sklearn 모듈 개요
1. 데이터셋 datasets
2. 특징 처리
2.1 preprocessing
- 인코딩, 정규화, 스케일링 등
2.2 feature_selection
- 큰 영향을 미치는 피처 순서대로 선정
2.3 feature_extraction
- 피처 추출
2.4 decomposition
- 차원 축소 알고리즘 지원. LDA, PCA, SVD 등
3. 데이터 분할, 검증, 하이퍼 파라미터 튜닝 model_selection
- 교차 검증, 최적 하이퍼파라미터 추출을 위한 그리드 서치 등 제공
4. 성능평가 척도 metrics
- 정확도 accuracy, 재현율(모델 참/실제 참) recall, 정밀도(모델참/전체 참) precision, ROC-AUC, RMSE 등
5. 머신러닝 알고리즘
5.1 ensemble : 랜덤 포레스트, 어댑티브부스트, 그라디언트 부스트
5.2 linear_model : 선형 모델, 릿지, 라쏘, 로지스틱 회귀, SGD
5.3 naive_bayes : 나이브 베이즈, 가우시안NB
5.4 neighbors : K-NN
5.5 svm : 서포트 벡터 머신 관련 알고리즘
5.6 tree : 결정 트리
5.7 cluster : k-means, dbscan 등
6. pipeline : 피처 처리, 학습, 예측 등을 함께 할수있는 묶음.
교차 검증
교차 검증하기
- 과적합 문제를 개선하기 위해 사용
* 과적합 : 학습 데이터에 모델이 과도하게 맞춰져, 실제 예측시 성능이 떨어지는 현상.
- 학습 데이터를 학습, 검증 데이터로 분할하여 학습 (위의 train_test_split으로 분할하여 학습한 것과 같이)
k fold cross validation
- 데이터를 k개로 분할하여 (k-1)개로 학습, 1개로 테스트를 k번 수행하여 검증하는 방법
- model_selection의 KFold 사용
- KFold(n_split=) -> KFold.split(X) 데이터를 n_split 만큼 분할하여 인덱스 반환
from sklearn.model_selection import KFold
kfold = KFold(n_splits=5)
num_iter = 0
cv_acc = []
for train_idx, test_idx in kfold.split(X):
X_train, X_test = X.iloc[train_idx, :], X.iloc[test_idx, :]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
num_iter = num_iter + 1
acc = round(accuracy_score(y_test, y_pred), 10)
print("{}번 검증 셋 정확도 : {} ".format(num_iter, acc))
cv_acc.append(acc)
print("mean of accuracy : {} ".format(round(np.mean(cv_acc),7)))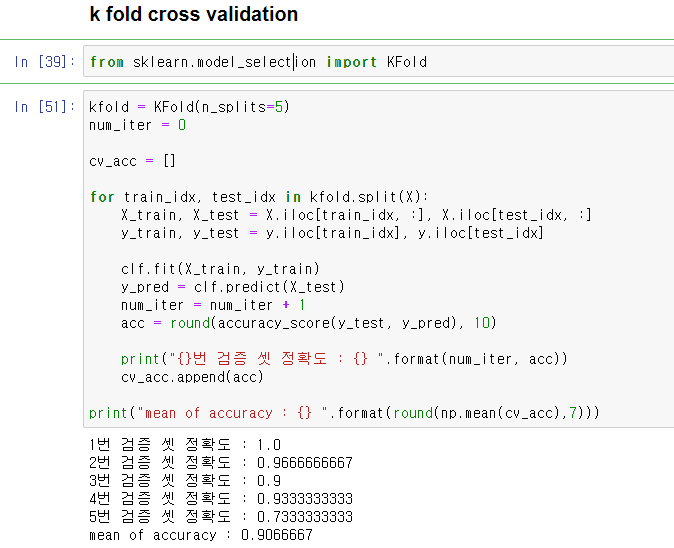
stratified K fold
- 타겟 레이블의 비율이 불균형한 데이터를 위한 k fold
- 타겟 레이블의 분포도를 반영하여 인덱스 제공
- KFold와 다르게 StratifiedKFold.split(X, y)는 X와 y를 같이 제공해주어야 함.
