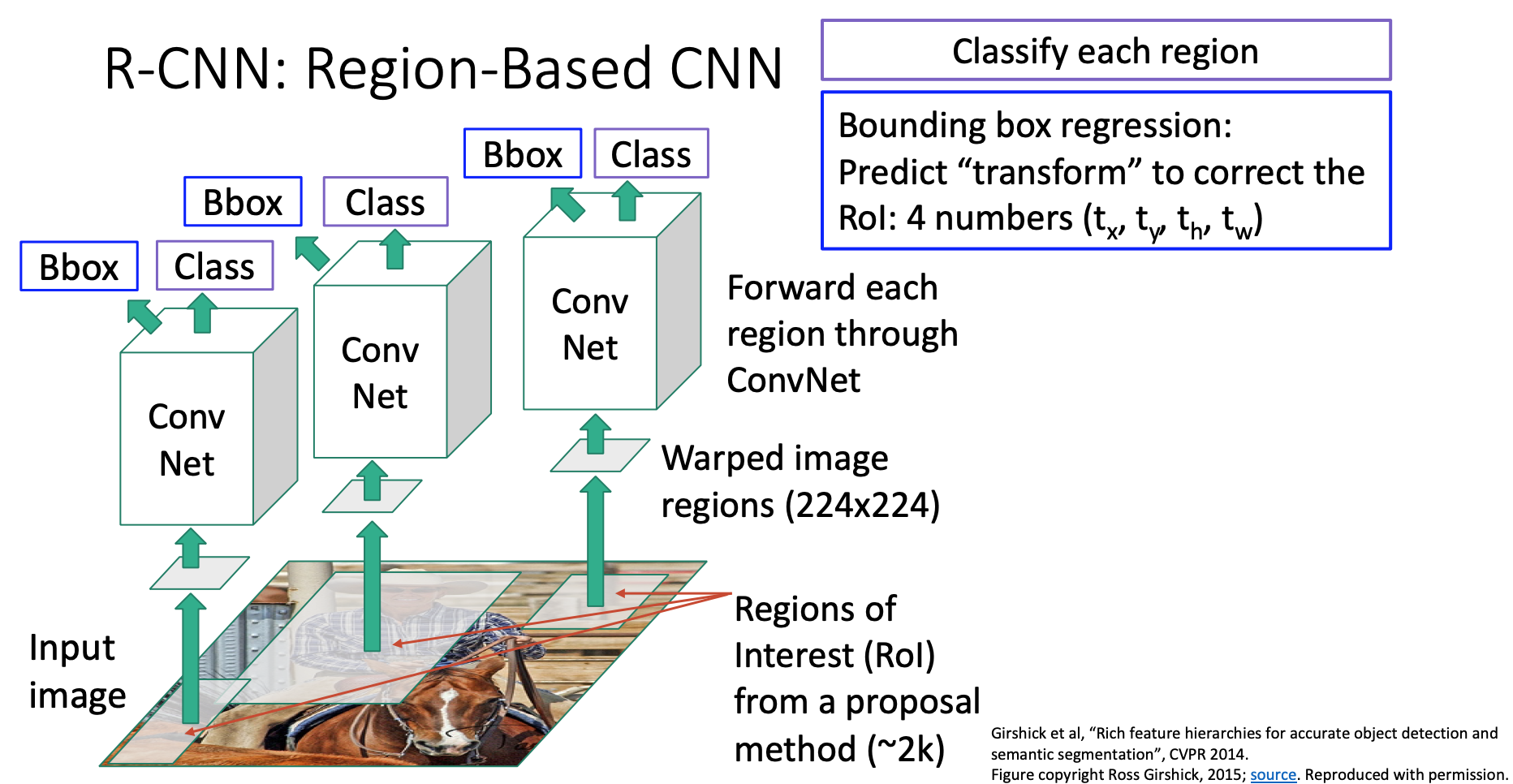
척도에 대해서 이제 정리하고 다시 객체 탐지 방법으로 돌아갑시다. R-CNN은 영역 기반 합성곱 신경망으로 객체를 잘 탐지합니다.

