실습 과제물...
1. fluentd와 몽고db로 로그 취합하는 시스템 구축
2. jupyter/datascience-notebook or jaimeps/rl-gym 등 데이터 사이언스 관련 컨테이너를 public cloud에서 구동하고 jupyter에서 접속한다.
3. pytorch를 설치한 이미지로 컨테이너를 구동한다.
www.docker.com/resources/what-container
도커란 무엇인가
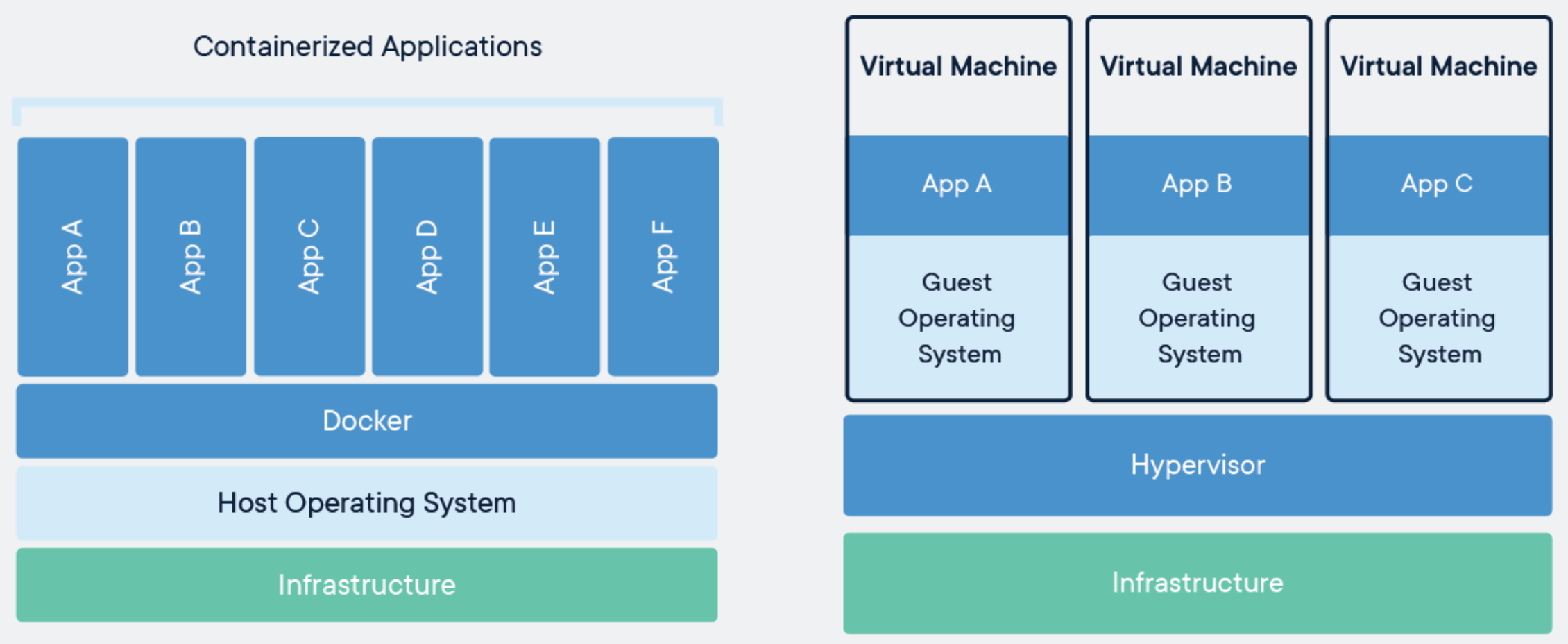
컨테이너
- 의존성과 패키지코드가 함께 있는 추상화
- 각 머신처럼 동작 가능. os 커널은 공유
클라우드 컴퓨팅
- aws, 에저, 구글 클라우드 엔진
=> 구글 클라우드 엔진이 후함
console.cloud.google.com/
도커 설치하기
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
$ sudo apt-get update
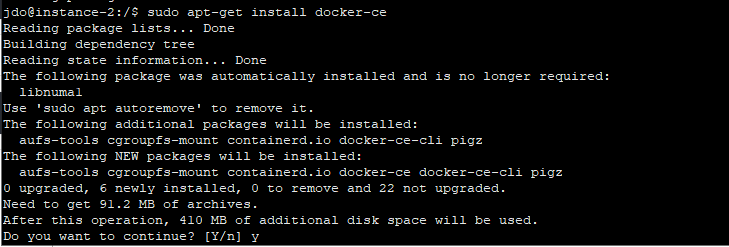
$ sudo apt-get install docker-ce
ref: docs.docker.com/engine/install/ubuntu/
Install Docker Engine on Ubuntu
docs.docker.com
도커에는
이미지와 컨테이너가 있다..
컨테이너 들어오기
docker run -i -t ubuntu:14.04
* -i : interactive
* -t : terminal
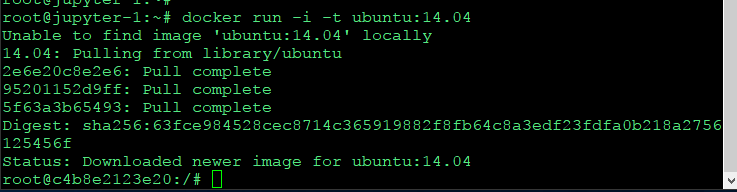
기존 환경에서 우분투 14.04 컨테이너로 들어왔다.
exit 명령의 경우 컨테이너 자체가 종료된다.
컨테이너
어플리케이션 실행하고 싶은데 실행하기 위한 공간
ctrl pq를 하면 다시 컨테이너 밖으로 나온다..
(exit와 달리 컨테이너 종료 x)
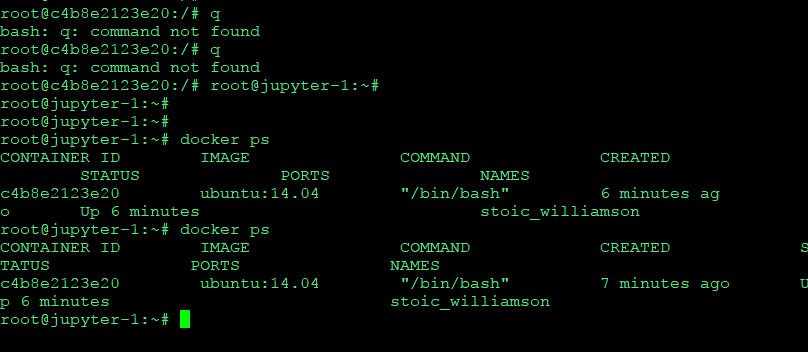
다시 캡처해서 보면
아까 컨테이너가 살아있다.

