미로에서 길을 찾는건 컴퓨터 과학에서 가장 흔히 다루는 탐색 문제라고 할수 있습니다. 여기서 사용할 지도는 2차원 그리드 셀로 되어있으며, 여기서 셀 cell이란 문자열로 빈 공간은 " ", 막힌 공간은 "X"로 표시하겠습니다. 이 외에도 시작점, 도착지, 경로등을 나타내기위해 아래와 같이 정의하겠습니다.
2.2.1 임의의 미로 생성하기
이제 만들 Maze 클래스는 2차원 그리드로(리스트의 리스트)로 상태를 나타내려고 하는데, 이 상태들의 종류로는 행의 수, 열의 수, 시작 위치, 목적지, 긜고 임의로 막힌 공간들이 있겠습니다.
미로는 시작지점과 도착지를 지정하면, 이에 대한 경로가 존재하도록 희박해져야 하는데, 일단 새 미로를 호출할때 희소 정도를 명시하도록하고, 기본값으로 20%정도 블록으로 설정하겠습니다.
#file_name : maze.py
from enum import Enum
from typing import NamedTuple
import random
class Cell(str, Enum):
EMPTY = " "
BLOCKED = "X"
START = "S"
GOAL = "G"
PATH = "*"
class MazeLocation(NamedTuple):
row: int
column: int
class Maze:
def __init__(self, rows = 10, columns = 10, sparseness = 0.2, start = MazeLocation(0, 0), goal = MazeLocation(9, 9)):
self._rows = rows
self._columns = columns
self.start = start
self.goal = goal
self._grid = [[Cell.EMPTY for c in range(columns)] for r in range(rows)]
self._randomly_fill(rows, columns, sparseness)
self._grid[start.row][start.column] = Cell.START
self._grid[goal.row][goal.column] = Cell.GOAL
def _randomly_fill(self, rows, columns, sparseness):
for row in range(rows):
for column in range(columns):
# 균일 분포로 생성한 확률이 희소 임계치보다 작은 경우에만 블록
if random.uniform(0, 1.0) < sparseness:
self._grid[row][column] = Cell.BLOCKED
def __str__(self):
output = ""
for row in self._grid:
output += "".join([c.value for c in row]) + "\n"
return output
maze = Maze()
print(maze)
2.2 다른 세부사항들
목적지를 탐색하는 함수를 구현하기 전에 우선 MazeLocation이 도착지에 도달했는지 확인할수 있어야 하는데 이 함수를 Maze 클래스에 추가해 줍시다.
def goal_test(self, ml):
return ml == self.goal
그 다음으로 미로 상에 어느 위치가 주어지면 이 곳에서 수직이나 수평으로 움직일수 있는지 확인하여야 합니다. ㅎ함수 successors()로 해당 위치에서 가능한 다음 위치를 찾아볼수 있도록 구현하겠습니다. 이 함수는 단순하게 위, 아래, 오른쪽, 왼쪽이 빈 공간인지만 확인하는 것으로 지도의 가장자리는 확인을 해서는 안됩니다. 반환 값은 이동 가능한 모든 MazeLocation이 되겠습니다.
def succesors(self, ml):
locations = []
# 오른쪽이 미로 범위 안이고, 막히지 않은 경우
if ml.row + 1 < self._rows and self._grid[ml.row+1][ml.colum] != Cell.BLOCKED:
locations.append(MazeLocation(ml.row + 1, ml.column))
# 왼쪽이 미로 범위 안이고, 막히지 않은 경우
if ml.row - 1 >= 0 and self._grid[ml.row - 1][ml.column] != Cell.BLOCKED:
locations.append(MazeLocation(ml.row - 1, ml.column))
# 위쪽이 미로 안이고 안 막힌 경우
if ml.column + 1 < self._column and self._grid[ml.row][ml.column + 1] != Cell.BLOCKED:
locations.append(MazeLocation(ml.row, ml.column + 1))
# 아래가 미로 안이고 안막힌 경우
if ml.column -1 >= 0 and self._grid[ml.row][ml.colum - 1] != Cell.BLOCKED:
location.append(MazeLocation(ml.row, ml.column - 1))
return locations
2. 탐색 문제 탐색 search는 앞으로 볼 수많은 알고리즘에서 사용되는 용어로 이번에는 모든 프로그래머들이 알아야하는 핵심 탐색 알고리즘들을 살펴보겠습니다.
