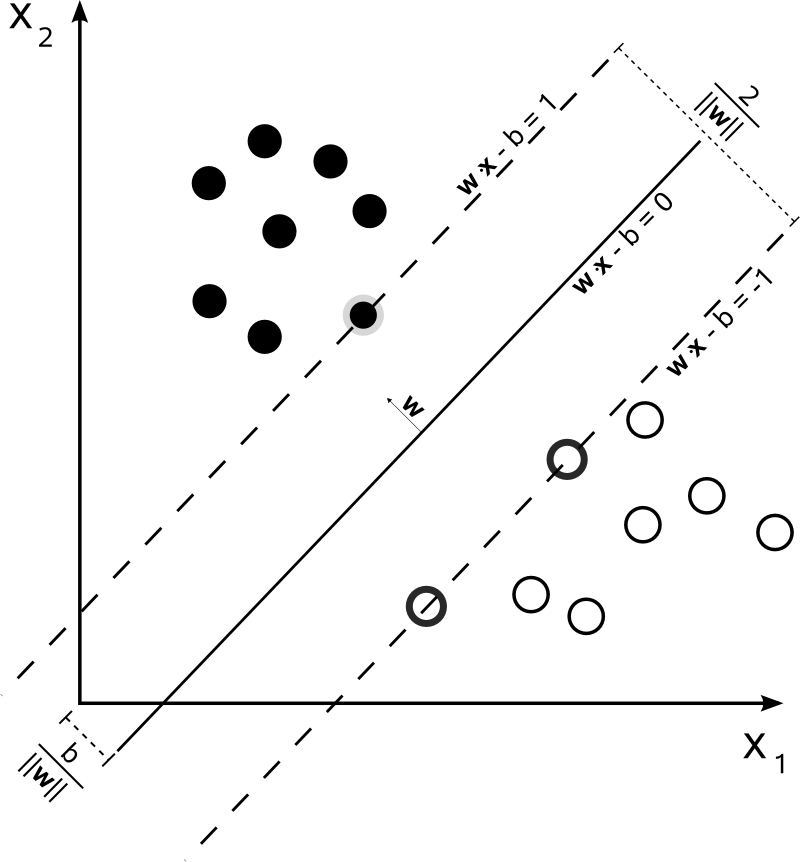
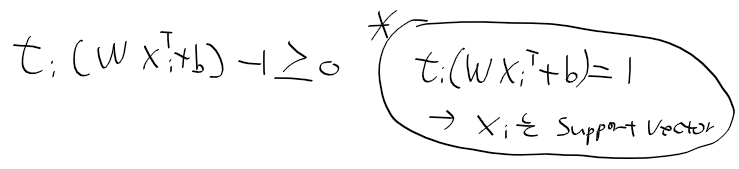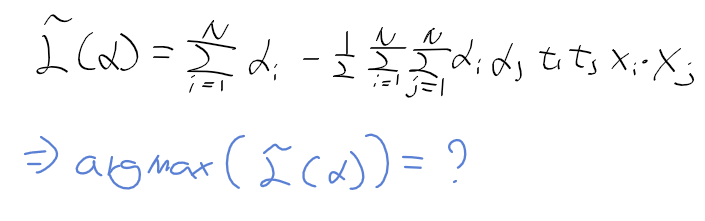Getting Started with Images — OpenCV-Python Tutorials 1 documentation
Getting Started with Images Goals Here, you will learn how to read an image, how to display it and how to save it back You will learn these functions : cv2.imread(), cv2.imshow() , cv2.imwrite() Optionally, you will learn how to display images with Matplot
opencv-python-tutroals.readthedocs.io
이미지를 가지고 시작해보자
목표
- 이 과정을 통해서 이미지를 읽는 방법과 화면에 띄우고 어떻게 저장을하는지 배워봅시다.
- 여기서는 다음과 같은 함수들을 사용하겠습니다. => cv2.imread(), cv2.imshwo(), cv2.imwrite()
- 옵션으로, matplotlib으로 이미지들을 표시할수도 있겠습니다.
