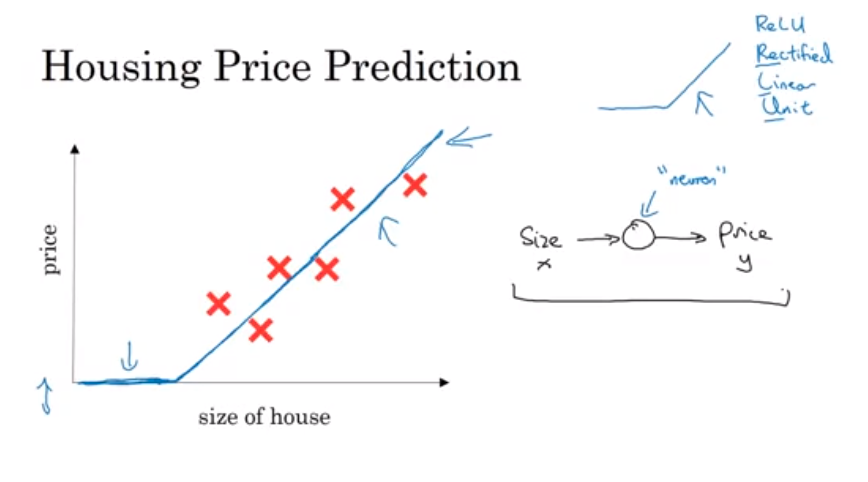
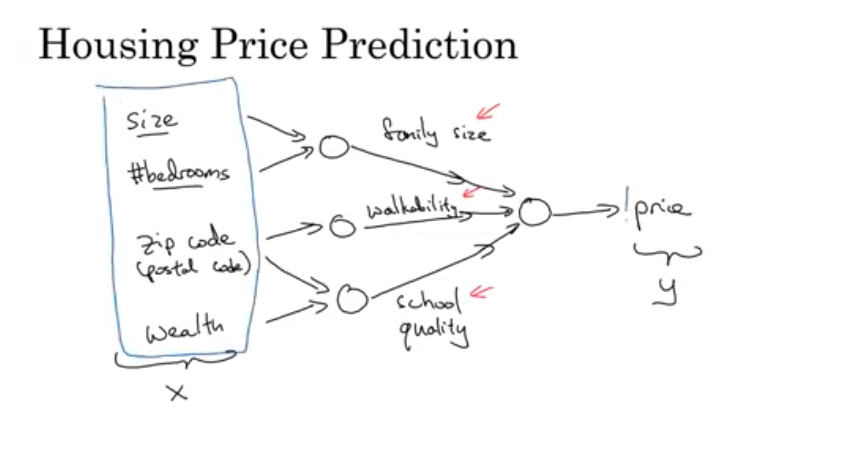
- 양적 투자 Quantitative investment는 수익을 최대화하고, 금융 거래 중에 발생가능한 위험의 최소화를 목표로 하고 있습니다.
* Quantitative investment : 최적의 수익률을 낼 수 있도록 수학적 모델링, 컴퓨터 시스템과 데이터 분석을 활용한 투자 방법
- 최근 양적 투자에 있어서 인공지능 기술의 거대한 잠재력과 빠른 발전으로, 인공지능을 활용한 양적 연구와 실제 투자에 사용이 증가하고 있습니다.
- 양적 투자 기법들이 활용되어 왔으나, 인공지능 기술들이 질적 투자 시스템에 도전해오고 있습니다.
- 특히 새로운 양적 투자에 대한 학습 파라다임은 혁신적인 워크 플로우를 따르도록 인프라를 개선시키고자하며, 그래서 데이터 주도 인공지능 기술은 좋은 성능을 내는 인프라를 필요로 하고 있습니다. 금융 시나리오들 중에서 다양한 문제들을 풀기 위해서 인공지능 기술을 적용시키는 것에는 몇가지 어려움들이 존재합니다.
- 이러한 어려움과 인공지능 기술과 양적 투자 사이의 갭을 다루고자, 우리는 양적 투자 분야에서 인공지능의 가치를 만들어내고 연구를 수행하며, 잠재력을 알아내고자 Qlib를 개발하였습니다.