡도는 층의 깊이에 따라 다양해질수가 있어요.
1.2 깊은 신경망의 문제 1 : 그라디언트 폭증/소실과 정규화
그래서 신경망을 깊게 만드는건 중요하지만, 몇가지 문제가 발생하게 됩니다. 신경망 모델은 학습 과정에서 그라디언트로 기존의 파라미터들을 갱신하는데, 층이 깊어질수록 그라드언트가 사라지거나 폭증해서 최적의 파라미터를 찾도록 수렴하는걸 방해하거든요. 이 문제를 해결하기 위해서 파라미터를 정규화시켜 초기화 하거나 정규화 계층을 두어 풀수 있었습니다.
1.3 깊은 신경망의 문제 2 : 디그라데이션 degradation의 발생
정규화 방법을 통해서 깊은 신경망도 수렴할 수 있게 되었으나 디그레디에이션 문제가 생겼습니다. 신경망의 깊이가 증가할 수록 정확도가 포화/더 이상 올라가지 않고 빠르게 감소하되는 문제가 생깁니다. 이런 디그라데이션 문제는 K. He at el와 이 논문에서의 실험 결과 신경망 모델을 더 깊게 할수록 훈련 에러가 더 높게나온다는 점에서 오버피팅에 의한 것이 아닌걸 알 수 있었습니다.
* 오버 피팅의 경우 학습 데이터에 과하게 학습된 것인데, 깊은 신경망이 더 훈련 에러가 낮아야 하지만 얕은 신경망이 훈련 에러가 더 낮다는 점에서 오버피팅이 아니라고 할 수 있습니다.
그림 1. CIFAR-10 데이터셋을 이용한 20, 56 계층의 일반 신경망의 훈련 에러(좌측), 테스트 에러(우측). 깊은 신경망일수록 훈련과 테스트 에러 둘다 높은걸 볼 수 있습니다. ImageNet 데이터셋을 이용한 실험결과는 그림 4에서 볼수 있습니다.
1.4 깊은 신경망의 문제 3 : 층을 깊이 쌓는다고 디그라이데이션을 해결 하기 어렵다!
위 결과를 볼때 훈련 정확도의 저하, 디그라데이션 문제를 보면 모든 시스템들을 최적화 하기가 어렵다는 것을 알 수 있습니다. 얕은 신경망 아키텍처와 동일한 모델에 층을 추가해서 깊은 모델을 만들었다고 가정하면, 당연히 깊은 모델이 얕은 모델보다 훈련 에러율이 낮아야 할거에요. 하지만 위 실험 결과를 봤을때 단순히 층을 쌓는다고 해서 더 나은 결과가 나오지 않는 걸 알 수 있어요
----------------------------- 펌 내용 -----------------------------------
이번 시간에는 패키지 관리 툴들에 대해 조금~ 배워보는 시간을 갖도록 하겠습니다 ^^
우분투는 아는 사람은 알다시피... 데비안을 그 기반으로 하고 있습니다. 고로 프로그램의 설치는 .deb파일을 통해 패키지 형태로 이루어 집니다.
이런 .deb파일이나 패키지의 관리에 사용되는 툴에 대해 이해하고 이 툴들을 보다 유용하게 사용할 수 있기를 바라며 이번 강좌를 시작합니다
우분투를 설치한 후, 시스템의 사용목적이나 필요에 따라서 .deb 파일을 추가 설치 하거나 삭제 할 수 있다. .deb 확장자 파일은 데비안 패키지 파일로써 우분투가 데비안 기반으로 한 시스템이라 소프트웨어 설치에 .deb파일을 사용하는 것이다.
이러한 패키지 들은 패키지 툴을 이용하여 설치하게 되는데 패키지 툴에는 apt, dpkg, aptitude 가 있다. 그중 몇가지를 설명하자면...
APT 는 온라인 리포지토리에서 패키지를 다운로드받고 설치하는데 사용 된다( : 예> apt-get 패키지명) 이때 보통 로컬환경(오프라인)상에서도 사용할 수 있지만 정상적으로 사용하기 위해서는 온라인 환경에서 사용하여야 한다.
dpkg 는 Cd룸이나 다른 디스크장치에 있는 .deb 파일을 제어하는 경우에 일반적으로 사용되며, dpkg명령어는 시스템 소프트웨어에 대한 설정이나 설치 및 정보를 얻는데 사용되는 옵션을 가진다 (예:> dpkg -c 데비안패키지 – 패키지가 설치한 파일 목록보기)
패키지 툴에 대한 부분은 나중에 보다 자세하게 살펴보도록 하겠다.