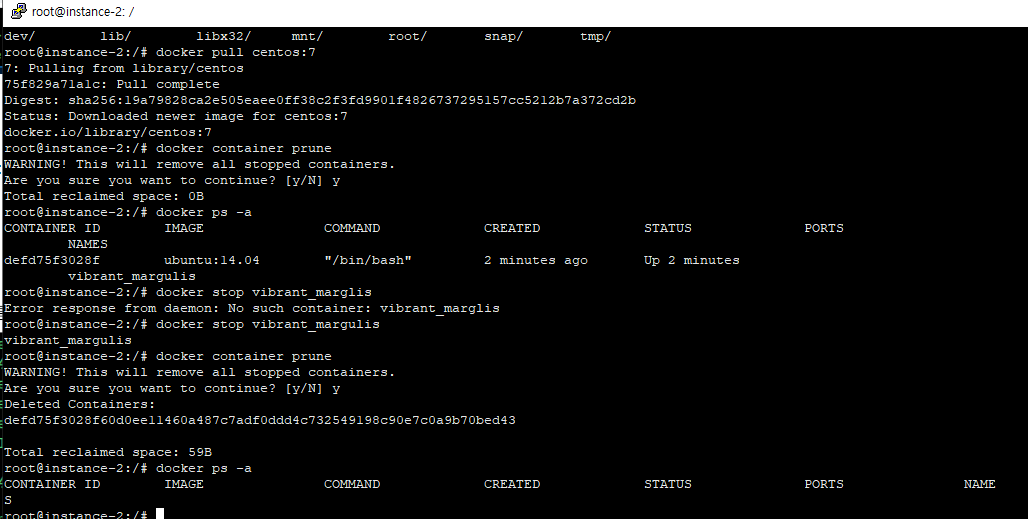
docker ps -a
exit 시킨 컨테이너도 나온다.

docker rm {id, name} 컨테이너 삭제하기.
삭제하려했더니 동작중이라 한다

docker stop id/name
stop부터 해주고 다시 삭제
stoic_williamson 컨테이너 삭제 ok

centos 이미지 가져오기
docker pull centos:7

docker image ls
- 가지고 있는 이미지 목록 보기
-> 우분투 버전 14.04와 센토스 7이 추가되어있다.

docker run -it centos:latest
센토스 컨테이너에 들어왔다가
다시 컨트롤 pq로 나오자.

docker ps해보면 centos:latest가 돌아가고있다.