하지만 이 모델은 매우 느린 문제를 가지고 있는데, 선택적 탐색 방법으로 얻은 각 제안 영역들에 대해서 합성곱 신경망을 통한 연산을 하기 때문입니다. 선택적 탐색 방법은 2000개의 제안 영역들을 만든데 이미지로부터 객체 검출시 2000개의 순전파 연산을 해야되다보니 꽤 계산비용이 크며 매번 이미지들을 실시간으로 돌리기는 어렵겠습니다.

그래서 이 과정을 더 빠르게 만들어야하는데, 사람들이 사용하는 이 과정을 더 빠르게 만든 방법으로 합성곱 신경망을 돌리고 나서 워핑을 합니다. 그렇게 함으로서 서로 다른 영역들 간에 많은 계산량을 공유할수 있게 되요(?)

어떻게 이계 동작할까요. 일단 R-CNN을 느린 R-CNN이라고 부르고 있습니다.
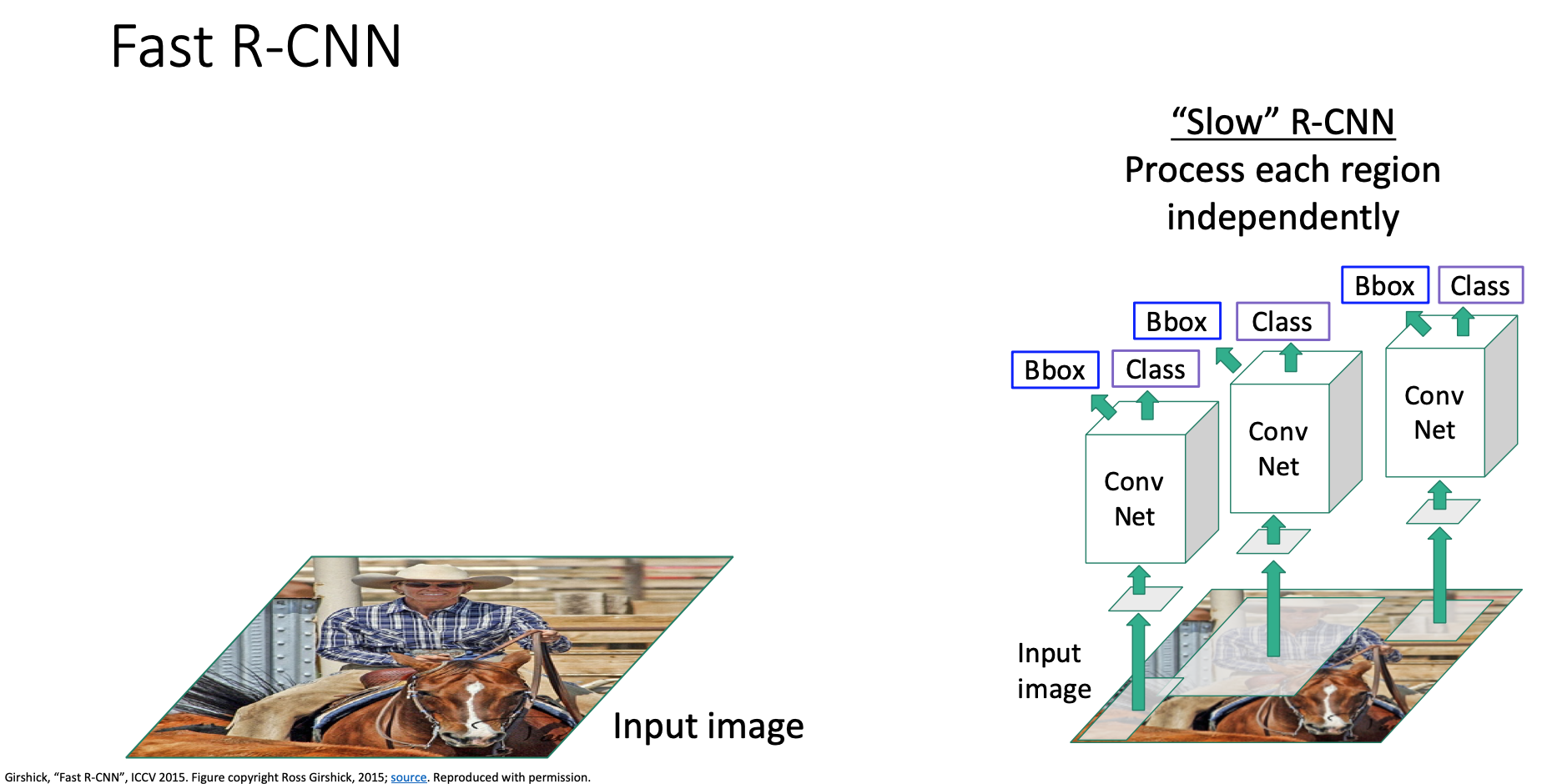
이를 대신하는 방법을 Fast R-CNN이라 불러요. Fast R-CNN은 기본적으로 slow r-cnn과 동일하나 합성곱 연산과 영역 변환의 순서를 뒤바꿉니다.