우분투를 설치한 후 터미널 창을 열어 다음을 입력해보자
$ apt-cache stats
그러면 다음과 같은 결과를 얻을 수 있을 것이다.
전체 꾸러미 이름 : 33052 (1322k) 일반 꾸러미: 25280 순수 가상 꾸러미: 703 단일 가상 꾸러미: 1688 혼합 가상 꾸러미: 237 빠짐: 5144 개별 버전 전체: 30120 (1566k) ...
위 에서 보듯이 전체 30000여 개가 넘는 소프트웨 패키지를 사용할 수 있다.(공짜!로 쓸 수 있는 프로그램이 이리 많다는게 놀랍지 아니한가?)
그럼 본론으로 들어가서 각 패키지 툴을 이용한 소프트웨어 관리에 대해 배워보는 시간을 갖자.
1.APT 실질적으로 APT는 dpkg와 함께 동작한다. 하지만, 필요한 소프트웨어의 검색, 다운로드, 설치, 업그레이드, 검사 등 대부분의 패키지 관리작업을 APT단독으로 가능하다. 그럼 일반적 사용법을살펴보자
*주의: 다음 명령압에 sudo가 붙는데 sudo의 경우 우분투에서 사용하는 명령어에 관리자 권한을 주는 명령이다. 이는 우분투의 경우 기본적으로 root로 로그인을 막아 놓앗고 또 계정을 활성화 시켜놓지 않고 sudo 명령으로 root권한을 실행할 수 있도록만 만들어 놓았다. 그러므로써, 안전성을 확보하고 필요시 쉽게 root권한에 접근할 수 있도록 하고 있다. - 덫붙여 우분투를 사용할 때 꼭 필요한 경우가 아니면 root계정을 활성화하지 않는게 보안에 좋다. 다르게 말해 설치후 추가적으로root 패스워드를 지정해주지 않는게 보안에 좋다는 것이다.
sudo apt-get update : /etc/apt/sources.list를 참조로 사용할 수 있는 패키지 DB를 업데이트 한다.
apt-cache search 키워드 : 패키지 데이터베이스 중 주어진 키워드를 대소문자 구분 없이 검색하여 키워드를 포함하는 패키지명과 해당 설명을 출력한다.
sudo apt-get install 패키지명 : 패키지명을 데이터베이스에서 찾아보고 해당패키지를 다운로드 받아 설치한다. 이때, 패키지의 신뢰성을 gpg키를 사용 검증한다.
sudo apt-get -d install 패키지명 : 패키지를 설치는 하지 않고 /var/cache/apt/archives/ 디랙토리에 다운로드 받는다.
apt-cache show 패키지명 : 주어진 패키지명에 해당하는 소프트웨어에 대한 정보를 본다.
sudo apt-get upgrade : 설치 되어있는 모든 프로그램 패키지에 대한 최신 업데이트를 검사한 후, 다운로드 받아 설치한다.
sudo apt-get dist-upgrade : 전체 시스템을 새로운 버젼으로 업그레이드 한다. 이때 패키지 삭제도 실시된다. 단, 일반적으로 사용되는 업그레이드 방법은 아님!
sudo apt-get autoclean : 불안전하게 다운로드된 패키지나 오래된 패키지의 삭제.
sudo apt-get clean : 디스크 공간 확보를 위해 /var/cache/apt/archives/ 에 캐쉬된 모든 패키지 삭제
sudo apt-get 옵션 remove 패키지명 : 해당 패키지와 그 설정파일을 삭제한다. ( 옵션에 --purge 를 넣으면 설정파일을 재외하고 삭제. 옵션없을시 전부 삭제)
sudo apt-get -f install : 깨어진 패키지를 위해 정상여부를 확인
apt-config -V : 설치된 APT툴의 버전을 출력
sudo apt-key list : APT가 알고 있는 gpg키 목록의 출력
apt-cache stats : 설치된 모든 패키지에 대한 상태정보를 출력
apt-cache depends : 패키지가 설치되어 있는지 여부에 관계 없이 그 의존성을 출력한다.
apt-cache pkgnames : 시스템에 설치되어 있는 모든 패키지 목록을 보여준다.