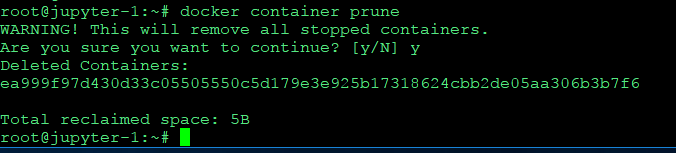
docker container prune
쓰지 않는 컨테이너 지우기
docker attach 아이디/이름 : 다시 컨테이너 들어가기
이미지 생성하기
docker create -it --name (이름) (기본 이미지;centos:latest)
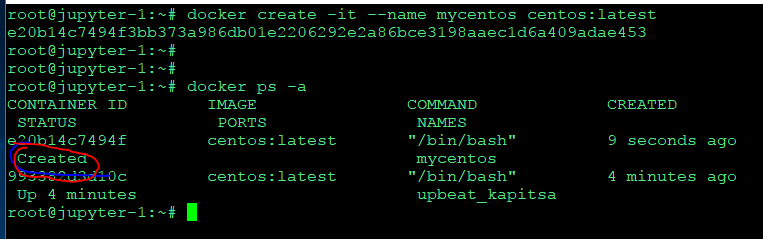
다시 시작하기
docker start 이미지/id