2.1 DNA 탐색 컴퓨터 소프트웨어에서 유전자 gene는 문자들의 시퀀스 A, C, G, T로 나타낼수 있는데요. 각각의 문자를 뉴클레오타이드라고 하며, 뉴클레오타이드가 3개가 모인 것을 코돈 codon이라고 부릅니다. 이것에 대한 내용은 아래의 그림 2.1에서 볼수있는데요. 코돈은 단백질 protein을 형성하는 다른 아미노산들과 함께 특정 아미노산을 부호화 하는데, 생물 정보학에서 일반적인 작업은 유전자에 있는 특정한 코돈을 찾는 것이 됩니다.
2.1.1 DNA 저장하기 4가지 경우에 대한 뉴클레오타이드를 간단한 IntEnum으로 나타내보겠습니다.
from enum import IntEnum
from typing import Tuple, List
Nucleotide = IntEnum('Nucleotide', ('A', 'C', 'G', 'T'))
여기서 뉴클레오 타이드는 그냥 Enum대신에 IntEnum이라는 타입으로, 이 타입은 비교 연산자도 사용할수 있게 해줍니다. IntEnum에서 이 연산들은 앞으로 구현할 탐색 알고리즘에서 필요한 것들입니다. 튜플과 리스트는 typing 패키지에서 가져와서 사용하면 되겠습니다.
# 타입 별칭 설정
Codon = Tuple[Nucleotide, Nucleotide, Nucleotide]
Gene = List[Codon]
코돈은 3개의 뉴클레오타이드로 정의할수 있고, 유전자는 코돈들의 목록, 리스트로 정의되겠습니다.
* 주의사항 나중에 코돈을 다른 코돈이랑 비교할건데, 파이썬에서 빌트인으로 비교할수 있게 되어있어 따로 이 클래스에서 비교 연산자를 구현할 필요는 없습니다.
일반적으로 인터넷에서 유전자는 유전자들의 시퀀스에 있는 모든 뉴크레오타이드를 문자열로 나타낸것으로 파일 형식같은 것이 됩니다. 이제 가상의 유전자에 대한 문자열을 gene_str이라고 부릅시다.
이제 이 문자열 str을 유전자 gene으로 변환해봅시다.
gene_str = "ACGTGGCTCTCTAACGTACGTACGTACGGGGTTTATATATACCCTAGGACTCCCTTT"
def str_to_gene(s):
gene = []
for i in range(0, len(s), 3):
if (i + 2) >= len(s):
return gene
codon = (Nucleotide[s[i]], Nucleotide[s[i+1]], Nucleotide[s[i+2]])
gene.append(codon)
return gene
string_to_gene()은 주어진 str을 이용해서 3개의 문자들을 코돈으로 만들고, 새 유전자의 끝에다가 추가시키는 역활을 수행합니다. 만약 더 이상 뉴클래오타이드 2개가 담겨질 곳이 없으면, 불안전한 유전자로서 끝에 도달한것이 됩니다. 이 경우에 마지막 하나나 2개 남은 뉴클레오 타이드를 무시하면 됩니다.
2.1.2 선형 탐색 유전자에 사용할수있는 기본적인 연산 중 하나로 특정 코돈이 어디있는지에 대한 탐색이 될수 있습니다. 여기서 목표는 코돈이 이 유전자 내부에 존재하는것인지 안하는것인지 찾아내기만 하면 되겠는데요.
선형 탐색은 탐색 공간에 존재하는 모든 요소에 대해서 해당 요소를 찾거나 그 데이터 구조의 끝에 도달할때까지 수행하게 됩니다. 그래서 선형 탐색은 가장 단순하고 명확한 방법이라고 할수 있겠습니다. 하지만 최악의 경우에 선형 탬식시에는 데이터 구조상에 존재하는 모든 요소들을 확인해야 할것이고, 이 구조에 요소의 갯수가 n개가 존재한다면 O(n) 복잡도를 가진다고 할 수 있겠습니다.
