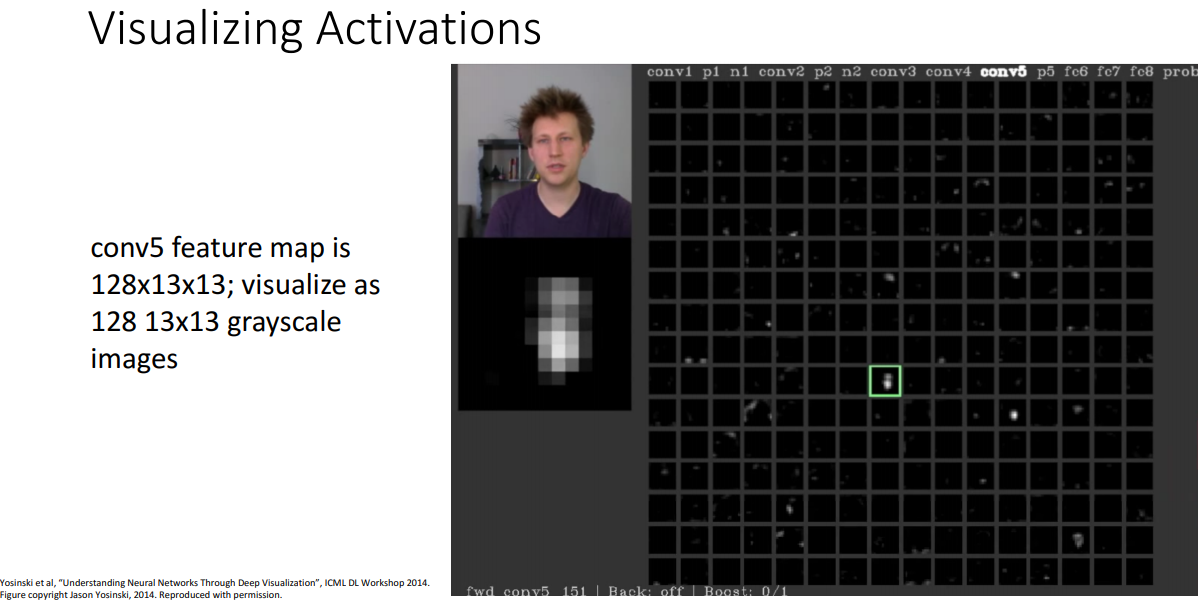
신경망이 무엇을 찾고 있는지 이해하기위해서 우리가 사용해볼수 있는 또 다른 방법으로는 신경망의 가중치가 아닌 신경망의 중간 활성값을 시각화해보는 방법입니다. 이전에 합성곱 신경망을 공부했던걸 떠올려보면, 신경망의 각 계층에서는 활성값을 계산하며 마무리합니다.
한번 알렉스넷의 5번째 합성곱 계층 예를 들면, 여기서 13 x 13 크기의 128채널의 값을 계산하는데, 이는 알렉스넷의 5번째 합성곱 계층에서 128개의 필터가 있고, 각 필터들은 13 x 13 그리드 형태의 값들을 가지게 됩니다. 여기서 우리가 해볼수 있는건 13 x 13 크기의 활성값들을 흑백 이미지로 시각화해볼수 있어요.
여기서의 개념은 필터의 값이 0에 가깝고, 렐루 함수를 통과시키면, 대부분의 값들이 0이 될겁니다. 하지만 특징 맵이 0이 아니라면, 입력 이미지가 들어오면 서로 다른 합성곱 필터들이 입력 이미지의 어떤 특징에 반응을하는지 이해할수 있습니다.
여기서 진행한 시각화결과를 보면 128개의 합성곱 필터의 활성 결과들을 볼수 있는데, 필려의 출력 중 하나로 녹색 부분을 골라 봅시다. 왼편에 원본 이미지와 아래에 시각화결과가 있어요. 그러면 13 x 13 그리드의 영역들에서 이 필터가 입력 이미지의 사람 얼굴 부분을 따라 활성된것을 볼 수 있습니다. 이는 신경망 한 레이어의 한 필터가 정확하다고 하기는 힘들지만 사람의 얼굴 혹은 사람의 피부톤에 반응한게 되겠습니다.
서로 다른 이미지에 대해서 여러 레이어의 활성 결과들을 이용해서 서로 다른 필터가 무엇에 반응하는지 이해할수 있겠습니다.
(질문) 필터들의 활성 결과가 왜 대부분이 검은색일까요?
저의 생각에는 렐루 비선형 함수 때문입니다. 랠루 함수를 다시 떠올려보면 음수 값이 들어오는경우 0이 나오게 되고, 양수만 남게 됩니다. 그렇다보니 많은 값들이 0이 되고, 0이 아닌 부분들은 꽤 중요하다고 볼수 있겠습니다. 또 이건 시각화의 산물이라고도 할수 있는데, 신경망이 0 ~ 무한대의 실수 값을 출력하는데, 시각화할때 0에서 255로 줄여내기 때문입니다. 그래서 출력을 어떻게 줄여나갈지에 따라서 이미지의 전반적인 밝기에 영향을 줄 수 있어요.