웹서버 돌리기
컨테이너 80포트와 호스트 80포트 바인딩 시켜서 돌리기

컨테이너는 휘발성
이미지를 만들자.
놓침 ㅠㅠ
도커 이미지
- 레지스트리에서 관리
public, private, docker hub 같은대
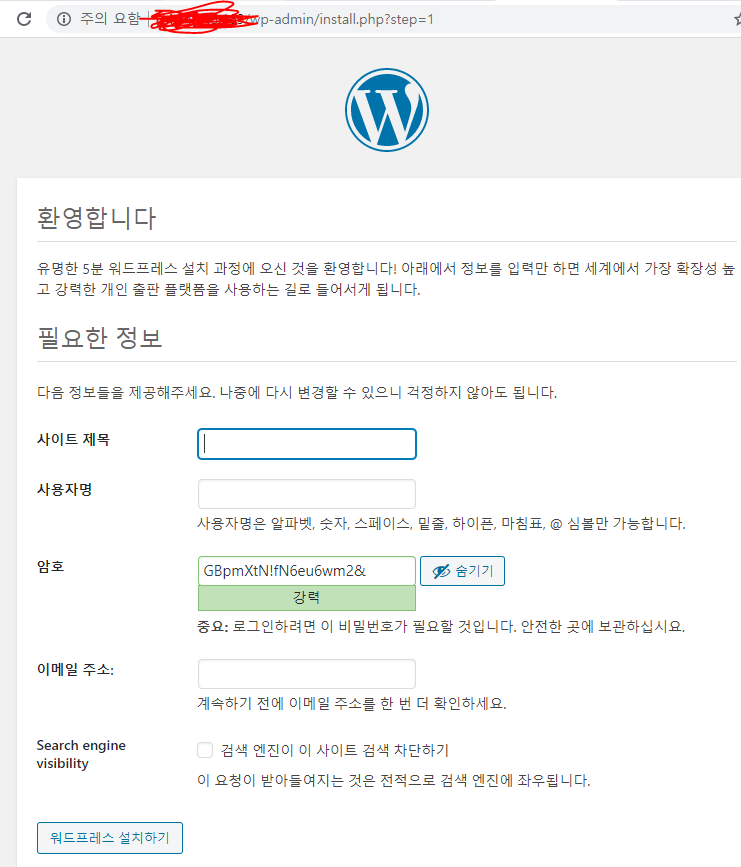
wordpress 돌리기'
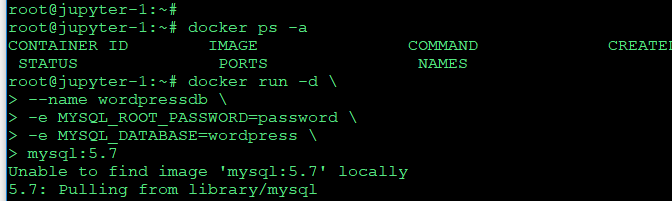
먼저 워드프레스용 db 부터 준비
mysql 돌리기, 환경변수도 다음과같이 수행
docker run -d --name wordpressdb -e MYSQL_ROOT_PASSWORD=password -e MYSQL_DATABASE=wordpress mysql:5.7
'
https://hub.docker.com/_/mysql
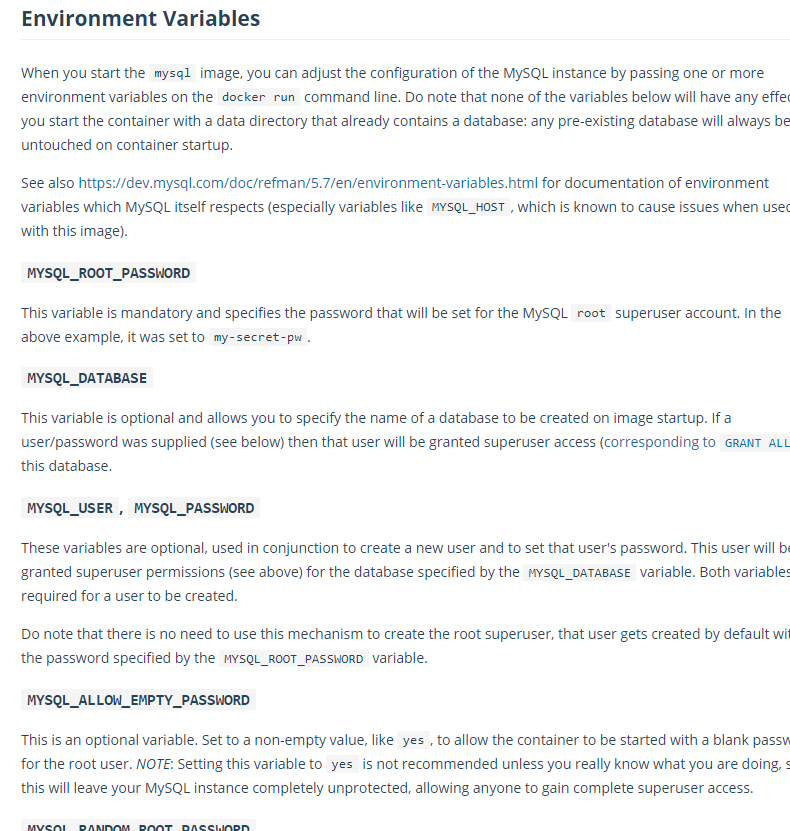
wordpress db가 잘돌아가고있다..
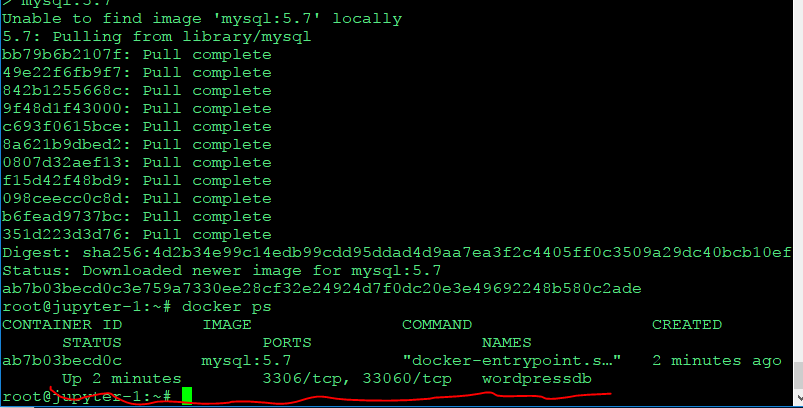
'
이런식으로 컨테이너에 들어갈수도 있다.
docker exec -it wordpressdb /bin/bash
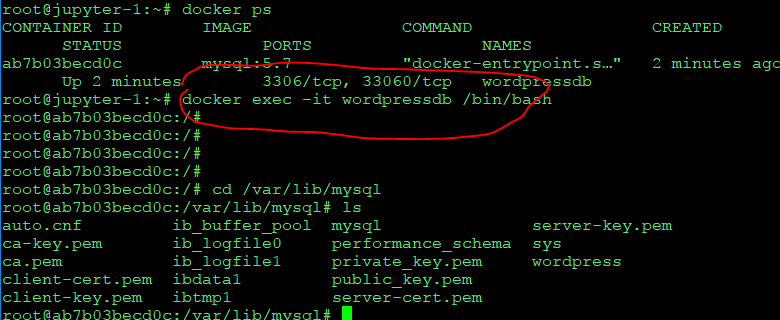
wordpress 컨테이너 돌리기
docker run -d -e WORDPRESS_DB_PASSWORD=password --name wordpress --link wordpressdb:mysql -p 80:80 wordpress
wordpress와 wordpressdb가 잘 동작중..