선형 탐색 함수는 쉽게 정의할수 있는데요. 그냥 데이터 구조상에 있는 모든 요소들을 돌려보고 찾으려고 하는 것과 같은지만 확인하면 되겠습니다. 아래의 코드는 유전자와 코돈이 주어질때, 해당 유전자 안에 입력한 코돈이 존재하는지 검사하게 됩니다.
def linear_contains(gene, key_codon):
for codon in gene:
if codon == key_codon:
return True
return False
acg = (Nucleotide.A, Nucleotide.C, Nucleotide.G)
gat = (Nucleotide.G, Nucleotide.A, Nucleotide.T)
"""
gene_str = "ACGTGGCTCTCTAACGTACGTACGTACGGGGTTTATATATACCCTAGGACTCCCTTT"
ACG는 gene_str의 0~2에 존재
"""
print("\n-binary search-")
print(linear_contains(my_gene, acg)) # 참
print(linear_contains(my_gene, gat)) #거짓
2.1.3 이진 탐색 모든 요소를 확인하는것 보다 더 빠른 방법들이 있지만 데이터 구조의 순서에 대해서 알아야 합니다. 만약 정렬된 데이터 구조가 있다면 어느 요소의 인덱스 번호로 해당 요소에 바로 접근할수 있을것이고, 이진 탐색을 할수 있겠습니다. 이런 기준에 따라서 정렬된 리스트는 이진 탐색의 완전한 예시라 할수 있습니다.
이진 탐색은 정렬된 요소들의 중간 요소와 찾으려는 요소를 비교해서 수행하는데, 비교할 범위를 절반으로 줄이면서 반복 과정을 하게 됩니다. 간단한 예시를 살펴보겠습니다.
2. “rat”은 알파벳 순서를 생각하면 “llama”뒤에 있으므로, “llama”의 뒷쪽에 리스트의 전체 목록 절반 중 어딘가에 있을겁니다.
3. 이제 목록의 절반에 대해서 1, 2번 단계를 수행하면 “rat”이 어디있는것인지 찾을수 있겠으나 더 이상 탐색할 원소가 존재하지 않게 된다면 이 단어의 리스트에는 “rat”이 없다고 볼수 있겠습니다.
이진 탐색은 탐색공간을 계속 절반씩 나누므로 최악의 경우에 실행시간이 O(log n)이 됩니다. 그 전에 잠시 생각해봐야할 점은 선형 탐색과는 달리 이진 탐색에서는 이미 정렬된 데이터 구조를 필요하므로, 최적의 정렬 알고리즘으로 정렬을 한 후에 이진 탐색을 수행한다면 O(n log n) 복잡도를 가지게 됩니다.
만약 기존의 데이터가 정렬되어있지 않은데 탐색을 바로 수행한다고 하면, 선형 탐색처럼 똑같이 동작하게 될겁니다. 하지만 탐색을 여러 차례 수행해야한다고 하는 경우에, 정렬을 해놓은 후 각각에 대한 탐색을 수행하면 시간 비용을 크게 줄일수 있을 겁니다.
유전자와 코돈을 이용한 이진 탐색 알고리즘에서는 다른 데이터 타입을 사용할 필요가 없는데, 코돈 codon 타입 자체가 유전자 타입의 한 원소와 비교할수 있기 때문입니다.
# file name : fib1.py
def fib1(n):
return fib1(n - 1) + fib1(n-2)
if __name__ == "__main__":
print(fib1(5))
이 경우 fib1은 한번 호출되면 끊임없이 무한하게 자기자신을 호출해서 무한 루프에 빠지게 됩니다.
1.1.2 베이스 케이스 base case 활용
여기서 무한 루프, 무한 재귀에 빠지는걸 막으려면 베이스 케이스를 지정해주면 되는데
베이스 케이스는 멈출 지점이 됩니다.
여기서 n이 0과 1인 경우는 자기 자신을 반환해주면 되므로
# file name : fib1.py
def fib2(n):
if n < 2 : #base case
return n
return fib2(n - 1) + fib2(n - 2) #recursive case
if __name__ == "__main__":
for i in range(10):
print(fib2(i))
반복문으로 첫번째에서 10번째 피보나치 수들을 출력하면 아래와 같습니다.
