728x90
Building Blocks of a Deep Neural Network (C1W4L05)
순전파와 역전파 함수
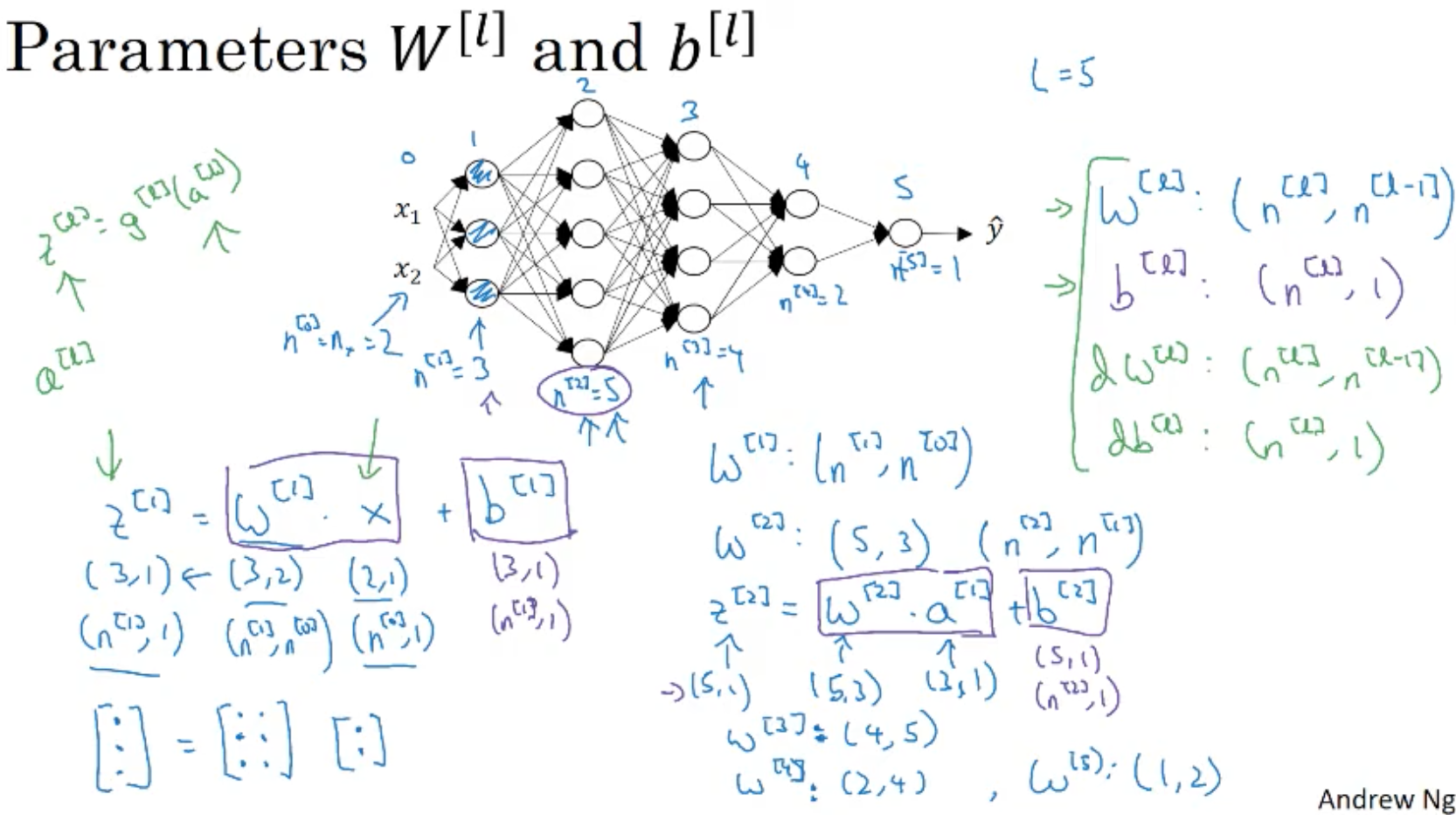
- l layer를 중심으로 살펴보자. w^[l], b^[l]
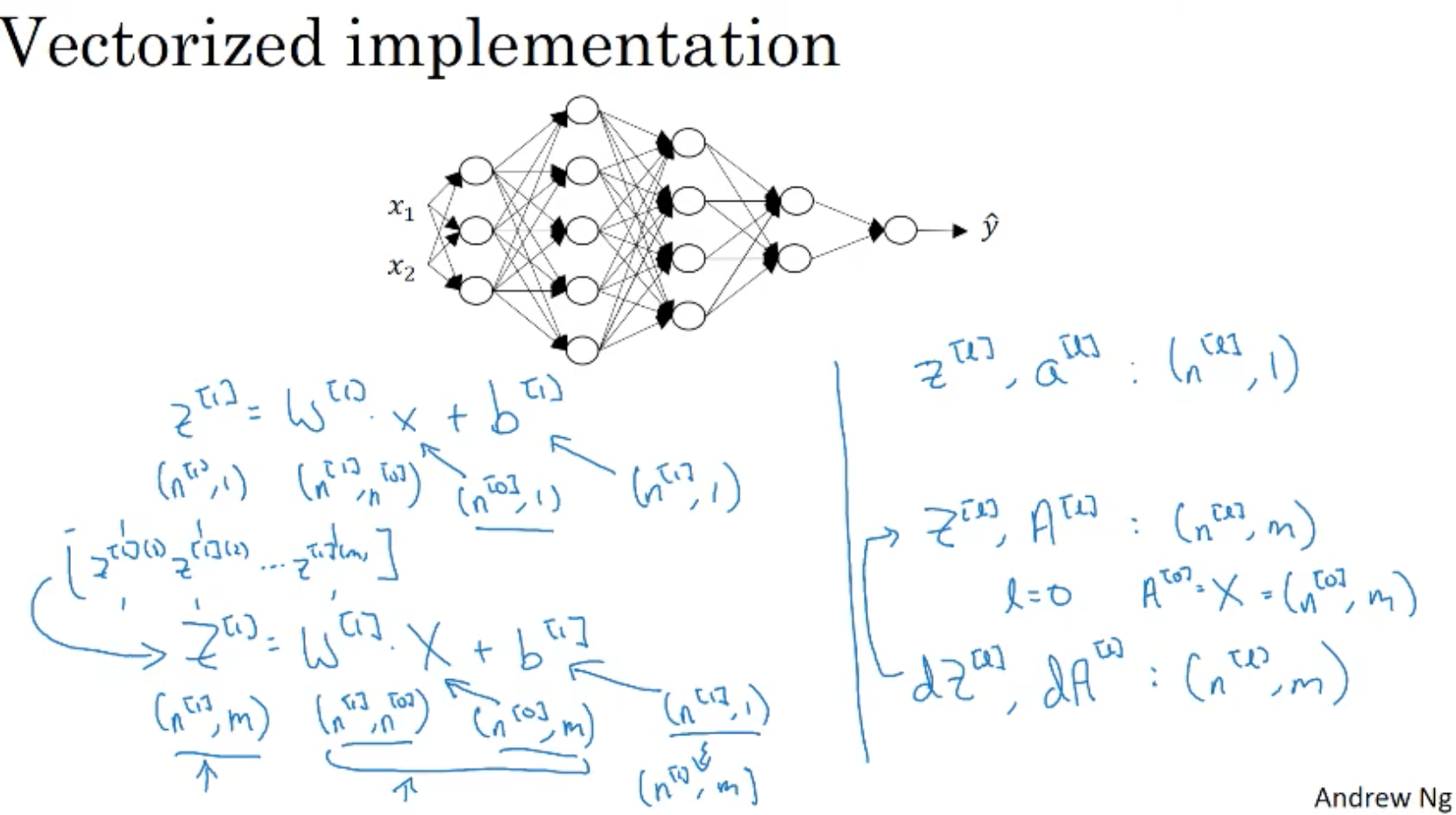
- 순전파 : 입력 a^[l-1], 출력 a^[l], z^[l] = w^[l] a^[l-1] + b^[l], a^[l] = g^[l](z^[l]).
* z^[l]은 캐싱한다.(역전파때 사용하게 임시 저장함.)
- 역전파 : input da^[l], cache z^[l], -> output : da^[l-1], dw^[l], db^[l]
=> 역전파 계산시 이전 레이어 da^[l]와 순전파때 캐싱한 z^[l]로 w,b, a에 대한 그라디언트들을 계산한다.

- 입력부터 출력까지 순전파, 역전파 연산 과정을 블록으로 보자.
* da^[0]의 경우 w나 b의 그라디언트, 미분계수를 계산하는데 필요없음.
* 그라디언트 계산에 w, b 도 필요하므로 같이 캐싱하자.

300x250
'컴퓨터과학 > 딥러닝 AI Andrew Ng' 카테고리의 다른 글
| C3W1L01 Improving Model Performance (0) | 2021.04.30 |
|---|---|
| C1W4L04 Why Deep Representations? (0) | 2021.04.29 |
| C1W4L03 Getting Matrix Dimensions Right (0) | 2021.04.29 |
| C1W4L02 Forward Propagation in a Deep Network (0) | 2021.04.29 |
| C1W4L01 Deep L-Layer Neural Network (0) | 2021.04.29 |