이상으로 APT사용법을 대충 익혀보았다. 이제 dpkg를 알아보자
2.dpkg 이 툴의 경우 APT보다는 낮은 수준에서 작업이 수행된다. APT는 우분투의 소프트웨어를 관리하기 위해 내부적으로 이 dpkg를 이용한다. 보통 APT명령 만으로 충분하지만... 시스템에 있는 특정 파일이 어떤 패키지에 포함되는지 등의 확인 작업을 수행하기위해 dpkg 명령이 필요한 것이다.
dpkg -C .deb파일 : 주어진 .deb파일이 설치한 파일의 목록을 본다.(해당 파일이 있는 곳에서 실행하거나 파일명앞에 절대 경로를 붙여준다.)
dpkg -I .deb파일 : 주어진 .deb파일에 대한 정보를 본다.
dpkg -P 패키지명 : 패키지에 대한 정보를 보여준다.
dpkg -S 파일명 : 파일명 또는 경로가 포함된 패키지들을 검색한다.
dpkg -l : 설치된 패키지 목록을 보여준다.
dpkg -L 패키지명 : 이 패키지로부터 설치된 모든 파일목록을 볼수 있다.
dpkg -s 패키지명 : 주어진 패키지의 상태를 본다
sudo dpkg -i .deb파일 : 주어진 파일을 설치한다.
sudo dpkg -r 패키지명 : 시스템에서 해당 패키지를 상제한다. (단, 삭제시 파일들은 남겨둔다.)
sudo dpkg -P 패키지명 : 해당 패키지와 해당 패키지의 설정파일을 모두 삭제한다.
sudo dpkg -x .deb파일 디랙토리 : 파일에 포함되어있는 파일들을 지정된 디렉토리에 풀어놓는다. 단, 주의 할점은 이명령시 해당 디렉토리를 초기화 시켜버리므로 주의하여야 한다!
3. aptitude 앞에서 배운 dpkg와 APT의 경우 제대로 사용하기 위해서는 좀더 많은 지식을 요구한다. 그에 비하여 aptitude의 경우 주요 패키지 작업 과정을 자동화하여 가능한 쉽게 작업할 수 있도록 해주므로 보다 쉽게 할 수 있다. 고로 보다 많이 사용하게 될 것이... 옳지만... 아직은 인터넷 상에서 APT나 dpkg를 사용한 패키지 설치 정보가 많다는 점에서... 장래에 많이 사용하게 될 듯하다^^
sudo aptitude : 실행시 curses인터패이스로 시작된다. Ctrl+t를 사용하면 메뉴에 접근할 수 있으며, q키로 프로그램을 종료 시킬 수 있다.
aptitude help : 도움말 보기
aptitude search 키워드 : 해당 키워드와 일치하는 패키지를 보여준다.
sudo aptitude update : APT리포지트로들로부터 사용 가능한 패키지를 업데이트 한다.
sudo aptitude upgrade : 모든 패키지를 최신으로 업그레이드 한다.
aptitude show 패키지명 : 해당 패키지의 설치 여부에 관계 없이 주어진 패키지에 대한 정보를 보여준다.
sudo aptitude download 패키지명 : 해당 패키지를 설치하지는 않고 다운로드만 받는다
sudo aptitude clean : /var/cache/apt/archives디렉토리에 다운로드되어 있는 모든 .deb파일을 삭제한다.
sudo aptitude autoclean : /var/cache/apt/archives디렉토리에 있는 오래된 .deb파일을 전부 삭제한다.
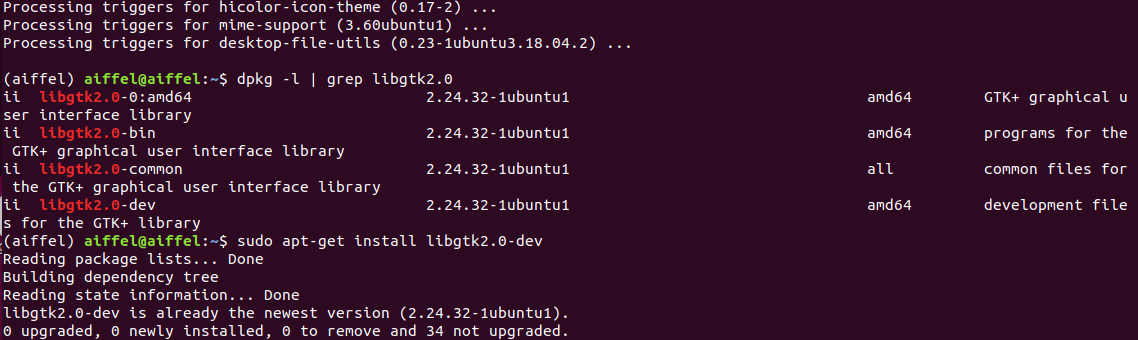
sudo aptitude install 패키지명 : 해당 패키지를 시스템에 설치한다.