워드프래스 페이지도 잘나온다.
둘다 종료하려면
docker rm -f wordpress wordpressdb

종료했다가 다시 실행하면 다날라간다..
컨테이너 -> 읽고 쓰기 가능
이미지 -> 안변함
이미지 추가, 삭제, 변경? => 사실 컨테이너에서 삭제, 추가, 변경됨. 컨테이너는 날라간다
컨테이너의 볼륨을 사용하도록 지정??
호스트의 볼륨을 공유
-v 호스트 경로:컨테이너 경로
=> 호스트의 /home/wordpress_db에서 쓰면 컨테이너의 /var/lib/mysql이 반영
docker run -d --name wordpressdb_hostvolume -e MYSQL_ROOT_PASSWORD=password -e MYSQL_DATABASE=wordpress -v /home/wordpress_db:/var/lib/mysql mysql:5.7
- 호스트 경로에 컨테이너의 파일이 공유
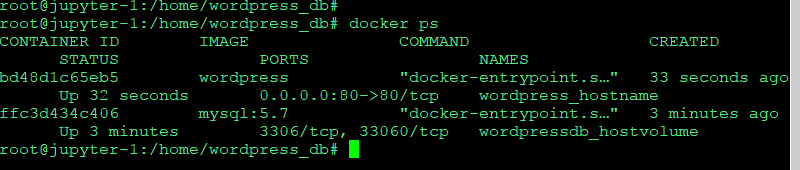
워드프래스도 돌리자
docker run -d -e WORDPRESS_DB_PASSWORD=password --name wordpress_hostname --link wordpressdb_hostvolume:mysql -p 80:80 wordpress
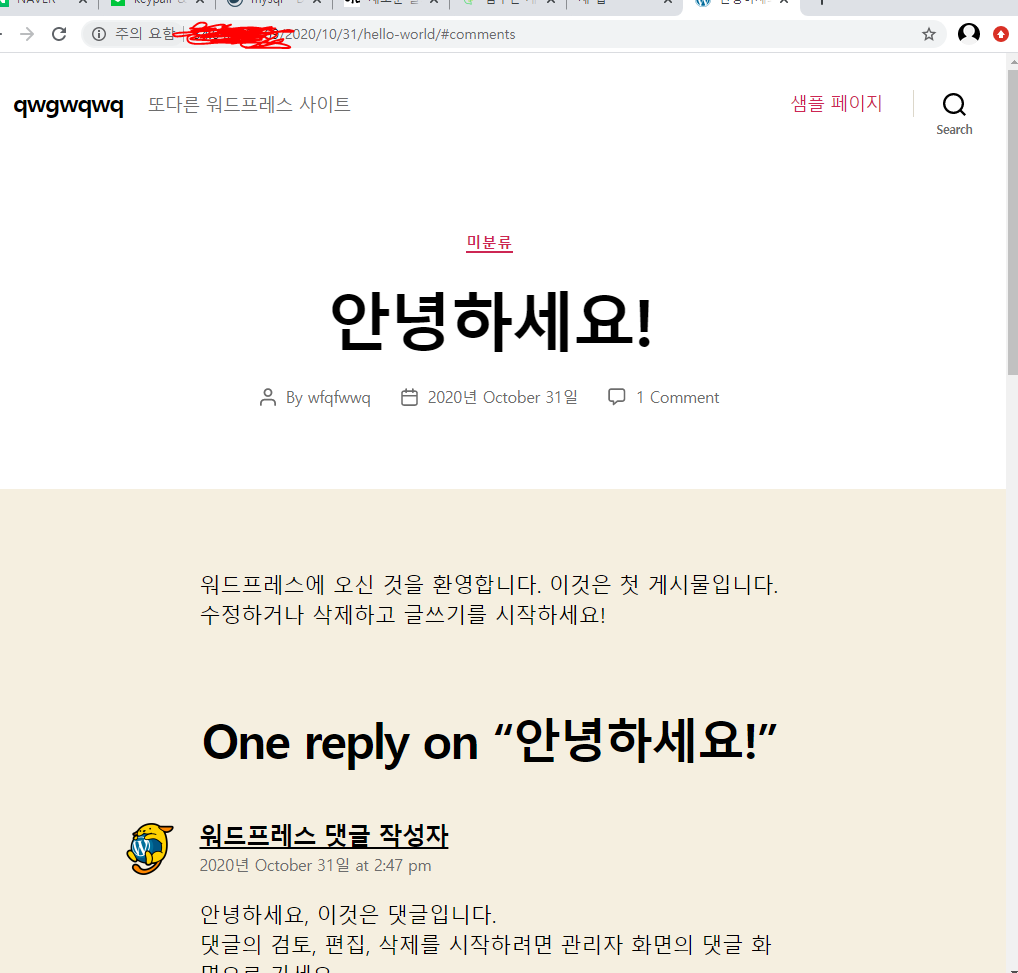
설정도 다하고 껏다 키면
원래 컨테이너 내용들은 다 사라져야 정상이지만
호스트 볼륨에 db를 저장해놔서 껏다 켜도 사라지지 않는다.
로그 처리보기
docker run -d --name mysql -e MYSQL_ROOT_PASSWORD=1234 mysql:5.7
는 잘실행되지만
docker run -d --name no_password_mysql mysql:5.7
비밀번호를 주지않는 경우 ps가 존재하지 않는다.