1, opencv를 사용하여 이미지를 읽어보자

cv2.imread() 함수로 이미지를 읽을수 있습니다. 여기서 첫번째 매개변수는 이 이미지들은 작업 공간에 존재하거나 아니면 전체 경로를 전달해주어야 합니다.
두번째 매개변수는 플래그로 이 이미지를 어떻게 읽을지 명시하게 됩니다.
- cv2.IMREAD_COLOR : 색상 정보를 가진 이미지로 읽습니다. 대신 투명 성분은 무시(디폴트 플래그)
- cv2.IMREAD_GRAYSCALE : 이미지를 그레이 스케일 모드(명암 영상)으로 읽어들입니다.
- cv2.IMREAD_UNCHANGED : 알파 채널(투명도)를 포함해서 이미지를 로드합니다.
import numpy as np
import cv2
# 이미지를 흑백 영상( gray scale)로 읽어봅시다.
img = cv2.imread('/Users/jdo/git/python_vision/01day/kimheungkook.jpg',0)
print(img)파일명 : 01_imread.py
- 상대경로시 작업 공간 경로를 기준으로 파일을 찾기때문에 그냥 절대 경로를 주었습니다.
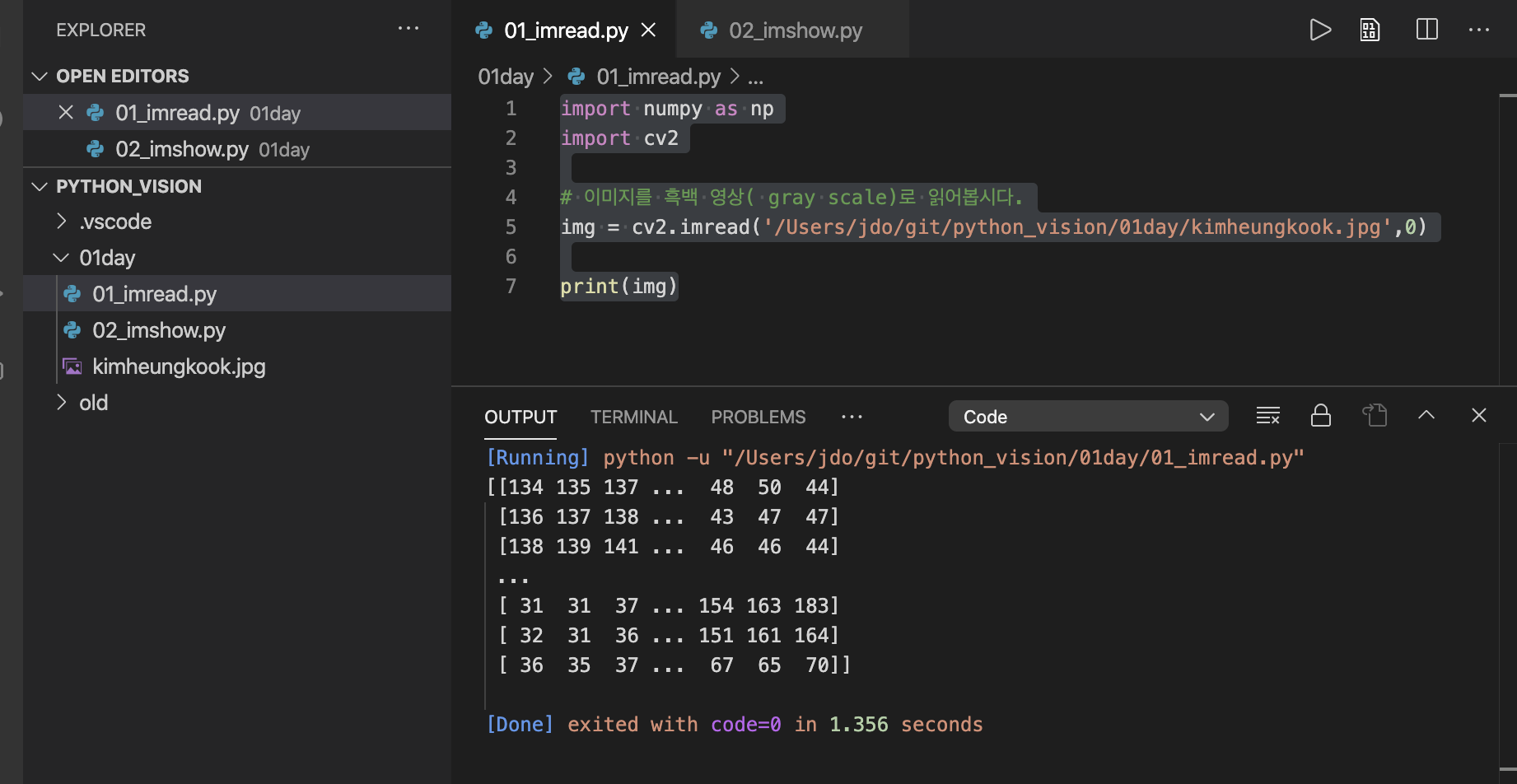
- 읽은 img를 print로 출력했더니, 흑백 이미지 정보(2차원 배열- 명암)을 출력 합니다.