sudo aptitude remove 패키지명 : 시스템으로부터 주어진 패키지를 삭제 한다.
sudo aptitude dist-upgrade : 모든 패키지를 가장 최신 버전으로 업그레이드 시킨다. 이때, 필요한 경우 패키지를 삭제하거나 추가 한다.
이상으로 패키지에 대해서 수박 겉할기 식으로 나마 알아 보았고, 특히 이들 패키지를 설치하거나 관리하기 위한 몇가지 방법을 알아보았다.
참고로, 위 내용 다 넘기고 요즘 우분투의 경우 '프로그램 > 추가/제거' 메뉴나 '시스템 > 관리 > 스넵틱스관리자' 에서 쉽게 패키지를 선택하고 설치하거나 삭제 할 수 있다. 아니면 .deb파일을 받아 마우스로 클릭만 해주면 자동으로 패키지 관리자가 실행되어 설치 하게 되어있다. 참으로 편리한 세상이다...
하지만, 위 내용을 알고 있어야... 보다 깊은 단계로 나아갈 수 있고 또 보다 세부적인 관리, 추가, 삭제가 가능하기에 알아 두는게 좋다고 본다.
참고: 위에 나열된 명령어들은 터미널 환경에서 사용되는 command입니다. 참고2: 빠른 작성을 위해 경어체를 생략했습니다. 이해해주시길 바랍니다 ^^;;
조금이나마 우분투 사용에 도움이 되길 바라며 다음에 뵙겠습니다. 전 국민이 우분투등의 리눅스를 자신의 OS로 쓰는 그날까지....
[AlexNet] ImageNet Classification with Deep Convolutional Neural Networks
심층 합성곱 신경망을 이용한 이미지넷 데이터셋 분류
요약
저희는 이미지넷 LSVRC-2010(ILSVRC: ImageNet Large Scale Visual Recognition Challenge) 대회에서 1.2만개의 고화질 이미지를 1000개의 클래스로 분류하는 거대하고 깊은 합성곱 신경망을 학습시켰습니다. 테스트 데이터를 사용하였을때, 우리의 모델은 top-1, top-5 에러 레이트를 각각 37.5%와 17.0%에 도달하였으며 이전의 최신 방법보다 상당히 크게 좋아진 결과를 얻었습니다. 우리의 신경망 모델은 6000만개의 파라미터와 65만개의 뉴런들을 가지고 있으며, 5개의 합성곱 계층과 몇몇 계층 뒤에는 맥스 풀링 레이어가 붙어있으며, 가장 마지막에 1000개의 소프트맥스 함수 결과를 내는 3개의 완전 연결 계층으로 이루어져있습니다. 학습 과정을 더 빠르게 하기 위해서, 뉴런들을 포화되지 않도록 했으며, 합성곱 연산을 효율적으로 수행하도록 GPU를 사용하였습니다. 그리고 완전 연결 계층에서 오버피팅 문제를 줄이기 위해서 최근 만들어진 규제 방법인 드롭아웃을 사용하였고, 훨씬 효율적임을 확인하였습니다. 또한 우리는 이 모델을 ILSVRC-2012 대회에도 참여하여 top-5 에러율을 15.3%로 두 번째 가장 좋은 성능인 26.2%보다 크게 앞서 우승하였습니다.