임의의 이미지나 임의의 필터를 보는게 아닌 다른 해볼수 있는 방법으로는 최대 활성 패치 Maximally Activating Patches로 이건 신경망에서 최대로 활성화하는 패치를 말합니다.
이전 슬라이드에서 우리는 신경망 한 계층의 이 필터가 얼굴에 반응하는걸 배웠습니다. 그래서 우리가 전체 테스트셋에 대해서 가설 검정을 하고싶을때 우리가 해볼수 있는건,
전체 훈련셋을 가지고 와서, 전체 훈련셋과 테스트셋을 신경망에다가 돌리는데, 레이어와 필터를 골라 그 레이어에서의 필터의 값을 저장합니다. 우리는 이미 합성곱 신경망에서 특징 그리드의 각 원소들은 입력 이미지의 유한한 크기의 패치와 대응되는걸 알고 있어요. 3 x 3 합성곱 계층의 경우 입력 이미지의 3 x 3 크기의 덩어리로 계산하고, 여기다가 3 x 3 합성곱 층을 쌓으면, 입력 이미지의 5 x 5 크기의 부분의 영향을 받아요.
그래서 우리가 해볼건 레이어와 필터를 선택하고, 전체 훈련/테스트셋을 돌려보고, 테스트셋 이미지의 패치중에서 우리가 선택한 필터에 가장 크게 반응하는 패치들을 찾아냅니다. 그리고 이것들을 기록하면됩니다.
오른쪽에 시각화한 결과물들이 있는데, 위의 그리드는 신경망의 한 레이어에 들어온 입력들을 보 여기서 각 행은 그 레이어에 있는 한 필터에 대응하는 것들이며, 한 행의 각 컬럼 요소들은 이미 학습된 신경망의 선택된 레이어와 필터에 아주 아주 크게 반응하는 훈련 이미지의 패치입니다.
그래서 이들은 신경망에서 선택된 뉴런을 최대로 활성화하는 테스트 셋 이미지들의 패치들이기도해요. 최대 활성 패치를 시각화함으로서 뉴런들이 무엇을 찾는짖 이해할수 있습니다. 예를들면 맨 위에있는 행을보면 강아지의 코처럼 생긴것들이 있는데, 그러면 이건 강아지의 코를 찾는 뉴런이라고 할수 있겠습니다.
위 그리드의 4~6번째 행은 모두 영어 단어나 텍스트 패치로, 이 텍스트들은 전면과 후면이 다른 색상과 다른 방향을 가지고 있어요. 즉, 심층 신경망에서 선택된 이 필터는 서로다른 색상과 방향을 가진 텍스트를 찾는걸 알수 있겠습니다.
아래의 그리드에서도 같으나 더 깊은 레이어에서 동작하는 실험을 해보았습니다. 신경망의 더 깊은 계층에서 실험을 하다보니 각 뉴런의 값은 입력 이미지의 더 큰 패치로 구한다(입력으로 부터 멀수록 수용장은 커지므로). 그래서 심층 레이어에서의 최대 활성 패치는 더 커지게 되겠다.
아래 그리드에서 두번째 행을보면 모든 최대 활성 패치들은 사람 얼굴인데, 이 얼굴들이 다른 피부색상, 다른 위치에 있다. 하지만 깊은 곳에있는 한 뉴런 혹은 한 필터가 학습한 결과 어떻게든 사람 얼굴을 인식하게 되었습니다.

