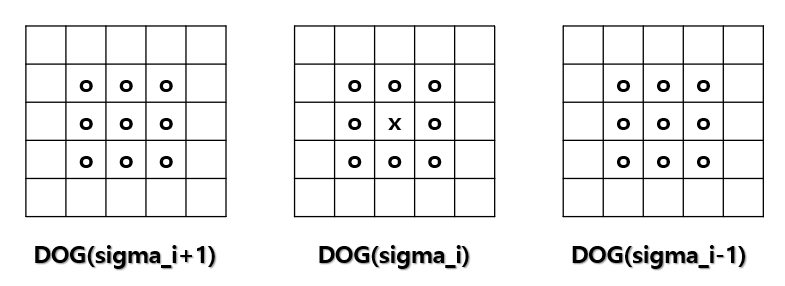
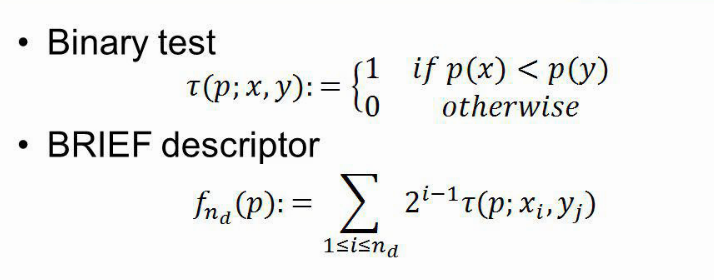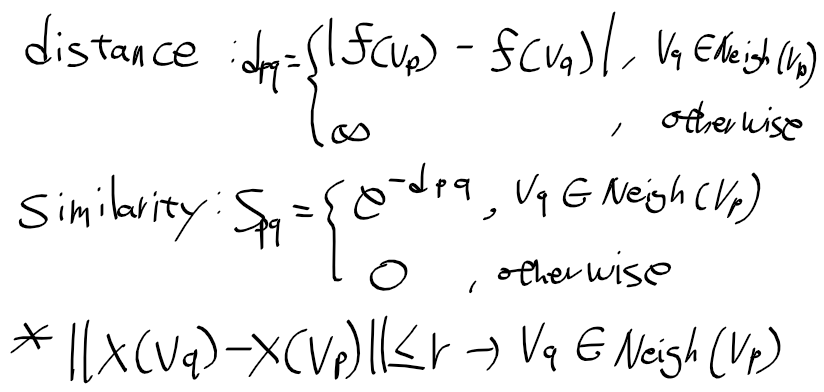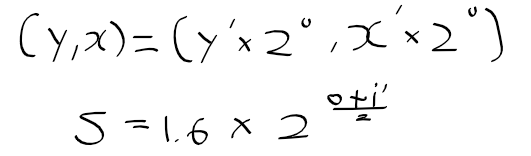이전 글에서는
이진 기술자들이 사용되는 이유와 특징 벡터를 추출하는 방법, 몇가지 경우의 조사 쌍들을 살펴봄
이번에는 대표적인 이진 기술자들인 BRIEF, ORB, BRISK를 살펴보자

BRIEF Binary Robust Indepent Elementary Features
BRIEF는 2010년 calonder가 소개한 이진 기술자로
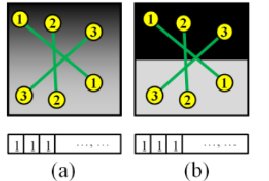
두 점을 가우시안 분포로 생성하여, 비교 쌍 256개를 만듦 -> 크기가 256비트
고정된 크기의 가우시안 분포에서 비교쌍을 생성하므로 스케일, 회전 변환 대처 불가
ORB Oriented FAST and Rotated BRIEF
ref : medium.com/data-breach/introduction-to-orb-oriented-fast-and-rotated-brief-4220e8ec40cf
2011년 OpenCV 연구소의 Rublee가 소개한 고속 특징 검출기로
FAST 키포인트 검출기와 수정 BRIEF 기술자를 기반으로 만들어진 알고리즘.
키포인트 주방향으로 회전시킨 BRIEF 기술자를 사용하여 회전 변환에도 불변함. 크기는 512비트
BRISK: Binary Robust Invariant Scalable Keypoints
ref : gilscvblog.com/2013/11/08/a-tutorial-on-binary-descriptors-part-4-the-brisk-descriptor/
2011년 Leutenegger가 소개한 회전, 스케일 변화에도 강인한 이진 특징 기술자.
특징점 주위 60개 점을 비교 쌍으로 사용하는데,
특징 스케일에 따른 거리 조건을 만족하는 쌍만 선정하여 스케일에 강인해짐
+ 특징점 방향에 따라 회전한 60개 점을 사용해 회전 불변
크기는 512비트
'인공지능' 카테고리의 다른 글
| 컴퓨터 비전 & 패턴 인식 - 29. 이미지 매칭을 위한 거리 척도와 매칭 방법 (0) | 2020.12.16 |
|---|---|
| 컴퓨터 비전 & 패턴 인식 - 28. 중간 (0) | 2020.12.16 |
| 컴퓨터 비전 & 패턴 인식 - 26. 이진 기술자 (0) | 2020.12.15 |
| 컴퓨터 비전 & 패턴 인식 - 25. SIFT 변형 (0) | 2020.12.15 |
| 컴퓨터 비전 & 패턴 인식 - 24. SIFT 기술자 (0) | 2020.12.15 |