1. 소개
현재 물체 인식에 있어서 머신 러닝을 활용한 방법이 필수적으로 사용되고 있습니다. 그리고 이러한 방법들의 성능을 높이기 위해서 우리는 많은 데이터셋을 모으고, 더 뛰어난 모델을 학습시켜야 하며, 오버피팅을 방지하는 좋은 방법들을 사용해야 합니다. 하지만 최근까지도 라벨링된 이미지 데이터셋은 수만개 정도로 작은 편이었습니다(NORB, Caltech-101/256, CIFAR-10/100). 간단한 인식 문제 같은 경우에는 이런 적은 크기의 데이터셋만으로도 라벨을 유지한체 약간의 변환으로 증강시켜 잘 풀수가 있었습니다. 예를들어, MNIST 손글씨 인식 문제에서 최고 에러율은 0.3%이하로 사람에 거의 근접하였습니다. 하지만 실제 환경의 물체들은 아주 다양하게 나올수 있다보니, 모델이 인식할수 있도록 학습시키려면 훨씬 많은 테스트 데이터셋이 필요하였습니다. 이런 적은 이미지 데이터셋의 문제는 널리 알려져 있었으나(Pinto et al), 최근에 수백만개의 라벨링된 이미지들을 사용할수 있게 되었습니다. 이런 훨씬 크고 새로운 데이터셋으로 LabeMe와 ImageNet이 나왔는데, LabelMe는 완전 세그먼트된(물체별로 구역이 분리된) 이미지가 수십만개가 있으며, ImageNet의 경우 22,000개 카테고리의 라벨링된 고해상도 이미지가 1500만개 넘개 가지고 있습니다.
수백만개의 이미지로부터 수천가지의 물체를 학습하기 위해서는 아주 큰 학습 능력을 가진 모델이 필요합니다. 하지만 물체 인식의 엄청난 복잡성 때문에 ImageNet 만큼 거대한 데이터셋만으로 해결할 수 없습니다. 그래서 우리의 모델은 우리가 가지지 못한 모든 데이터를 고려/보완 할수 있도록 아주 많은 사전 지식또한 가지고 있어야 합니다. 합성곱 신경망(Convolutional Neural Network)로 다양한 모델들이 나왔는데 (논문 레퍼런스들이 있으나 생략), 이러한 모델들은 폭과 깊이를 조절하여 분류 능력을 조절 시킬수가 있으며, 그렇게 함으로서 통계학에서의 정상성(stationarity of statistics)와 인근 픽셀간의 의존성/연관성(locality of pixel dependencies *?) 같은 이미지의 성질에 대해서 강하고 명확한 가정들을 만들수가 있습니다 (의역:모델이 이미지에 관한 가정->지식들을 가질 수 있도록 할 수 있습니다.). 그래서 일반적인 비슷한 크기의 계층을 갖는 순전파 신경망과 비교했을때, CNN 모델들은 이론적인 최고 성능은 아주 약간은 나쁘더라도, 더 적은 연결과 파라미터 만으로도 쉽게 학습할수가 있습니다.
CNN의 매력적인 성질과 아키텍처 효율성에도 불구하고, 여전히 합성곱 신경망은 아주 많은 량의 고해상도 이미지들을 처리하기에는 상당히 비용이 비싼 편입니다. 하지만 다행이도 지금의 GPU들은 2차원 합성곱 연산을 구현하는데 있어서 최적화되어있어 거대한 합성곱 신경망과 ImageNet같이 충분한 량의 라벨링된 데이터들을 가지고 있는 최근 데이터셋으로 모델을 심한 오버피팅 없이 학습하는데 유용합니다.
본 논문이 기여한 사항으로는 다음이 있습니다. 우리는 ILSVRC-2010과 ILSVRC-2012에서 사용되던 이미지넷 데이터셋 일부로 가장큰 합성곱 신경망중 하나를 학습 시켜, 이전에 나온 최고 성능을 훨씬 뛰어넘었습니다. 그리고 GPU에 최적화 하여 2차원 합성곱 신경망 연산과 부차적인 연산들을 구현하여 공개시켰습니다. 그리고 우리가 만든 신경망은 여러가지 새롭고, 흔치 않은 특징->방법들을 사용하여 성능은 늘리고 학습 시간을 줄여내었고, 이 내용은 섹션 3에 자세히 서술되어 있습니다. 우리 신경망은 크기 때문에, 120만개의 라벨링된 이미지를 사용하였지만 오버 피팅이 큰 문제였습니다. 그래서 우리는 오버 피팅을 효과적으로 방지하는 여러가지 방법들을 사용하였고 섹션 4에 자세히 서술하였습니다. 그리고 우리의 최종 신경망은 5개의 합성곱 계층과 3개의 환전 연결 계층으로 이루어져 있는데, 신경망의 깊이가 중요한 것으로 보입니다. 한번 한 합성곱 신경망을 제거하였는데 (모델의 파라미터 중 1%도 안되는 양이었지만), 성능이 저하되는것을 확인하였습니다.