* 주의사항
여기서 50번째 피보나치 수를 출력하지는 마세요
5번째 피보나치 수를 출력하기 위해서 fib2함수가 15번 호출되고
10번째 피보나치 수를 출력하는데는 fib함수가 177번 호출됩니다.
20번째의 경우 21,891번으로 점점 커지게 됩니다.
다음은 fib2 를 약간 수정하여 fib2 함수가 몇번 호출되는치 출력하도록 수정하였습니다.
# file name : fib2_cnt.py
call_cnt = 0
def fib2(n):
global call_cnt
call_cnt = call_cnt + 1
if n < 2 : #base case
return n
return fib2(n - 1) + fib2(n - 2) #recursive case
if __name__ == "__main__":
for i in range(11):
call_cnt = 0
print(" i - ",i, " : ", fib2(i), " - call_cnt : ", call_cnt)
1.1.3 재귀 대신 기억하기
기억은 계산작업이 끝날때 까지 계산 결과를 저장해놓는 것으로 재귀에서 이전의 결과를 구하기 위해 수많은 계산을 했던것 대신 필요한 값들을 저장해놓고 찾아서 사용하면 됩니다.
이번에는 값을 기억하도록 딕셔너리를 써서 구현해보겠습니다.
#file_name : fib3.py
memo = {0:0 , 1:1} #base case
def fib3(n):
if n not in memo:
memo[n] = fib3(n - 1) + fib3(n - 2) # memorization
return memo[n]
if __name__ == "__main__":
print(fib3(5))
print(fib3(10))
print(fib3(50))
1.2 단순 압축
공간 절약은 보통 중요합니다. 데이터가 더 작은 공간을 차지하도록 하는 기술이 압축 compression이고, 이 압축된 데이터를 원래대로 되돌리는것을 압축풀기 decompression이라 합니다.
초기 데이터 압축에서는 데이터 저장소가 사용하는 비트 수을 따라왔는데요.
64비트 컴퓨터에서 unsigned integer는 65,535를 초과하는 수를 저장할수 없으며, 이는 매우 비효율적입니다.
하지만 16비트 unsigned integer에서는 남는 공간을 다 채울수 있어서
unsigned integer를 사용하는 경우 64비트 보다 16비트에서 75%정도 공간낭비를 줄일수 있습니다.
이번에 sys.getsizeof() 함수로 객체가 얼마나 메모리 공간을 차지하고 있는지 확인해 볼것이고
DNA에서 유전자를 구성하는 뉴클레오 타이드를 가지고 살펴보겠습니다.
뉴클레오 타이드는 A, C, G, T 이 4가지 값 중 하나만 가질수 있는데요
"ATG" 라는 유니코드 문자열이 있는 경우
한 글자에 8비트로 총 24비트 공간을 차지하는 문자열이 됩니다.
하지만 뉴클레오 타이드의 경우에 수는 4가지 뿐이므로
8비트 대신 2비트로 다음과 같이 비트 문자열에다 저장하면 75%정도 더 절약할수 있겠습니다.
즉, 하나의 뉴클레오 타이드를 2비트로 나타낼수 있겠습니다.
00
A
01
C
10
G
11
T
이제 압축된 유전자 클래스를 만들어서
압축 함수와 압축 해제 함수 등을 구현해서
뉴클레오 타이드 문자열을 압축해보고, 압축해제를 해보겠습니다.
* 주의사항
_compress()는 언더스코어로 시작하는 함수인데
파이썬에서는 private 함수 같은 제한이 없어서
외부에서 호출하면 안되는 함수들은 앞에 언더스코어 _를 붙여주겠습니다.
