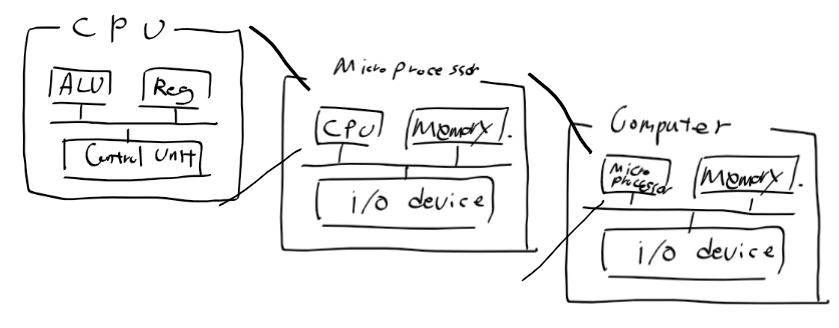
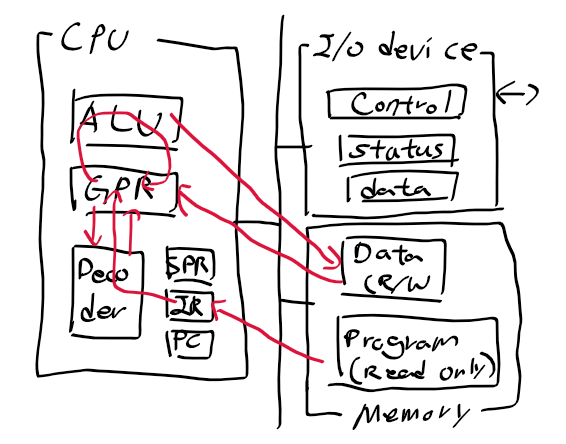
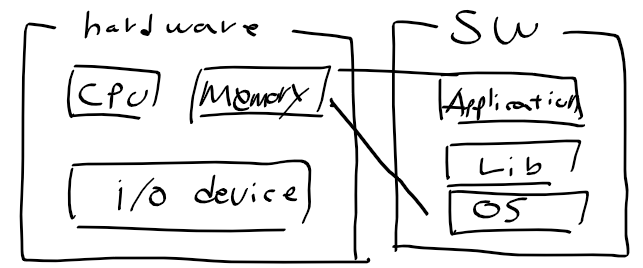
임베디드 시스템 소프트웨어 개발
- 소스 편집 -> 컴파일 -> 실행의 반복
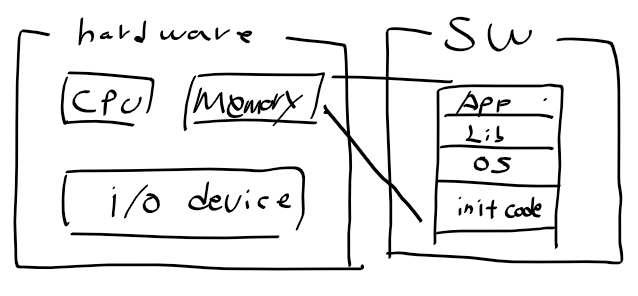
- 임베디드 시스템의 성능이나 리소스가 충분하지 않음
-> 개발 기간 단축을 위해 호스크 컴퓨터에서 컴파일 후 실행파일을 임베디드 시스템에 다운로드함
make 유틸리티 프로그램
- 반복되는 컴파일 명령어를 간단하게 실행할수 있는 도구
디버깅 프로그램 GDB
- 컴파일 과정 중 디버깅 작업을 도와줌
- 소프트웨어 개발 중 가장 많인 시간 필요
- 사양 받음 -> 시스템 모델링 -> 데이터 구조 정의 -> 알고리즘 설계 -> 프로그램 코딩
-> 이후 테스트 및 디버깅이 대부분 시간 차지
(1) 크로스 컴파일
1) 컴파일 절차
2) 컴파일 유형
3) 툴 체인
4) ARM용 크로스 컴파일 설치
1) 컴파일 절차
컴파일 과정
- 소스 프로그램으로부터 목적파일 만드는 과정
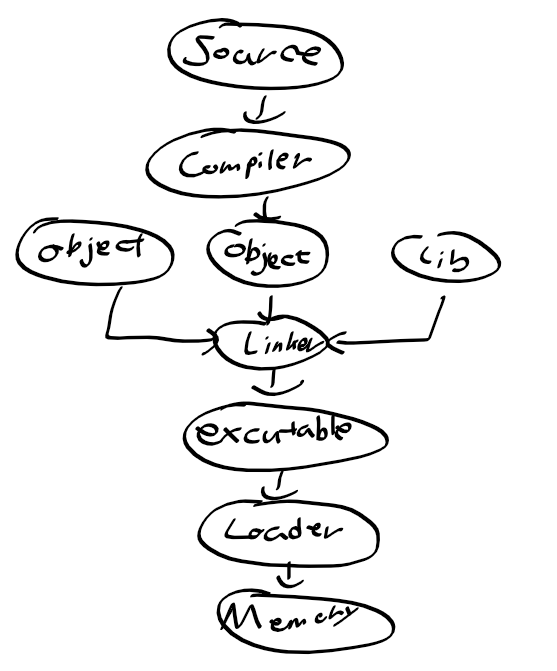
2) 컴파일 유형
프로그램 컴파일 방식
1. 네이티브 컴파일
- 컴파일 프로세서와 실행 프로세서가 동일한 경우
2. 크로스 컴파일
- 컴파일 프로세서와 실행 프로세서가 다른 경우
임베디드 시스템에서의 컴파일
- 임베디드 시스템에선 성능이 부족하여 범용 컴퓨터에서 컴파일 하여 타겟 보드에 다운로드함 -> 크로스 컴파일
3) 툴 체인
- 시스템 프로그램 및 응용프로그램 개발에 사용되는 개발도구 모음
- 구성품 : 문서 편집기, 컴파일러, 어셈블러, 링커, 유틸리티 프로그램, 라이브러리
대표적인 임베디드 시스템 툴체인
- vi 문서 편집기, gcc 컴파일리, as 어셈블러, ld 링커
- 유틸리티 - binutils 패키지(어셈블러, 링커, 목적코드 분석 프로그램), 표준 C 라이브러리 - glibc
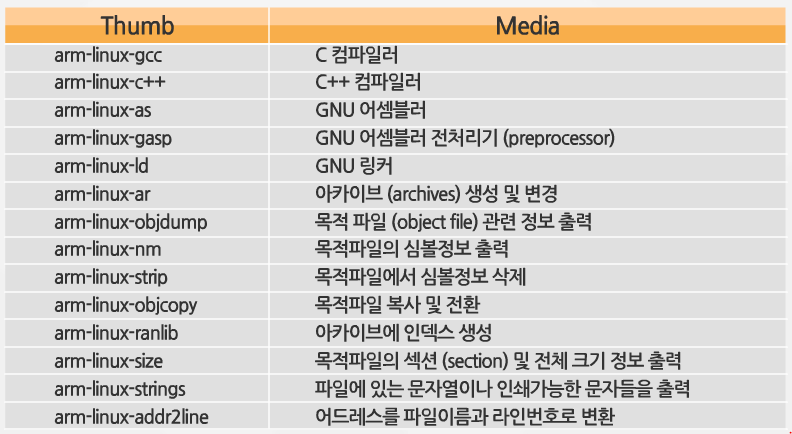
ARM 용 툴 체인
- 바이너리 유틸리티 앞에는 arm 접미사가 붙음
- objdump는 목적 파일을 분석하는 명령어
4) ARM용 크로스 컴파일러 설치
설치방법
1. pre-compiled 툴 체인 설치
- 압축파일 해제
- 저장된 디렉토리를 환경변수 PATH에 등록
- 미리 컴파일된 툴체인 -> /usr/cross-tools로 설치 위치 고정
- 실행 파일이 저장된 디렉토리를 쉘 프로파일에 저장해서 쓰는게 편리
* vi ~/.bash_profile
* export PATH=/usr/cross-tools/bin:$PATH
2. 크로스 컴파일러 소스를 직접 호스트 컴퓨터에 설치