최대 활성 패치 기법으로 신경망의 중간 계층에서 어떻게 인식되는지 이해하기위한 또 다른 방법을 얻을수가 있는데, 신경망이 무엇을 계산하는지 이해히기 위해 해볼수 있는 다른 방법으로 입력 이미지의 어떤 픽셀들이 분류 문제에 중요한것인가를 찾는방법이 있습니다.
여기서 우리가 해보려는건 왼쪽에 코끼리의 이미지가 있고, 이 코끼리 이미지가 학습된 신경망에서 올바르게 코끼리로 분류되었다고 가정합시다. 이제 우리가 알고자하는건 입력 이미지의 어떤 픽셀들이 신경망이 코끼리로 분류하는걸로 결정을 내리는데 중요한가가 되겠습니다.
그래서 우리가 해볼수 있는 방법은 코끼리 이미지를 준비해서 이미지의 일부 픽셀을 회색 사각형이나 혹은 균일한 색상으로 바꾸고, 이 마스크 처리 된 이미지를 신경망에다가 돌려보면 됩니다. 그렇게 하면 신경망이 마스크화된 이미지를 무엇으로 분류하기를 원하는지에 대해 갱신된 스코어를 얻을수가 있습니다. 이 사각 마스크를 다른 위치로 이동시키면서 이 과정을 반복할수 있고, 서로 다른 마스크 이미지들을 신경망에 돌리겠습니다.

모든 위치의 경우로 마스크를 이동시키면서 이 과정을 반복하면 각 지점에서 코끼리의 확률을 계산해내고, 이걸 saliency map으로 만들어낼수 있습니다. 이건 어떤 픽셀이 분류에서 중요한지를 알려줘요. 오른쪽에 이 이미지가 있는데, 입력 이미지의 모든 지점에다가 마스크를 넣어보고 마스크된 이미지를 신경망에 돌린 결과를 코끼리일 확률에 대한 히트맵으로 만들었습니다.
여기서 알수 있는점은 코끼리부분에다가 마스크를 한경우 코끼리로 예측할 확률이 떨어지는걸 볼수 있으며, 이는 신경망이 분류 결정을 할때 이미지의 올바른 부분을 보았다고 할수 있겠습니다.
이러한 실험을 다른 두 이미지로 반복해보았습니다. 위의 스쿠너(범선)이미지인데 배가 있는 부분에 마스크를하면 신경망이 스쿠너 클래스로 분류할 확률이 아주 떨어지는걸 볼 수 있고, 하늘에다가 마스크를 한 경우에는 크게 중요하지 않다보니 신경망이 크게 신경쓰지 않으며 여전히 스쿠너로 올바르게 분류할수 있습니다.
이러한 방식은 우리가 신경망이 어떻게 동작하는지 이해하고자 할때, 어떤것들이 중간 특징들을 활성시키는지 보는것대신 입력 이미지를 단순히 변형시키고, 입력이미지의 어떤 부분이 신경망이 올바르게 분류하는데 사용하는지 볼수 있었습니다.
여기서 놀라운 점은 신경망은 이미지의 어떤 부분이 물체인지 혹은 배경인지 알 필요가 없는것이며, 신경망이 단지 모든 스쿠너들이 특정 색상의 물위에 항상 있다면 배를 자체를 보지 않고 물의 색상만을 보고 스쿠너로 분류할수도 있습니다.
만약 우리가 가진 데이터셋이 신경망이 치팅할수 있는것이라면, 신경망이 이미지의 엉뚱한 부분을보고 올바른 정답을 말할수 있는 데이터셋이라면 신경망은 쉽게 치팅하도록 학습을 할 것이고, 이러한 경우 시각화 할 시 신경망이 치팅을 하는지 그렇지 않고 이미지의 올바른 부분을 보고 결정을 하는지를 알수 있겠습니다.
(질의응답) 이건 나쁜 방법.
saliency map을 마스킹으로 구하는것은 가능한 모든 위치에다가 마스크를 놓고 계산을돌려야하다보니 계산 비용이 아주 큰 문제가 있음.

다른 방법으로 역전파를 이용해서 saliency map을 구할수 있습니다. 입력으로 귀여운 강아지 임지를 준비하고, 신경망으로 돌려 강아지일 확률을 계산하겠습니다.

