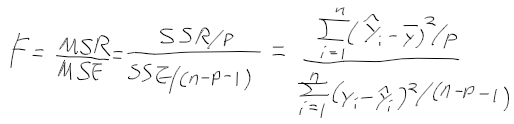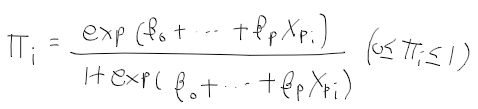트리 모델
- 데이터 분석 과정을 트리로 구조화하여 분류/회귀 분석하는 기법
- 타겟 변수(목표 변수)가 카테고리형(범주형)인경우 분류기
- 목표 변수가 확률, 수인경우 회귀 모델 이용
-> 트리로 많은 양의 데이터를 분석할수 있음
트리
- 개요 : 데이터에 기반하여 노드들을 분할해나감. 분리 규칙을 구할지 판단.
- 사용 목표 : 분류, 변수 선택, 변수간 상관성 탐색 용도로 사용 가능
트리 모델의 역사
- 변수간 연관성 탐색하는 방법으로서 개발
- AID 1964
- THAID 1973, CHAID Squared Automatic Interaction Detection 1980
- CART Classfication And Regressions Trees 1984년도에 완성된 트리 모델
- C4.5 1983
- FACT 1988
- Quest 1997 : 이진 분할 + 나무모형 가지치기 수행
- Cruise 2001 : 다중 분할 나무모형
트리 모델 장점
- 독립 변수의 형태에 상관없이 사용
- 이해, 해석이 간편
- 변수간 상관성 쉽게 찾을수 있음
- 결측치 처리가 용이
- 새로운 데이터에 대해 쉽게 예측 가능
트리 모델 단점
- 단순함과 분리를 하는 만큼 타 모델보다 성능이 떨어질수 있음
- 학습 데이터가 적은 경우, 쉽게 변할 수 있음
CART 모델
- 불순도를 낮추도록 이진 분할 수행
- 불순도는 지니계수 함수로 계산
- 분할 임계치 선정과 분할을 재귀적으로 수행하여 트리 모델 완성
C4.5 트리모델
- CART 모델과 동일하나 엔트로피를 이용하여 불순도 계산
* 엔트로피 : 정보의 불확실성 정도.
ref: hyunw.kim/blog/2017/10/14/Entropy.html
CHAID Chi squared Automatic Interaction Detection 트리모델
- 카이제곱 검정을 이용하여 분할 임계점을 결정함
QUEST Quick Unbiased Effcient Statistical Tree 모델
- CART 모델의 변수 선택 편향성을 개선하기 위한 모델
* CART 모델은 특정 분류값이 많을 수록 해당 변수 위주로 분할
- 변수 선택 : 일원배치 분산분석과 카이제곱검정이용
- 분할 임계치 선정 : CART의 임계치 선정 법과 2차 판별분석을 혼용
- 장점 : 연산 속도가 빠르며, CART의 편향성을 개선
CRUISE 트리 모델
- QUEST의 변수 선택 방법을 개선. 변수간 상관성을 더 반영
- 변수 선택 : 카이제곱 분할표 검정 이용
- 분할 임계치 선택 : 박스-콕스 변환후, CART의 방법과 선형 판별분석 수행
- 장점 : 다중 분할/ 선형 결합 분할 가능
트리 모델 크기 조절 방법
- 분할 정지 split 방법 : 통계적 유의성을 이용하여 분할을 해나갈지 평가
- 가치지기 pruning 방법 : 분할해 나간후. 적절하지 않은 일부 가지를 제거
'컴퓨터과학 > SW, DB' 카테고리의 다른 글
| 빅데이터 - 8. 통계학과 기초통계량 (0) | 2020.11.25 |
|---|---|
| 데이터마이닝 - 4. 앙상블 모델 (0) | 2020.11.25 |
| 빅데이터 - 7. 전처리 (0) | 2020.11.23 |
| 빅데이터 - 6. 수집 및 관리 (0) | 2020.11.23 |
| 데이터마이닝 - 2. 회귀모형 (0) | 2020.11.19 |