입력 이미지를 가지고 와서 이 고해상도 이미지를 단일 합성곱 신경망으로 돌립니다. 이 신경망은 완전 연결신경망없이 전체가 합성곱 레이어로 이루어집니다. 그 출력 결과는 합성곱 특징 맵이 나오겠습니다. 이 이미지를 돌리는 모델을 백본 신경망이라 부릅니다. 이건 alexnet이나 vgg, resnet 등 사용하고 싶은걸 쓰면 되요.

그 다음에는 선택적 탐색같은 영역 제안 방법을 돌릴수가 있는데, 입력 이미지의 픽셀을 잘라내기보다는

제안 영역들을 합성곱 특징 맵에다가 사영시켜, 입력 이미지가 아닌 이 특징 맵으로부터 잘라내겠습니다. 정리하자면 합성곱 백본 신경망으로 부터 얻은 특징 맵을 잘라낸다고 생각하면 되겠습니다.

그러고나서 각 영역들마다 가벼운 신경망을 돌리고

출력으로 각 영역별로 분류 스코어랑 바운딩 박스 회귀 변환값들을 얻겠습니다.

이 과정은 아주 빠른데 대부분의 계산 과정은 백본 네트워크에서 일어나기 때문이며, 각 영역마다 돌아가는 신경망은 아주 작고 가볍다보니 빠르게 돌아갑니다.

그래서 alexnet을 백본 신경망으로 활용한 fast r-cnn 모델의 경우 벡본은 알렉스넷의 합성곱 레이어 전체가 되겠고, 각 영역 신경망은 마지막 두 완전 연결 레이어가 되겠습니다. 이 방법은 영역이 많더라도잘 동작하겠습니다.

잔류 신경망을 사용하는 경우에는 마지막 합성곱 연산 단계를 각 영역들을 연산하는데 사용하고, 나머지 단계들이 백본으로 사용되겠습니다. 백본 신경망에서 제안 영역들간의 연산량을 공유함으로서 계산량을 줄이겠습니다.

그러면 여기서 특징을 잘라낸다는게 어떤 의미는 무엇일까요? 백본 신경망의 가중치들을 잘 역전파 시키기 위해서는 이 특징들을 미분 가능하도록 잘라내어야 합니다.

특징을 미분 가능하도록 잘라내는 방법은 ROI(Region Of Interest) Pool이라고 부르는 연산자를 사용하면 되겠습니다. 여기에 이런 입력이미지와 입력 이미지에 대한 제안 영역이 주어지면

벡본 신경망을 돌려서 위와 같은 합성곱 연산을 통해 이미지 특징을 얻겠습니다. 데이터 형태를 정리하자면 입력 이미지는 rgb채널과 공간 크기로 640 x 480을 가지고 있으며, 합성곱 특징은 512차원에 20 x 15의 공간적 크기를 가지겠습니다.