from sys import getsizeof
# file_name : trivial_compression.py
class CompressedGene:
def __init__(self, gene):
self._compress(gene)
def _compress(self, gene):
self.bit_string = 1
for nucleotide in gene.upper():
#print(nucleotide)
#print("bit_str : ", bin(self.bit_string))
# 비트 문자열에 압축한 값을 넣기 전에 기존의 비트문자열을 2번 시프트
self.bit_string <<= 2
# 문자 A가 오면 00, C가 오면 01 등으로 비트문자열에 저장
if nucleotide == "A":
self.bit_string |= 0b00
elif nucleotide == "C":
self.bit_string |= 0b01
elif nucleotide == "G":
self.bit_string |= 0b10
elif nucleotide == "T":
self.bit_string |= 0b11
else:
raise ValueError("Invalid Nucleotide: {}".format(nucleotide))
def decompress(self):
gene = ""
for i in range(0, self.bit_string.bit_length() - 1, 2):
bits = self.bit_string >> i & 0b11
if bits == 0b00:
gene += "A"
elif bits == 0b01:
gene += "C"
elif bits == 0b10:
gene += "G"
elif bits == 0b11:
gene += "T"
else:
raise ValueError("Invalid bits:{}".format(bits))
return gene[::-1] # 문자열을 역순으로 반환
# CompressGene의 문자열 반환값
def __str__(self):
return self.decompress()
