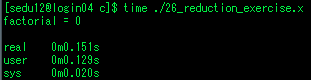
728x90
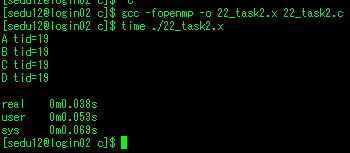
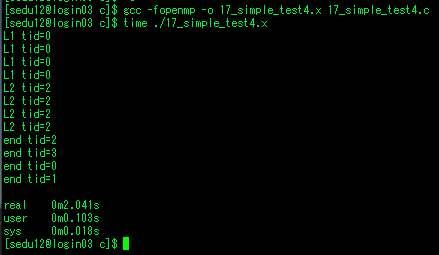
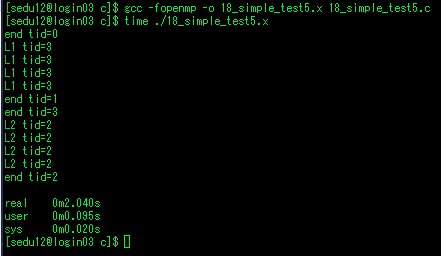
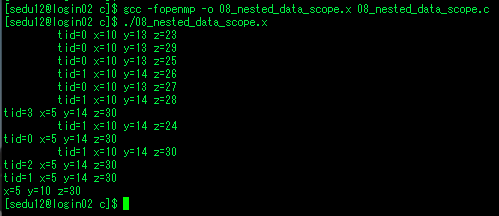
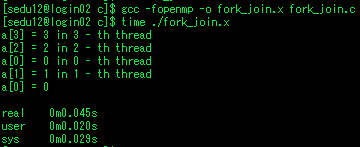
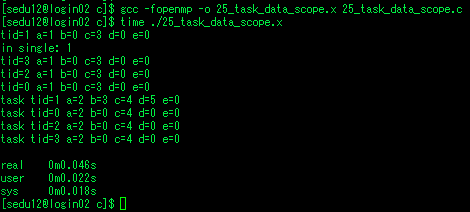
테스크 데이터 유효범위
- 지정하지 않은것들은 기본적으로 shared
- parallel에서 bde tid가 private -> a와 c는 shared
- single에서 스레드 하나만 a=2, b=3, c=4, d=5, e=6으로 할당.
- a와 c는 shared이므로 다른 스레드도 영향받음, 나머지 bde는 그대로 0
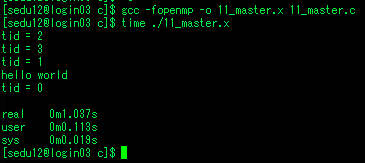
#include <stdio.h>
#include <omp.h>
int main()
{
int a=1, b=2, c=3, d=4, e=5, tid;
omp_set_num_threads(4);
#pragma omp parallel private(b,d,e, tid)
{
tid = omp_get_thread_num();
printf("tid=%d a=%d b=%d c=%d d=%d e=%d\n", tid, a, b, c, d, e);
#pragma omp single
{ printf("in single: %d \n", tid);
a=2, b=3, c=4, d=5, e=6; }
#pragma omp task private(e)
{
printf("task tid=%d a=%d b=%d c=%d d=%d e=%d\n", omp_get_thread_num(), a, b, c, d, e);
}
}
}
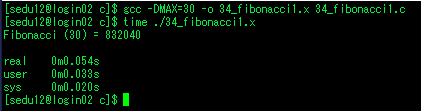
단순 피보나치
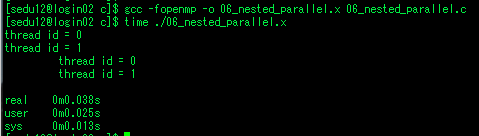
#include <stdio.h>
int fibon(int n) // f(n) = f(n-1) + f(n-2)
{
int x, y;
if(n<2) return n;
x=fibon(n-1);
y=fibon(n-2);
return (x+y);
}
int main()
{
int result = fibon(MAX);
printf("Fibonacci (%d) = %d\n", MAX, result);
return 0;
}
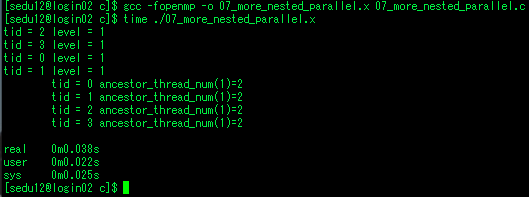
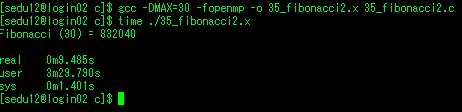
재귀 프로그래밍으로 구현한 피보나치 태스크