이 신경망은 완전히 합성곱 연산으로만 이루어져있기때문에 이 합성곱 특징 지도는 입력 이미지의 각 점들에 대응한다고 할 수 있겠습니다. 우리가 할 일은 이 제안 영역을 특징 맵에다가 사영시키겠습니다. 이 다음으로는 이 특징들을 스냅(딸각 맞출수가)시킬수가 있는데, 사영한 뒤에 제안 영역이 합성곱 그리드에 완전히 일치하지 않거든요

그래서 합성곱 지도 격자에 맞추도록 스냅을 시키고,

2 x 2 풀링을 할 수 있도록 2 x 2 하부 영역으로 나누겠습니다. 그래서 제안 영역을 대략적으로 가능한 2 x 2의 하부 영역으로 나눈다음에
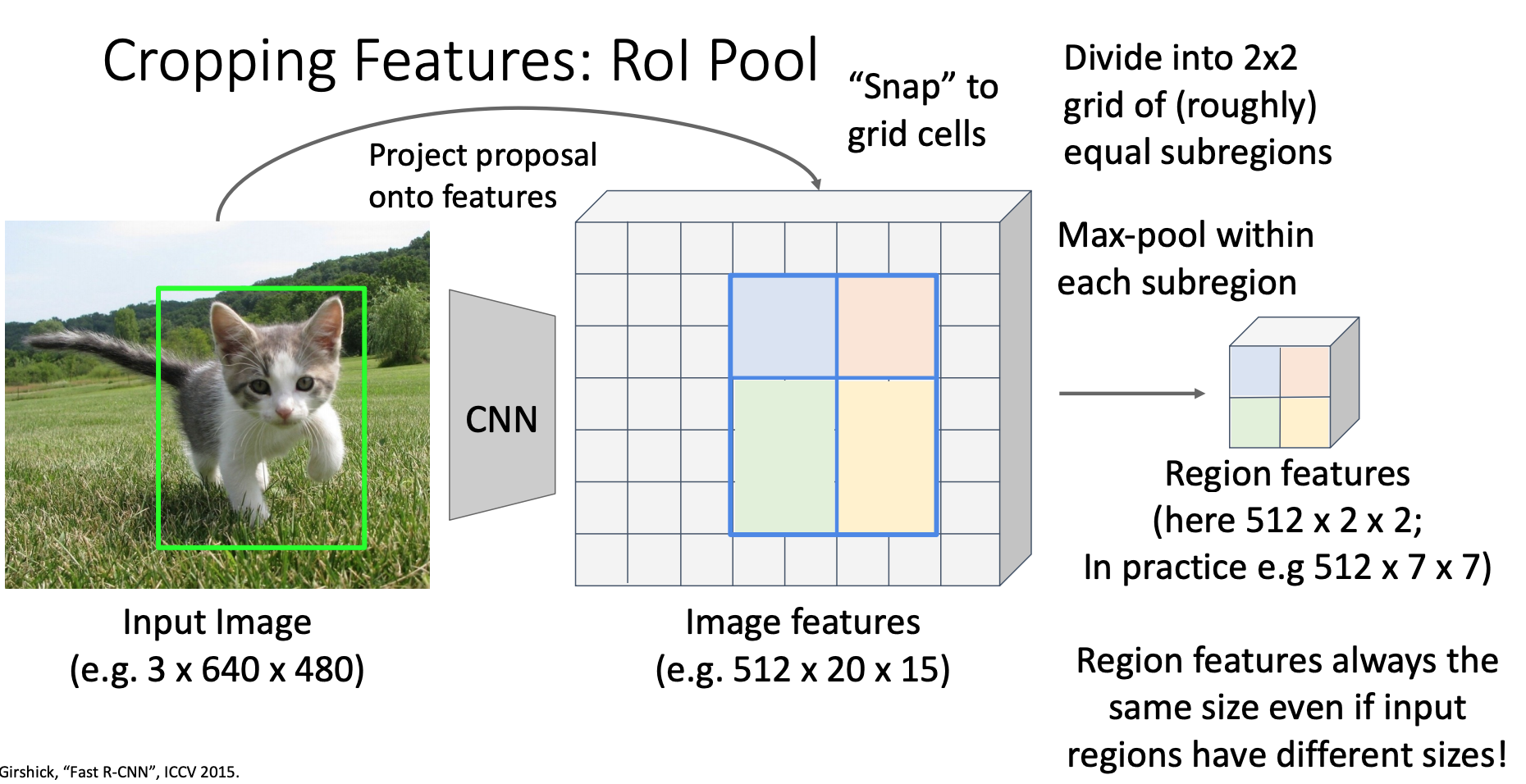
이 하부 영역들에 대해서 최대 풀링을 하겠습니다. 여기서 파란색 영역은 512 x 2 x 2가 되고, 최대 풀링을해서 출력 결과는 단일 512차원의 벡터가 되겠습니다. 녹색 영역의 경우 512 x 3 x 2 크기고, 출력 결과는 512차원의 벡터가 되겠습니다. 이 의미는 입력 제안 영역이 다른 크기를 가지고 있더라도 RoI Pool 여산자의 출력은 항상 고정된 크기를 가지며, 이것을 영역별 연산을 수행하는 이후 합성곱 레이어에 전달되서 동작하겠습니다.
다시 역전파의 경우에도 일반적인 최대 풀링의 역전파가 적용되겠습니다. 영역 특징에 대해서 업스트림 그라디언트를 받으면 해당하는 이미지 특징의 영역으로 전파됩니다. 그리고 우리가 아주 많은 영역을 가지는 배치로 학습을 할때, 대부분의 이미지 특징의 그라디언트들을 얻을수가 있겠습니다.