if __name__ == "__main__":
original = "TAGGGATTAACCGTTATATATATATAGCCATGGATCGATTATATAGGGATTAACCGTTATATATA" * 100
compressed = CompressedGene(original)
#print(compressed)
print("original is {} bytes".format(getsizeof(original)))
print("compressed is {} bytes".format(getsizeof(compressed.bit_string)))
print("original and decompressed are the same : {}". format(original == compressed.decompress()))
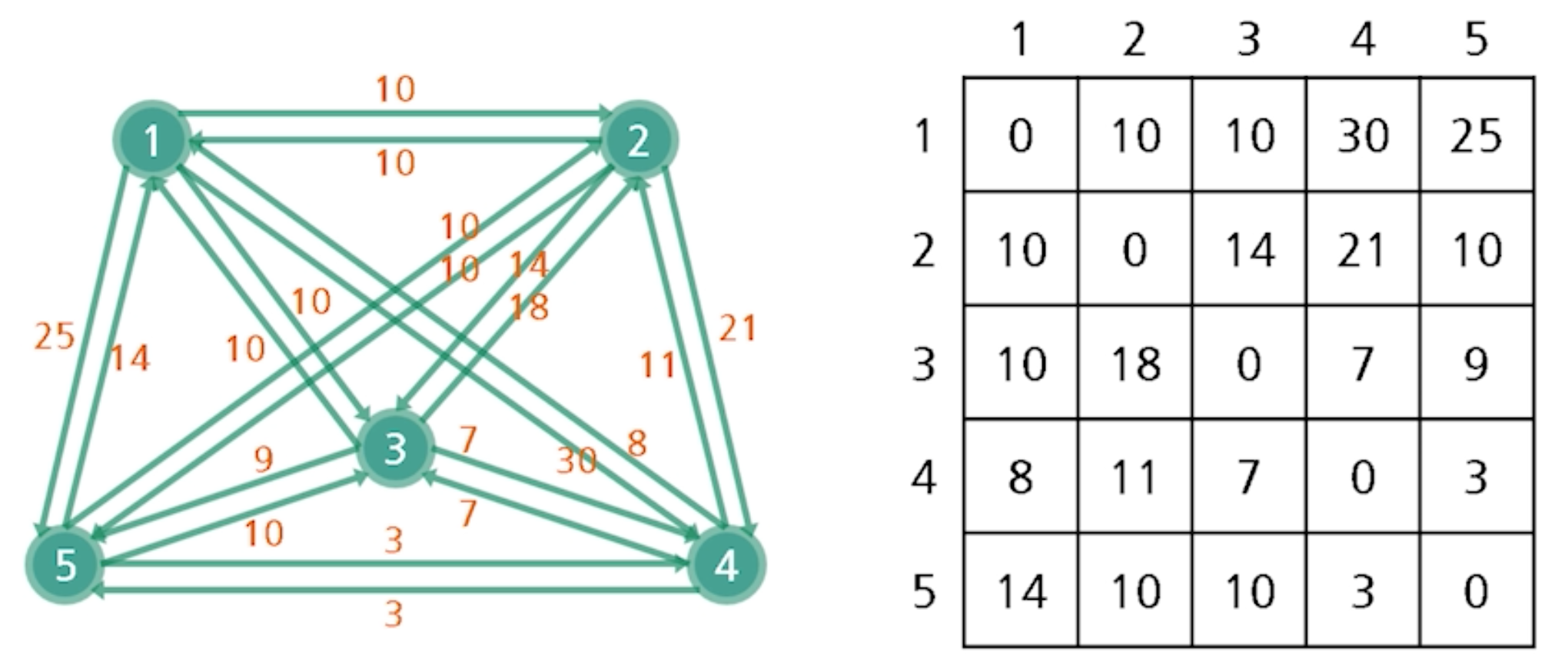
- 완전 그래프에서 해밀토니안 싸이클은 수 없이 많은데 여행자 문제는 그 중 가장 짧은 것을 찾는 문제
TSP와 인접행렬의 예
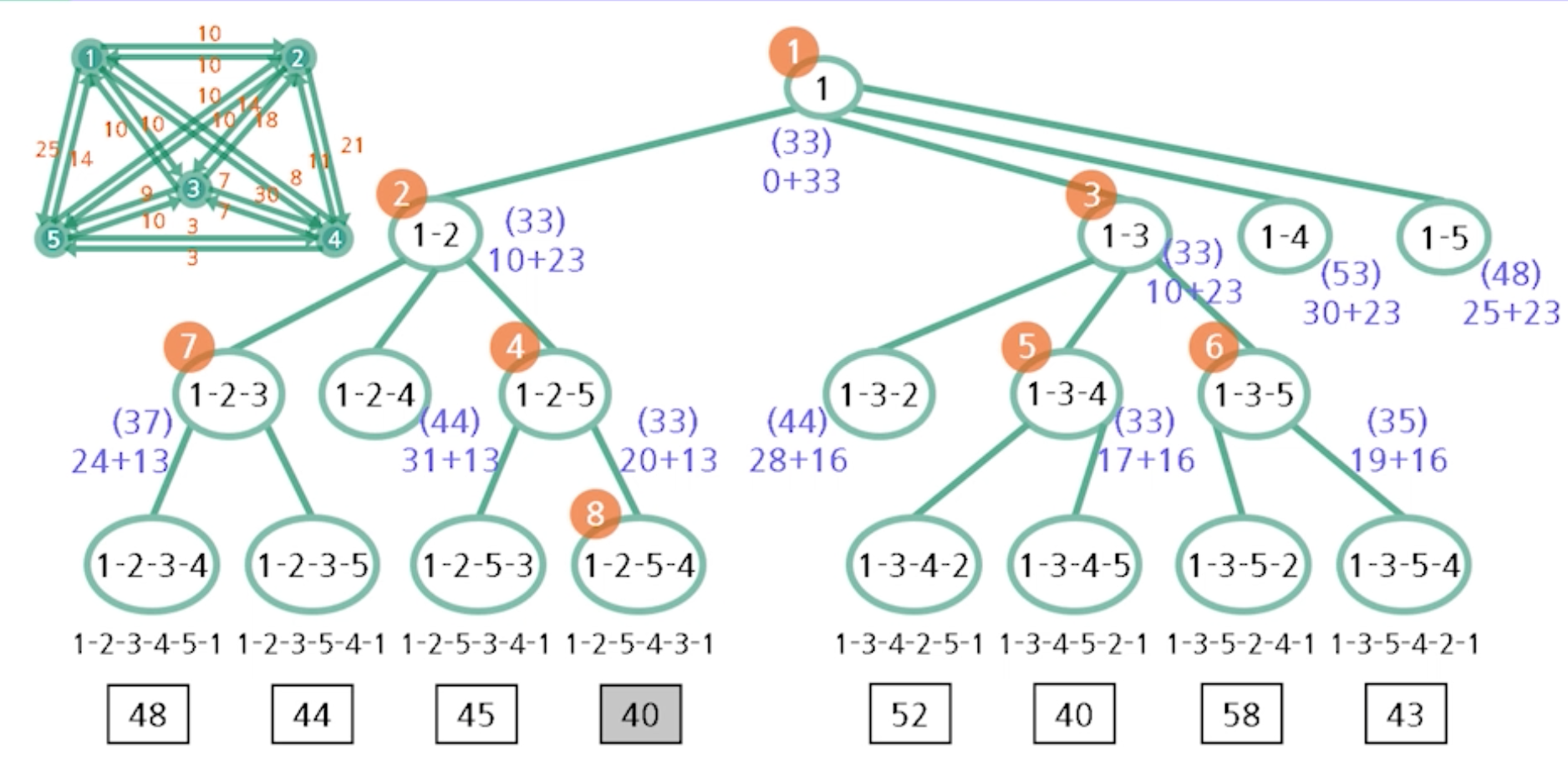
사전식 탐색의 상태공간 트리
- 다섯 개의 도시를 가진 TSP의 최적해를 찾으려면 -> 모두 4!(24)개의 해를 검사해보아야함
백트래킹
- DFS 또는 그와 유사한 스타일의 탐색을 총칭. 가능한 지점까지 탐색하다 막히면 되돌아감. 주로 재귀적으로 ㄱ현
- ex : 미로 찾기 문제, 8퀸 문제, 색칠 문제(map coloring)
미로찾기 문제
- S : 시작점
- T : 목표지점
- S에서 시작하여 T까지 이동하는 경로 찾기
미로찾기 문제의 탐색 과정을 상태 공간 트리로 표현하는 방법
1. S에서 시작해 정점 1로 이동, 정점 2 또는 정점 3중 하나를 선택함
2. 임의의 정점 2를 선택함, 막다른 골목에 다다름
3. 정점 2로 오기위해 거쳤던 정점 1로 되돌아감 정점 3으로 감
4. 정점 3으로 이동함, 정점 4와 정점 5중 하나를 선택함
5. 정점 5에 이름, 정점 6과 정점 7중 하나를 선택함
6. 정점 6에 이름, 막다른 골목에 다다름