마지막으로 우리 신경망의 크기는 현재 GPU에서 사용가능한 메모리 공간 부족과, 학습하는데 기다릴 수 있는 학습 시간 등으로 제한되어 있습니다. 그래서 우리가 만든 신경망은 2개의 GTX 580 3GB GPU를 가지고 5 ~ 6일간 학습시킨 결과이며, 우리의 모든 실험 결과 더 빠른 GPU로 더 기다리고, 더 큰 데이터셋을 사용한다면 성능이 더 좋아 질수 있다는 사실을 알 수 있었습니다.
2. 데이터셋
ImageNet은 대략 22,000개의 카테고리를 가진 1500만개의 라벨링된 고해상도 이미지들로 이뤄진 데이터셋입니다. 이 이미지들은 웹에서 모았으며, 아마존 테크니컬 터크 크라우드 소싱 툴을 사용해서 사람이 직접 라벨링한 이미지입니다. 2010년부터 Pascal Visual Object Challenge 파스칼 시각 물체 대회의 한 파트로 시작되어 ImageNet Lager-Scale Visual Recognition Challenge(ILSVRC) 이미지넷 대용량 시각 인지 대회가 매년 개최되었습니다. ILSVRC는 ImageNet의 일부 데이터 셋을 사용하는대 대략 한 카테고리당 1000개의 이미지가 1000 카테고리로 이루어진 데이터셋을 이용합니다. 전체적으로, 대략 120만개의 훈련용 이미지와 5만개의 검증용이미지, 15만개의 테스트 이미지로 이뤄집니다.
ILSVRC-2010은 ILSVRC에서 테스트셋에 라벨이 주어진 유일한 버전이었으며, 그래서 이 버전을 사용하여 실험을 진행해보았습니다. 그리고 우리는 ILSVRC-2012 대회에도 참여하였는데, 섹션 6에다가 이 때 데이터셋으로 결과를 내었으나 테스트셋 라벨은 사용할 수 없었습니다. ImageNet 데이터셋을 이용할때 관례적으로 2가지 에러 레이트로 top-1과 top-5 에러 레이트를 사용합니다. top-5 에러 레이트는 모델의 가장 가능성이 높다고 판단한 5가지 중에 올바른/실제 라벨이 존재하지 않았을때 오류의 비율을 의미합니다.
ImageNet은 다양한 해상도의 이미지를 가지고 있으나, 우리 시스템의 경우 고정된 입력 차원/크기를 필요로 합니다. 그래서 우리는 이미지들을 고정 해상도 256 x 256으로 다운 샘플시켜 사용했습니다. 사각형의 이미지가 주어진다고 하면, 우선 이미지를 짧은 면의 길이가 256이 되도록 리스케일을 해주고, 리스케일된 이미지의 중앙을 256 x 256 크기 패치로 잘라내어 사용하였습니다. 그리고 각 픽셀들을 훈련셋 전체의 평균으로 빼주는것 이외에는 이미지에 별도 전처리 과정을 하지 않았습니다. 그래서 정리하자면 우리 신경망 모델은 (중앙화된) 처리되지 않은 RGB 픽셀값으로 학습되었습니다.
3. 아키텍처
우리 신경망의 아키텍처는 그림 2에 정리되어 있습니다. 이 신경망 아키텍처는 8개의 학습된 레이어로 구성되어 있는데, 5개는 합성곱, 3개는 완전 연결 레이어 입니다. 그리고 그 아래에는 우리 신경망 아키텍처에 소개된 새롭고 특별한 특징들을 서술하였습니다. 섹션 3.1 - 3.4에는 우리 생각에 중요한 순서대로 나열해서 가장 중요한 것을 첫번째로 놓았습니다.
3.1 ReLu 비선형 함수
그림 1: ReLU를 이용한 4층 합성곱 신경망(그냥 선)은 CIFAR-10 데이터셋으로 학습할때 25% 학습 오류율 도달에까지 tanh를 사용한 뉴런들로 이뤄진 동일한 신경망(점선)보다 6배가 빨랐습니다. 각 신경망의 훈련률은 학습이 가장 빠르게 되도록 별도로 선정하였습니다. 여기서 규제 기법은 사용되지 않았으며, ReLU를 사용한 효과는 신경망 아키텍처에 따라서 달라지나 ReLU를 사용한 신경망이 포화 활성화 함수를 사용하는 뉴런으로 이뤄진 동일 모델보다 여러배 빠르게 학습합니다.