여기서 약간의 문제가 있는데, 스냅할때 약간의 비정합 문제로 녹색 영역 파란 영역이 다른 사이즈를 가질 수도 있어요.

사람들이 사용하는 조금 더 복잡한 버전으로 roi align이 있는데, 아주 자세한 내용을 다루기는 싫지만









이 방법은 스냅하는 대신에 잘 정합 할 수 있도록 양선형 보간법을 사용합니다. roi align은 쉬우며

입력 특징과 출력 특징 간에 더 나은 정합 결과를 만들어 낼수가 있겠습니다.

이번에는 fast r-cnn과 slow r-cnn을 한번 살펴보겠습니다. 이들 사이의 차이는 합성곱 연산과 크롭 그리고 워핑의 순서를 바꾼것인데요. fast r-cnn은 제안 영역들의 연산을 공유/한번에 하기 때문에 빠르며 fast r-cnn이 얼마나 빠르냐면

한번 훈련 시간과 추론 시간을 비교해볼수가 있겠습니다. r-cnn을 학습하는 경우에는 84시간이 걸렸습니다. 당연히 몇년 전이고 옛날 gpu를 사용했기 때문인데 faster r-cnn을 같은 gpu 환경에서 한 경우에 훈련하는데 10배 정도 빨라졌습니다.
추론 시간의 경우 fast r-cnn은 r-cnn보다 다양한 이미지 영역들을 한번에 계산하기 때문에 훨씬 빨라졌습니다. 여기서 흥미로운 부분은

fast r-cnn은 대부분 시간을 제안 영역을 계산하는데 소모합니다. 제안 영역은 선택적 탐색이라고 부르는 경험적/휴리스틱 알고리즘을 사용하기 때문인데 이 알고리즘이 cpu에서 동작하기 때문입니다. 그래서 이 fast r-cnn을 보면 동작 시간의 90%가 이 제안 영역을 계산하는데 사용하고 있어요.

여기서 경험적 알고리즘으로 제안 영역을 구하는 대신 이걸 합성곱 신경망으로 대체해서 구하면 더 효율적이게 되겠죠. 그러면 이 객체 인식 시스템을 훨씬 개선할수 있겠습니다.
'번역 > 컴퓨터비전딥러닝' 카테고리의 다른 글
| 딥러닝비전 15. 객체 검출 - 4. Faster R-CNN, RPN, 단일 단계 객체 탐지 (0) | 2021.04.06 |
|---|---|
| 딥러닝비전 15. 객체 검출 - 2.비최대 억제를 이용한 겹치는 영역 제거, 객체 검출기 평가 척도 mAP (0) | 2021.03.30 |
| 딥러닝비전 15. 객체 검출 - 1. 단일 객체 검출, 슬라이딩 윈도우, R-CNN, IoU (0) | 2021.03.30 |
| 딥러닝비전 14. 합성곱 신경망의 시각화와 이해 - 2. 활성 시각화, 최대활성패치, 중요 픽셀 시각화 (0) | 2021.03.25 |
| 딥러닝비전 14. 합성곱 신경망의 시각화와 이해 - 1. 필터 시각화와 차원 축소 (0) | 2021.03.25 |