7. 정점 6으로 오기위해 거쳤던 정첨 5로 되돌아감
8. 정점 7에 이름, 정점 8과 정점 T중 하나를 선택
미로찾기 문제 해결방법 유사코드
mave(v)
{
visited[v] <- YES;
if (v = T) then {print "성공!"; exit();}
for each x in L(v) L(v) : 정점 v의 인접 정접 집합
if (visited[x] = NO) then{
prev[x] <- v;
maze(x);
}
}
한정 분기 branch & bound
- 분기와 한정의 결합 -> 분기를 한정시켜 쓸데없는 시간 낭비를 줄이는 방법
- 기존의 상태공간트리에서 사전식 탐색시 (n - 1) ! 시간이 소요됨 => 지수시간 이상
백트래킹과 공톰정과 차이점
- 공통점 : 경우들을 차례로 나열하는 방법이 필요함
- 차이점
백트래킹 : 가보고 더이상 진행되지않으면 되돌아옴
한정분기 : 최적해를 찾을 가능성이 없으면 분기하지 않음
-> 지금까지 얻은해보다 더 좋은해가 아니라면 분기를 하지 않음
가지치기의 원리
TSP 예제를 대상으로 한 한정분기 탐색의 예시
A* 알고리즘
1. A*알고리즘 개요
2. 최단 경로 문제
3. A*알고리즘 작동예
4. TSP 예쩨를 대상으로 한 A* 알고리즘 탐색의 예
최적 우선 탐색 BFS Best First Search
- 각 정점이 매력 함숫값 g(x)를 가짐.
- 방문하지 않은 정점들 중 g(x)값이 가장 매력적인 것부터 방법
A* 알고리즘
- 최적 우선 탐색을 이용하여 목적점까지 이르는 잔여 추정 거리를 고려하는 알고리즘
- 정점 x로부터 목적점에 이르는 잔여거리의 추정치 h(x)는 실제치보다 크면 안됨
Remind : 다익스트라 알고리즘
- 시작점은 하나
- 시작점으로부터 다른 모든 정점에 이르는 최단 경로를 구함 -> 목적점이 하나가 아님
<-> A* 알고리즘에서는 목적점이 하나임
다익스트라 알고리즘으로 최단경로 찾기
A*알고리즘을 이용한 최단 경로 찾기
- 추정 잔여거리 h(x): 각 정점에서 목적지 까지 직선 거리
- 시작점을 0, 모든 정점을 무한대로 초기화
- 시작점 주위의 거리 값을 구하고 g(x)라 함.