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=5)
for train_idx, test_idx in skf.split(X, y):
...
cross_val_score
- 교차 검증과 성능 평가 척도를 한번에 하는 함수
- cross_val_score(estimator, X, y=None, scoring=None, cv=None, n_jobs=1, verbose=0, ....)
from sklearn.model_selection import cross_val_score
scores = cross_val_score(clf, X, y, scoring="accuracy", cv=5)
print(scores)
print(np.mean(scores))
하이퍼 파라미터 탐색
GridSearchCV
- GridSearchCV(estimator, param_grid, scoring, cv, refit)
* param_grid : 하이퍼 파라미터 딕셔너리, refit : 디폴트 true, 최적 하이퍼파라미터로 재학습
from sklearn.model_selection import GridSearchCV
clf = DecisionTreeClassifier()
param = {
"max_depth":[1, 2, 3, 4, 5],
"min_samples_split":[2, 3, 4]
}
grid_clf = GridSearchCV(clf, param_grid=param, cv=5, refit=True)
grid_clf.fit(X_train, y_train)
scores_df = pd.DataFrame(grid_clf.cv_results_)
scores_df.head()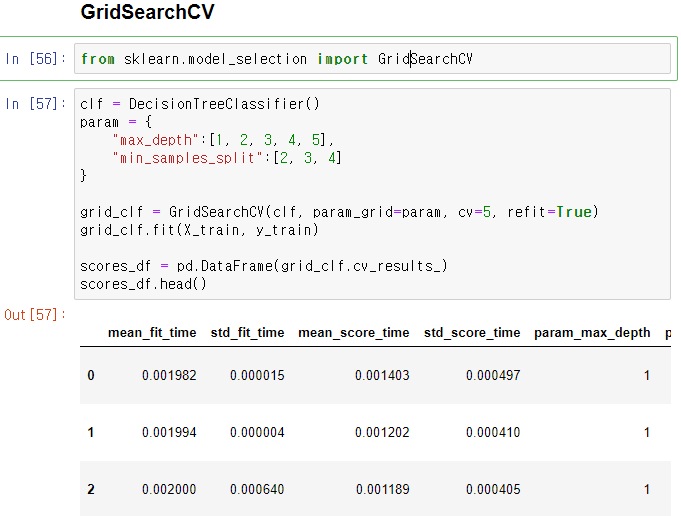
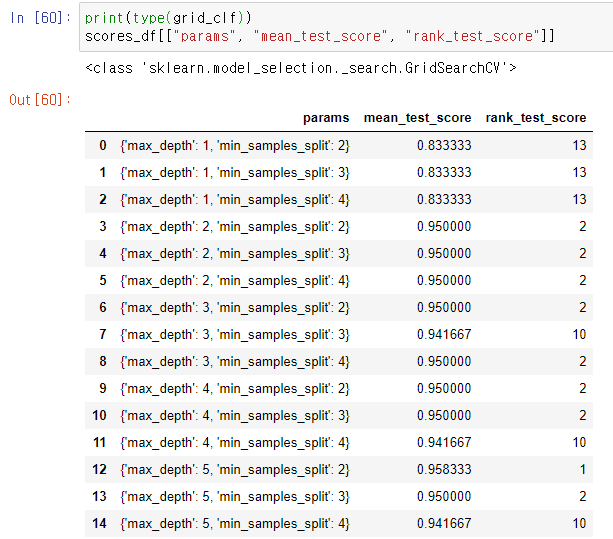
- GridSearchCV.cv_result_로 결과 반환. 데이터프레임으로 변환 후 출력 시
-> max_depth가 5이고, min_samples_split이 1인 경우 최적 성능
- GridSearchCV의 변수로 best_params_, best_score_, best_estimator_ 등 제공
print(grid_clf.best_params_)
print(grid_clf.best_score_)
clf = grid_clf.best_estimator_
print(clf.score(X_test, y_test))
'인공지능' 카테고리의 다른 글
| 파이썬머신러닝 - 5. 타이타닉 생존자 예측 (0) | 2020.11.23 |
|---|---|
| 파이썬머신러닝 - 4. 데이터 전처리 : 인코딩/피처 스케일링 (0) | 2020.11.23 |
| 파이썬머신러닝 - 2. 붓꽃 문제 다루기 (0) | 2020.11.23 |
| 파이썬머신러닝 - 1. 기초 (0) | 2020.11.23 |
| 패턴인식이론 - 1. 간단 (0) | 2020.11.18 |