docker logs 이름을 주면 로그가 나온다.
docker logs no_password_mysql을 하면
mysql_root_password를 안준게 문제라고 나온다.
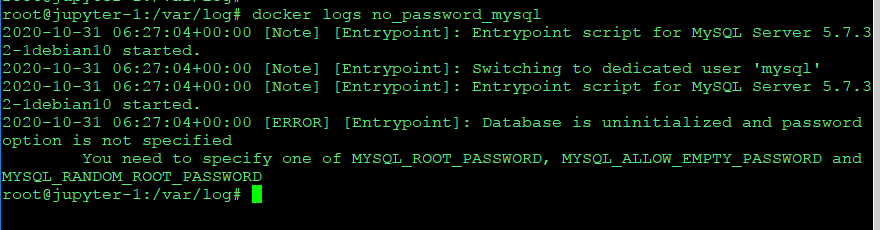
컨테이너 정보보기
docker inspect 이름
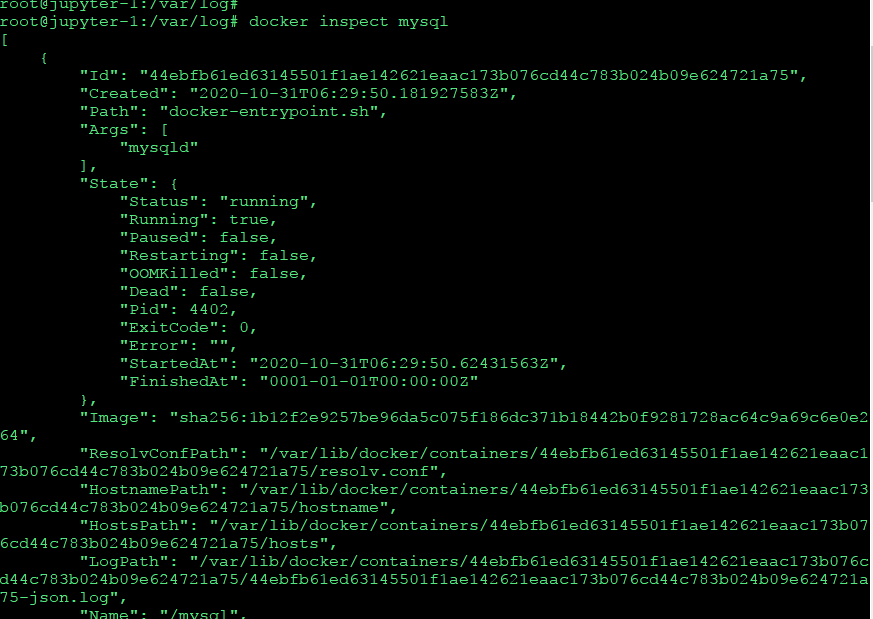
도커 이미지 숙지하기
컨테이너는 날라가지만 이미지는 만들수있다.
docker run -it --name commit_test ubuntu:14.04
컨테이너에서 파일하나 만들어주고 나오자

컨테이너는 동작중

이미지 만들기
docker commit -a "이름" -m "메시지" 컨테이너명 저장소:태그

과제하기
2. jupyter/datascience-notebook or jaimeps/rl-gym 등 데이터 사이언스 관련 컨테이너를 public cloud에서 구동하고 jupyter에서 접속한다.
도커허브에서 풀 커맨드 카피
이미지 다운받고
docker pull jupyter/datascience-notebook
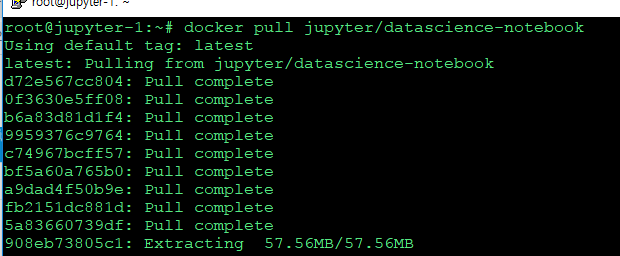
주피터 이미지를 돌리고, 쉘로 들어가서 외부 접속을 허용시켜주자


주피터 설정 파일에 들어가서

#c.notebookapp.allow_origin="" 는 주석을 지우고 별표
c.notebookapp.allow_origin="*"