그리고 역전파를 하는동안 강아지일 스코어와 입력 픽셀들 사이의 그라디언트를 계산할 수 있는데, 이는 입력 이미지의 모든 픽셀들이 약간 변할때 신경망의 맨끝에서 강아지 분류 스코어에 얼마나 영향을 미치는지 알려준다. 이건 적대적 예시로서 생성하는데 사용할수 있는 이미지의 그라디언트로, 이 예시의 경우 유령같은 그라디언트 이미지를 시각화해서 볼수 있으며, 각 픽셀은 강아지 스코어에 대한 각 픽셀들의 그라디언트가 되겠다.
이 그림을 보면 강아지의 윤곽선 같은게 보이고, 분류 스코어에 영향을주는 픽셀들은 주로 강아지 안에 있는걸 알수 있겠다. 강아지 밖에 있는 픽셀이 변하더라도 분류 스코어는 크게 변하지는 않겠다. 이런 방법을 통해서 신경망이 이미지의 올바른 부분을 보고있는걸 알수 있다.

강아지 이미지 말고도 다른 이미지에다가도 적용하여 다른 이미지에서 어떤 픽셀들을 신경망이 중요하게보는지에 대한 saliency map을 얻을수도 있습니다. 이 예시들에서 짚고 넘어가고 싶은 부분은 이 논문에서 소개된 이 기술은 대부분의 실제 예시에서는 좋은 결과가 나오지 못하고 있습니다. 그래서 과제를 하면서 생각보다 좋지 못한 결과가 나와서 놀랄수도 있어요.
이건 버그가 있는게 아니라 논문 저자가 예시를 신중하게 골른것이고, 하지만 여전히 신경망이 무엇을 학습하는지 이해하는데 꽤 좋은 방법이라 생각합니다.

saliency map을 잘 동작하도록 하기위한 방법으로 이미지에 있는 물체를 어떠한 지도없이 분리시키는것인데요. 여기에 메뚜기 이미지가 있는데 이걸 신경망에다가 넣고, 신경망은 이미지가 메뚜기로 분류할거에요.
이제 우리가 할일은 입력이미지로부터 메뚜기 이미지 부분 픽셀들을 구하는것인데, 우리가 해볼수 있는 일은 saliency map를 사용해보면 됩니다. 신경망으로 계산하여 saliency map을 구하고, 영상 처리 기술(위 슬라이드에서는 grabcut 사용)을 적용합니다. 그러고 나서 다시 이미지 분류로 학습된 신경망을 객체 카테고리에 해당하는 입력 이미지의 색션으로 분할하는 용도로 사용합니다.
제가 아까 이야기했지만 여기서 고른 예시들은 잘 동작하지만 이 기술은 일반적인 경우에는 잘 동작하지 않을수 있습니다. 하지만 각 픽셀에 대한 그라디언트 정보를 계산하는 이 방법, 이미지에서 픽셀의 변화가 얼마나 최종 스코어에 영향을 주는지 계산하는 것은 신경망이 어떻게 동작하는지 이해하는데 매우 유용하다고 할수 있겠습니다.

이번에 살펴볼 방법은 이미지의 픽셀이 최종 클래스 스코어 어떤 영향을 미치는가가 아니라 신경망 안에 있는 중간 특징들이 무엇을 찾고 있는지에 대한 질문으로 되돌아가서 봅시다. 이 질문에 대한 대답으로 우리는 그라디언트 정보를 사용할수가 있어요.
여기에 우리가 해볼수 있는것으로 신경망의 어느 레이어를 선정하고, 어떤 필터를 골라봅시다. 여기서 할일은 훈련 이미지나 테스트 이미지를 신경망에다가 넣어서 돌리면서 역전파를 하겠습니다. 그런 다음에 입력 이미지의 어느 픽셀이 최종 클래스 스코어에 영향을 주었느냐가 아니라 어느 중간 뉴런 값이 영향을 주었느냐를 보겠습니다.
제가 입력 이미지의 픽셀들을 바꾼다면 중간에 있는 뉴런들의 값이 올라갈거나 내려가게 되겠죠.