- 9.485s 소요
#include <stdio.h>
int fibon(int n) // f(n) = f(n-1) + f(n-2)
{
int x, y;
if(n<2) return n;
#pragma omp task shared(x)
{ x=fibon(n-1); }
#pragma omp task shared(y)
{ y=fibon(n-2); }
#pragma omp taskwait
return (x+y);
}
int main()
{
#pragma omp parallel
{
#pragma omp single nowait
{
printf("Fibonacci (%d) = %d\n", MAX, fibon(MAX));
}
}
return 0;
}
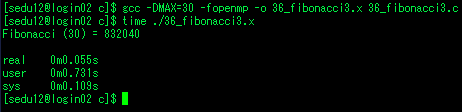
재귀 프로그래밍으로 구현한 피보나치 태스크
- n < 30구문 아래의 x,y 계산은 조건문 안의 함수가 다 호출된 후 순서대로 시작 => n<30인 경우 시리얼로 처리
- n >= 30은 테스크로 처리
#include <stdio.h>
long int fibon(int n) // f(n) = f(n-1) + f(n-2)
{
long int x, y;
if(n<2) return n;
if(n<30){
return fibon(n-1)+fibon(n-2);
}
else
{
#pragma omp task shared(x)
{ x=fibon(n-1); }
#pragma omp task shared(y)
{ y=fibon(n-2); }
#pragma omp taskwait
return (x+y);
}
}
int main()
{
#pragma omp parallel
{
#pragma omp single nowait
{
printf("Fibonacci (%d) = %ld\n", MAX, fibon(MAX));
}
}
return 0;
}
300x250
'컴퓨터과학 > 기타' 카테고리의 다른 글
| matplotlib - 2. 1x2, 2x2 subplots (0) | 2020.08.25 |
|---|---|
| matplotlib - 1. 단순한 subplots (0) | 2020.08.25 |
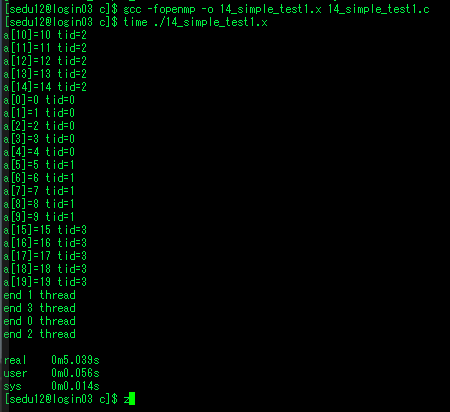
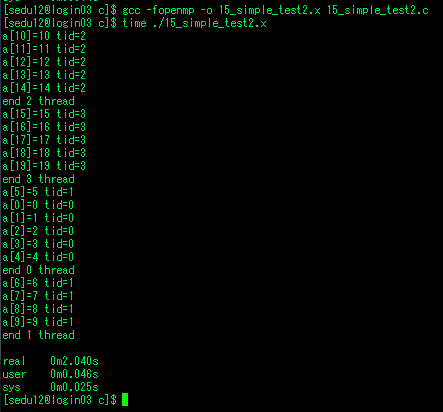
| openmp - 24. 테스크 (0) | 2020.07.30 |
| openmp - 23. 스캐줄링과 만델브로트 (0) | 2020.07.30 |
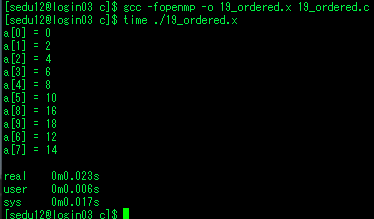
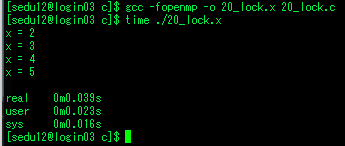
| openmp - 22. ordered, lock (0) | 2020.07.30 |