입력 x가 주어질때 가장 기본적인 뉴런의 출력을 구하는 함수 f는 f(x) = tanh(x) [하이퍼볼릭 탄젠트 활성화 함수]나 f(x) = (1 + e^{-x})^{-1} [시그모이드 활성화 함수]가 있습니다. 하지만 훈련 중 경사 하강의 관점에서 보면 이러한 포화 활성화 함수는 비포화 활성화 함수 f(x) = max(0, x)보다 훨씬 느립니다. Nair와 Hinton의 연구에 이어서 우리는 이 활성화 함수를 사용하는 뉴런을 Rectified Linear Units(ReLUs) 개선된 선형 유닛이라 불렀습니다. ReLU를 사용하는 심층 합성곱 신경망은 tanh를 사용한 모델보 데이터셋다 여러배 빠르게 학습이 됩니다. 그림 1에 나타나 있는데, 어떤 4층 합성곱 신경망을 CIFAR-10 데이터셋으로 학습시킬떄 에러가 25%까지 도달하는데 반복 횟수를 보여주고 있습니다. 이 그림의 결과는 이번 연구에서 소개하고자 하는 거대한 신경망으로 실험을 진행할수가 없어 고전 포화 뉴런 모델을 사용하였습니다.
하지만 우리가 첫 번째로 합성곱 신경망을 기존 뉴런 모델(sigmoid 비선형 함수를 얘기하는 듯) 대신 다른 뉴런 모델을 사용하는걸 고려한 사람들이 아닙니다. 예를들어 Jarrett et al은 f(x) = |tanh(x)| 비선형 함수가 Caltech-101 데이터셋에서 지역 평균 풀링을 추가 시킬때 잘 동작한다고 하였습니다. 하지만 그 데이터셋에서 오버피팅이 일어나지 않도록 고민한 것이라, Jarrett가 얻은 효과는 우리가 ReLU를 사용해서 훈련셋 학습을 가속화시킨 것과는 다르다고 할수 있겠습니다. 빠른 학습은 큰 데이터셋으로 학습된 거대한 모델의 성능에 중요한 영향을 가집니다.
3.2 여러 개의 GPU로 학습 하기
하나의 GTX 580 GPU는 3GB 메모리 공간 뿐이라 학습시키고자 하는 신경망의 최대 크기를 제한하였습니다. 그렇다 보니 120만개의 훈련 데이터들은 신경망을 학습시키는데 충분한 양이었으나 GPU 하나만으로는 너무 많았습니다. 그래서 우리는 두 GPU를 사용하였는데, 현재 나온 GPU들이 병렬 작업을 하는데 적합하다보니, 호스트 컴퓨터의 메모리를 거쳐갈 필요 없이 GPU 메모리로부터 직접 읽고 쓰기를 할수 있었습니다. 우리가 사용한 병렬화 기법은 신경망(뉴런들) 절반을 각각의 GPU에다가 나누어줬는데, 트릭으로 GPU간에 일부 레이어들에서만 같이 연산할 수 있도록 만들었습니다. 정리를 하자면 3번째 커널/레이어는 2번째 레이어의 모든 커널/특징맵들을 입력으로 받을 수 있지만, 4번째 레이어는 같은 GPU에 있는 3번쨰 레이어의 특징맵들만을 입력으로 받을수가 있습니다. 어떤 연결 패턴을 사용할지 고르는건(? : 다양하게 연결시키는건) 교차 검증에 문제가 될수 있지만, 연산량 비중이 충분해 질때까지 GPU간의 소통량을 더 미세하게 조정할수 있도록 해줍니다. (? 일부 레이어들은 서로다른 GPU 레이어의 출력들을 사용가능한데, 연결패턴->어떻게 다른 GPU로부터 가져오는지에 따라서 미세 조정을 할수 있게 된다?? 정도로 이해됨.)
우리가 만든 아키텍터 결과물은 (그림2를 보면) 컬럼들이 독립적이지 않다는 점만을 빼면 Ciresan et al의 columnar CNN과 비슷하다고 할수 있겠습니다. 이 방법으로 합성곱 레이어 절반을 GPU 하나에서만 학습하도록 시켰을때와 비교하여, top-1, top-5 에러 레이트를 각각 1.7%, 1.2% 정도 줄여내었습니다. 2개의 GPU를 사용하여 만든 신경망은 GPU 1개를 사용한 경우보다 학습 시간이 약간 적었습니다.