(질문) saliency map은 훈련전의것인가요? 훈련 후의 것인가요?
saliency map을 훈련 전에 구해보면 아주 좋지않은 결과가 나옵니다. 합성곱 구조는 계산 과정에 있어서 강한 규제 효과를 가지다보니 학습 전이라해도 saliency map을 구하면, 여러분들이 훈련 전에 시각화하더라도 좋은 결과를 얻기는 힘들고 아마 랜덤한 결과가 나오겠습니다.
그래서 이렇게 그라디언트 정보를 사용해서 중간에 있는 특징이 무엇을 찾는지 이해하는 것과 같은 아이디어를 사용해서, 코끼리 입력 이미지를 신경망에 넣어 중간 레이어까지 돌림으로서 최종 스코어까지 역전파하는게 아니라 이 중간 뉴런의 값에 대한 역전파가 어떤 입력 이미지의 픽셀이 이 중간 출력 뉴런에 가장 영향을 주는지 알려줍니다.
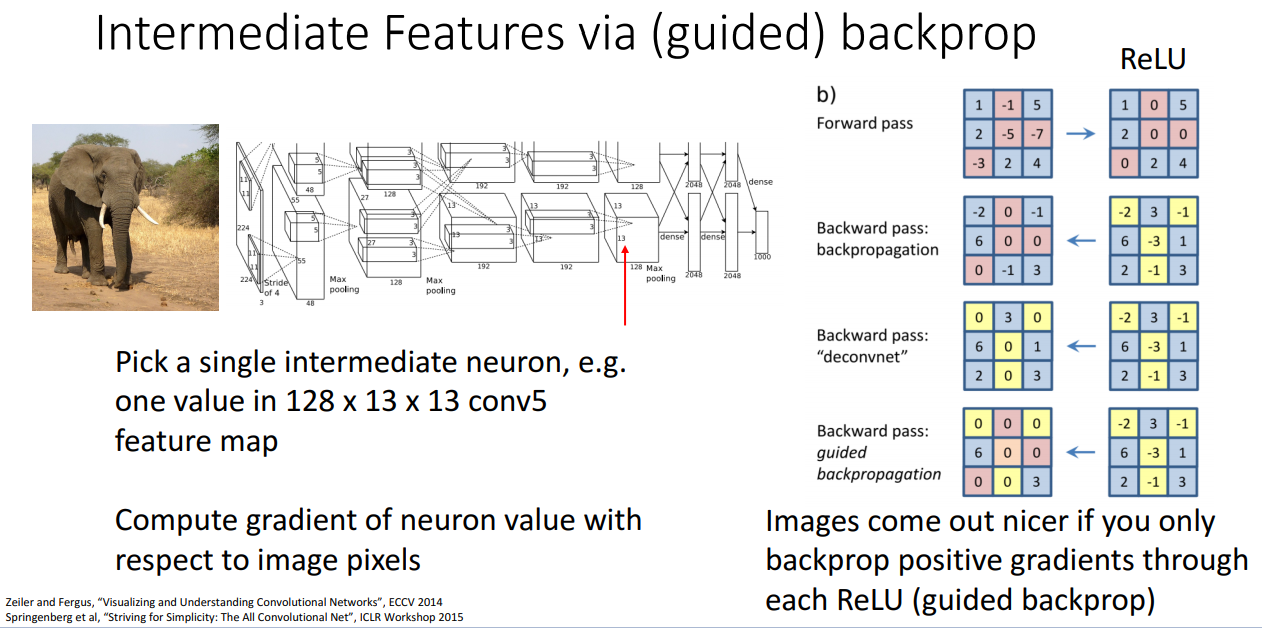
일반적인 역전파 방법으로 구한 중간 특징에 대한 결과가 좋지 않게 나오다보니, 연구자들이 guided back propagation이란 방법을 사용하였습니다. 이게 왜 동작하는지 완전히 이해할수는 없지만 좋은 결과가 나옵니다.
이 guided back propagation이라는 개념은 우리가 알다시피 순전파를 할때 0이하의 값은 모두 0으로 설정되고, relu를 역전파로 통과 시 순전파 때 0이 되었던 위치들이 마스크처럼 적용되서 업스트림 그라디언트로부터 온 값들이 0이 됩니다. 업스트림 그라디언트에 (0마스크를) 적용한게 relu함수의 일반적인 역전파가 되겠습니다.
이번에는 guided backpropagation에서는 relu 함수를 역전파로 통과시에 거기다가 음수의 업스트림 그라디언트에다가도 마스크처리를 합니다. 다시말하면 relu 함수를 역전파할때 해당하는 모든 업스트림 그라디언트의 값은 0이 되고, 거기다가 음수인 업스트림 그라디언트도 0이 되요. 즉, 추가적인 마스킹으로 모든 음의 업스트림 그라디언트도 제거하는게 되겠습니다. 저도 이런 방식으로 이미지를 시각화하는데 역전파를 사용할때 더 좋은 결과가 나오는지 모르겠습니다.