내가만든 이미지를 확인해보니 ip 주소가 172.17.0.2 이므로

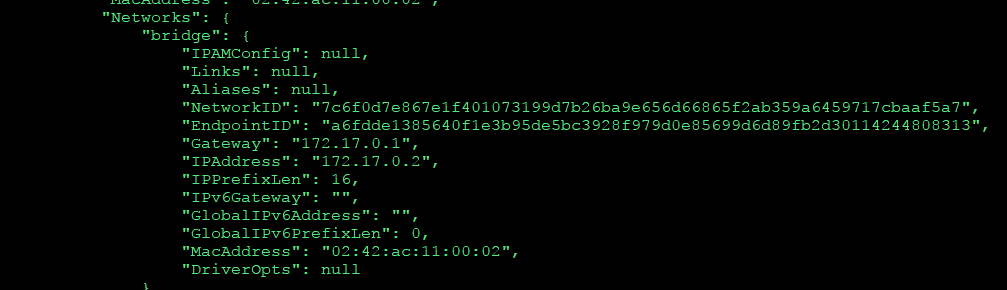
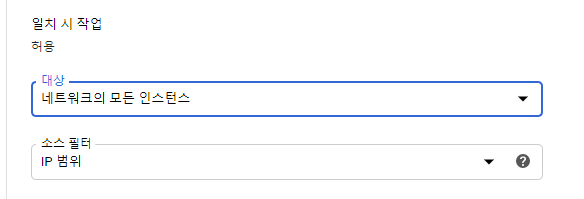
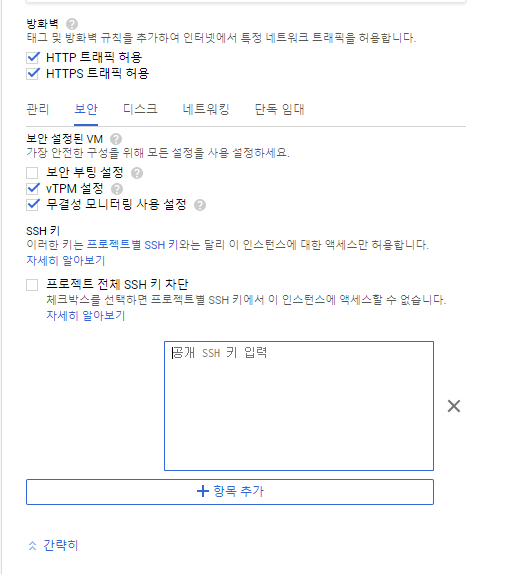
8888포트로 들어갈수있도록 방화벽도 오픈하자.