- GNU 크로스 컴파일러 소스를 다운받아 호스트 컴퓨터에서 컴파일 하여 툴체인 환경 구축
- 호스트 컴퓨터에 C 컴파일러 사전 설치
- 소스 설치
크로스 컴파일러 테스트
- 정상 설치 여부 확인함
- 네이티브 컴파일러와 크로스 컴파일러를 둘다 실행해서 잘 동작되는지 확인
- 테스트 프로그램 foo.c
#include <stdio.h>
int main(){
printf("Hello Embeded System World!\n");
return 0;
}네이티브 컴파일
#gcc -o foo-x86 fool.c
크로스 컴파일
#arm-linux-gcc -o foo-arm foo.c
실행 파일 타입 확인
Host #file foo-x86
Host #file foo-arm
타겟 보드에 다운로드 후 타겟보드에서 실행
TB #./foo-arm
(2) Make와 GDB
1) make 유틸리티
2) GDB 디버거
1) make 유틸리티
make 유틸리티 개요
- 여러개 파일로 작성된 프로그램을 효율적으로 컴파일하는 유틸리티
- 프로그램 컴파일 과정 제어, 응용 프로그램 설치위치 관리, 메뉴얼 페이지 작성에 활용
=> 프로그램 개발 프로젝트에 유용하게 사용
makefile
- make 유틸리티의 컴파일 절차를 정의하는 파일
- make 유틸리티가 참조하는 파일, 소스 파일과 동일한 디렉토리에 저장
- 프로그래머는 소스파일과 함께 makefile 작성
makefile 문법
- 의존관계 : 하나의 타겟(실행파일), 타겟과 의존관계에 있는 소스파일들
- 규칙 : 의존 관계에 있는 소스파일들로부터 타겟을 생성하는 방법 정의
make 명령어
- 현재 디렉토리에 저장된 makefile이나 makefile을 순차적으로 찾아서 참조
make + 타겟 이름 => make myfoo -> 타겟 = myfoo
make (타겟 미지정시) => all이라는 타겟 정의하여 사용
의존 관계 dependency
- 타겟과 소스파일들과의 의존 관계 정의
- 의존관계 표현 방법 : "타겟 이름"+":"+" "+"필요한 파일 이름"
- 예시
foo: boo.o doo.o -> foo를 만들기위해 boo.o, doo.o가 필요
boo.o: boo.c boo.h -> boo.o를 만들기 위해 boo.c, boo.h가 필요
doo.o: doo.c doo.h -> doo.o를 만들기 위해 doo.o, doo.h 필요
가상 타겟
- 실제 타겟이 아니라 make에서 사용하는 타겟 ex-all, clean
- all : 타겟으로 여러 파일 만들경우 사용
규칙과 주석
- 규칙 : 의존 관계에 있는 파일들로부터 타겟을 만드는 방법
- makefile내 정의시 반드시 TAB 문자로 시작
foo.o:foo.c foo.h
gcc -c foo.c
- 주석 : #라인으로 시작
매크로
- makefile에서 자주사용하는 용어 재정의
- 컴파일 명령이나 옵션등을 재정의해서 사용함