아무튼 이런 guided back propagation을 이미지에 적용하면, 뉴런 값에 변화를 주는 이미지의 픽셀들을 잡아낼수 있다. 왼쪽 그림이 최대 활성 패치들이면, 우측에 있는 것들이 guided back propagation을 적용해서 이 패치의 어떤 픽셀들이 뉴런에 영향을 주는지 찾아낸 결과이다. 맨 윗 행의 결과들을 보면 이 뉴런들이 강아지의 코나 눈을 찾고 있는걸 알수 있고, guided backpropagation의 결과를 보면 이러한 것들이 뉴런 값에 큰 영향을 주는걸 확인할 수 있다.

더 깊은 신경망 레이어의 최대 활성 패치들을 구해서 또 적용시켜보면 비슷한 결과를 얻을수가 있다. 이전에 사람 얼굴을 찾았던 뉴런을 봤었는데, 사람 얼굴의 픽셀을 위주로 보는것을 확인할수 있다. 이 방법은 테스트셋의 이미지나 패치에 한정해서 본 것이고 더 나아가서

guided back propagation으로 테스트셋 이미지에다가 이미지의 어떤 픽셀이 뉴런 값에 영향을 주는지 찾아내었는데, 테스트 이미지셋만 보지말고 모든 가능한 이미지들 중에서 어떤게 이미지가 최대로 뉴런 값을 찾아내는지 볼수 있습니다. 그래서 뉴런의 값을 최대화 시키는 syntetic image를 생성해보겠습니다.
이걸 이미지 픽셀들에 대해서 경사 상승으로 만들어 낼 수가 있는데, 위 슬라이드의 I*가 특정 뉴런을 최대화 시키도록 생성한 이미지이고, f(I)는 이미지가 주어질때 특정 뉴런의 값, R(I)는 생성한 이미지가 자연스럽게 하기 위한 규제자가 됩니다. 이 식은 신경망 가중치를 학습할때 본것과 비슷한데, 여기서 하고자 하는건 가중치를 갱신하는게 아니라 중간에 있는 특징 중 하나를 최대로 활성 시키는 이미지를 구하는게 되겠습니다. 이 이미지는 경사 상승 알고리즘을 통해서 구할수 있는데 이미지를 그라디언트 정보로 조금씩 바꿔가면 되요.

이걸 하기 위해서 우선 0이미지나 랜덤 노이즈로 초기화하고, 이 이미지를 신경망에다가 돌린뒤 선택한 뉴런의 값을 구합니다. 그리고 역전파를 통해서 이미지의 어떤 픽셀들이 뉴런값을 변화시키는지 찾아내요. 이미지를 약간 갱신시키고, 이 과정을 반복함으러서 선택한 뉴런이 큰값을 갖도록 영향을 주는 인공 이미지가 만들어집니다.

'번역 > 컴퓨터비전딥러닝' 카테고리의 다른 글
| 딥러닝비전 15. 객체 검출 - 2.비최대 억제를 이용한 겹치는 영역 제거, 객체 검출기 평가 척도 mAP (0) | 2021.03.30 |
|---|---|
| 딥러닝비전 15. 객체 검출 - 1. 단일 객체 검출, 슬라이딩 윈도우, R-CNN, IoU (0) | 2021.03.30 |
| 딥러닝비전 14. 합성곱 신경망의 시각화와 이해 - 1. 필터 시각화와 차원 축소 (0) | 2021.03.25 |
| 딥러닝비전 13. 어텐션 - 6. 트랜스포머 (0) | 2021.03.22 |
| 딥러닝비전 13. 어텐션 - 5. 셀프 어텐션을 이용한 CNN과 시퀀스 처리 방법들 (0) | 2021.03.22 |