토큰 안나오개 하려다 망해서 그냥 패스
---------------------------------------
docker run -d -p 8888:8888 -v /home/jupyter:/home/jovyan/work --name juyter jaimeps/rl-gym
로그서 토큰보고 들어가자
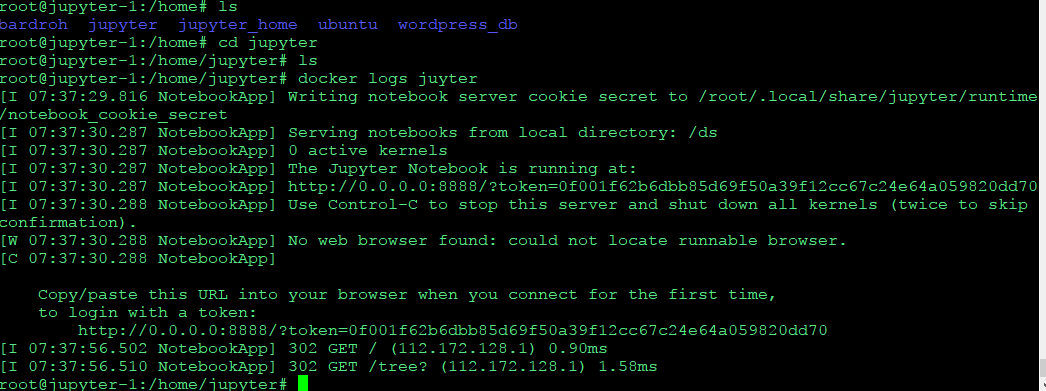
3. pytorch를 설치한 이미지로 컨테이너를 구동한다.
정리하기 귀찬다.
jupyter/datasicn블라블라 컨테이너에들어가서
pip로 torch 설치
pip install torch
토치 설치된 컨테이너를 이미지로 만들어주자 docker commit
* docker commit -a "작성자" -m "메시지" 이미지만들패키지 [저장소명:태그]
docker commit -a "jdo" -m "add torch" jupyter jdo/jupyter:first
기존의 컨테이너는 지워주고
docker rm -f jupyter
새로 만든 이미지를 실행하자
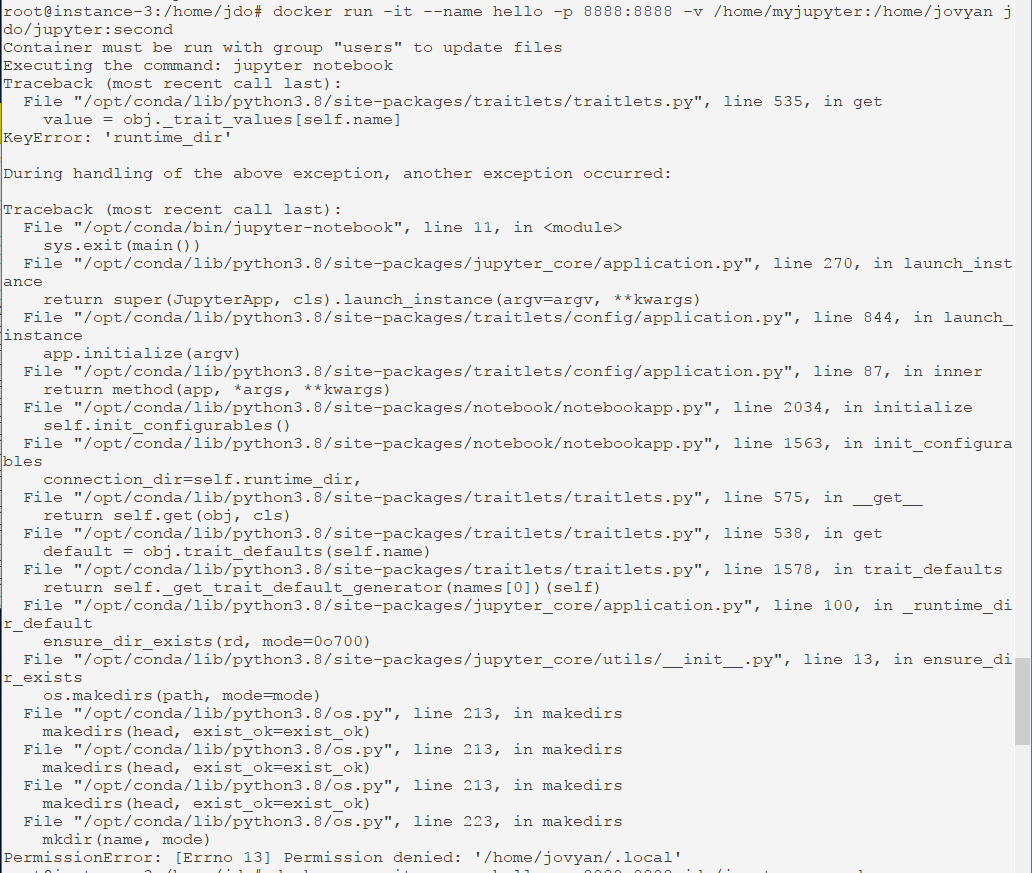
docker run -d --name jupyter -p 8888:8888 -v /home/jupyter:/home/jovyan jdo/jupyter:first
주피터 컨테이너에 동작하면, 이 컨테이너의 배쉬 셸로 들어가자
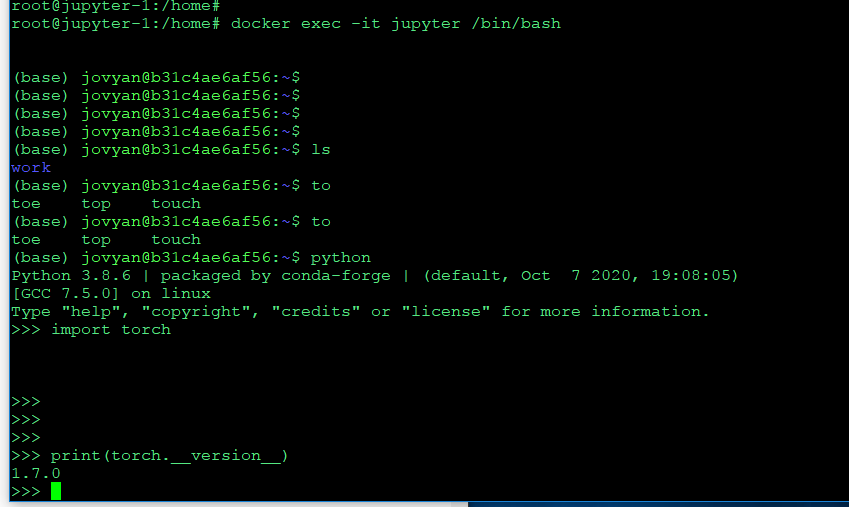
docker exec -it jupyter /bin/bash
python 명령어로 python 인터프리터 실행
import torch
print(torch.__version__)
설치된 토치의 버전 확인까지 하면 끝 !