- 정의 : MACRONAME=value
- 사용 : $(MACRONAME), $MACRONAME
- command-line 매크로 : make CC=gcc or make "CC = GCC"
내부 정의 매크로
- 사용자가 정의하는 매크로로외 make 유틸리티에서 자체 정의해둔 매크로
- $? : 현재 타겟보다 최근에 변경된 의존파일 리스트
- $@ : 현재 타겟 이름
- $< : 현재 의존파일 이름들
- $* : 접미사를 제외한 현재 의존파일 이름들
- -(minus) : 명령어 앞에 "-" 붙이면 에러발생 무시
- @ : 명령어 실행하기전에 명령어 화면표시금지
예시
all:myapp
CC=gcc
INSTDIR=/usr/local/bin
CFLAGS=-g -Wall
myapp:main.o foo.o boo.o
$(CC) -o myapp main.o foo.o boo.o
main.o:main.c myhead.h
$(CC) $(CFLAGS) -c main.c
foo.o:foo.c foohead.h
$(CC) $(CFLAGS) -c foo.c
boo.o:boo.c boohead.h
$(CC) $(CFLAGS) -c boo.c
clean:
rm main.o foo.o boo.o
2)GDB
GDB 개요
- 텍스트 기반 GNU 디버거
- 리눅스 시스템에서 사용하는 기본 디버거
- 프로그램 소스 컴파일 시 -g 옵션 추가 -> 디버깅에 필요한 정보 생성
- 실행 명령어 : gdb 목적파일이름
GDB 명령어
- run 프로그램 실행
- help 명령어 도움말
- backtrace 스택 트레이스, 이전호출함수 표시
- print 함수 파라미터, 지역변수, 전역 데이터 확인
- list 현재 실행위치 주변 코드 표시
- quit GDB 종료
- break n 브레이크 포인트 설정, n번쨰 라인에서 브레이크
- clear n 브레이크 포인트 해제
- display 브레이크 포인트 도착시, 보여줄 데이터 등록
- commands n : n번브레이크 도착시 실행하는 gdb 명령어 등록
- info display : 설정된 브레이크 포인트나 브레이크포인트 도착시 보여줄 등록된 데이터에 대한 정보 표시
- cont : 실행 계속
'컴퓨터과학 > 임베디드' 카테고리의 다른 글
| ARM을 활용한 임베디드 시스템 설계 16 - 부트로더 구조 (0) | 2020.05.04 |
|---|---|
| ARM을 활용한 임베디드 시스템 설계 15 - 임베디드 시스템 개발 환경 (0) | 2020.05.04 |
| ARM을 활용한 임베디드 시스템 설계 13 - shell 프로그래밍 (0) | 2020.05.04 |
| ARM을 활용한 임베디드 시스템 설계 7 - ARM 명령어 구조 (0) | 2020.05.04 |
| ARM을 활용한 임베디드 시스템 설계 6 - 레지스터 (0) | 2020.05.04 |