* Visual Studio Code(VS Code) pylint Module cv2 has no member - import cv2 에러 해결방법.
다음 링크를 참조하자
http://blog.naver.com/x21999/221254889848
2. 이미지를 출력해 보자
import numpy as np
import cv2
# 이미지를 흑백 영상( gray scale)로 읽어봅시다.
img = cv2.imread('/Users/jdo/git/python_vision/01day/kimheungkook.jpg',0)
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()파일명 : 02_imshow.py
- imshow 함수로 image 라는 이름의 윈도우를 띄웁니다.
- waitKey(0)을 눌러 직접 키누를때까지 종료를 멈춥니다.
- 이미지가 닫히면 존재하는 모든 윈도우 자원들을 해제합니다.
결과

3. 이미지 쓰기
import numpy as np
import cv2
# 이미지를 흑백 영상( gray scale)로 읽어봅시다.
img = cv2.imread('/Users/jdo/git/python_vision/01day/kimheungkook.jpg',0)
cv2.imwrite('kimheungkook.png',img)파일명 : 03_imwrite.py
- 위 코드를 실행하면 김흥국.jpg를 읽어들인 후 png 파일로 저장합니다.
=> 작업 공간 루트에 저장됨..
4. 정리하기
import numpy as np
import cv2
img = cv2.imread('/Users/jdo/git/python_vision/01day/kimheungkook.jpg',0)
cv2.imshow('image',img)
k = cv2.waitKey(0) # 키 입력을 받을떄 까지 기다립니다.
if k == 27: # ESC 키가 눌리면 모든 이미지 자원들을 해제 합니다.
cv2.destroyAllWindows()
elif k == ord('s'): # s를 누르면 저장 후 저원들을 해제 합니다.
cv2.imwrite('kimheungkook.png',img)
cv2.destroyAllWindows()파일명 : 04_sumup.py
- 키 입력을 받을떄까지 이미지 띄우고 대기
- esc 를 누르는 겨우 자원 해제 후 종료
- s를 누르는 경우 png로 저장후 자원 해제 후 종료
* 다른 키를 눌러도 화면은 꺼지지만 정상적으로 자원이 해제되지 않습니다.

* 다음 부터는 아래로 작업 공간이 변경됩니다.
/Users/jdo/Documents/GitHub/opencv_python
'로봇 > 영상' 카테고리의 다른 글
| opencv-python 튜토리얼 - 4. 그리기 함수 사용하기 (0) | 2020.08.10 |
|---|---|
| opencv-python 튜토리얼 - 3. 호랑나비 돌려보기 (0) | 2020.08.10 |
| opencv-python 튜토리얼 - 1. 소개 (1) | 2020.08.10 |
| opencv-python 튜토리얼 - 0. 개요 (0) | 2020.08.09 |
| 컴퓨터 비전 - 33. 광류와 물체 추적 (0) | 2020.08.01 |