- g(x) + h(x)하여 우측 그림과 나타낼 수 있음
=> 이 중에서 g(x) + h(x)가 가장 작은 정점 23을 포함시킴
- 정점 41의 g(x) + h(x)값이 60으로 가장 작으므로 포함시킴
=> 추정 잔여거리를 사용하여 탐색의 단계가 현저히 줄어들음
TSP 예제를 대상으로 한 A* 알고리즘 탐색의 예
- 상태 공간 트리
- A* 알고리즘이 첫 리프 노드를 방문하는 순간 종료되는 이유
* 방금 본 그래프는 모든 정점에 대해서 h(x) 값을 미리 계산해둠. 일반적인 상태 공간 트리 문제에서는 미리 주어지지 않고 만들어지면서 탐색이 진행됨 -> 따라서 각 노드에서 목적점에 이르는 길이의 추정치는 그 때 그 때 계산하여야함
상태공간 트리
- 모든 정점을 지나서 시작정점으로 돌아오는지. 가중치의 합이 최소가 되는지 알아봄
- 하한선 33은 모든 정점에서 가장 작게 나가는 값들의 합(1 : 10, 2: 10, 3: 7, 4: 3, 5 : 3 -> 10 + 10 + 7 + 3 + 3 = 33)
- 이를 위해서 3대의 카메라를 각각 점 1, 5, 6에 설치하면 모든 복도(선분)를 '커버'할 수 있음
정점 커버 문제의 두가지 접근 방법
1. 먼저 차수가 가장 높은 점을 우선 선택하면 많은 수의 선분이 커버 됨
2. 점을 선택하는 대신에 선분을 선택하는 것
- 선분을 선택하면 선택된 선분의 양 끝점에 인접한 선분이 모두 커버됨
- 따라서 정컴 커버는 선택된 각 선분의 양 끝점들의 집합임
- 정점 커버를 만들어 가는 과정에서, 새 선분은 자신의 양 끝점들이 이미 선택된 선분의 양 끝점들의 집합에 포함되지 않을 때에만 선택됨
작업 스캐줄링 문제
- n개의 작업, 각 작업 수행시간 t_i, i = 1, 2, 3, ..., n 그리고 m개의 동일한 기계가 주어질 때, 모든 작업이 가장 빨리 종료되도록 작업글 기계에 배정하는 문제
작업 스케줄링 문제의 조건
- 한 작업은 배정된 기계에서 연속적으로 수행되어야 함
- 기계는 한 번에 하나의 작업만을 수행함
가장 간단한 해법은 그리디 방법으로 작업 배정
- 현재까지 배정된 작업에 대해 가장 빨리 끝나는 기계에 새 작업을 배정하는 것
작업 스케줄링 문제를 그리디 알고리즘을 이용하여 근사해를 구하는 유사 코드
Approx_JobScheduling
입력 : n개의 작업, 각 작업 수행 시간 t_i, i = 1, 2, ..., n 기계 M_j, j = 1, 2, ..., m
출력 : 모든 작업이 종료된 시간
for j = 1 to m
L[j] = 0 L[j] = 기계 M_j에 배정된 마지막 작업의 종료 시간
for i = 1 to n {
min = 1
for j = 2 to m { 가장 일찍 끝나는 기계를 찾음
if (L[j] < L[min])
min = j
}
작업 i를 기계 M_min에 배정함
L[min] = L[min] + t_i
}
return 가장 늦은 작업 종료 시간
작업 스케줄링 문제 해법의 작동 예
- 작업 수행 시간 : 5, 2, 4, 3, 4, 7, 9, 2, 4, 1
- 기계 : 4개
시간 복잡도
1. approx_jobscheduling 알고리즘은 n개의 작업을 하나씩 가장 빨리 끝나는 기계에 배정함
- 이러한 기계를 찾기 위해 알고리즘의 for루프가 m-1번 수행됨
- 모든 기계의 마지막 작업 종료 시간인 L[j]를 살펴봐야하므로 O(m) 시간이 소요됨
2. 시간 복잡도 n개의 작업을 배정해야하고, 배열 L을 탐색해야 하므로 n x O(m) + O(m) = O(nm)임
근사 비율
1. approx_jobscheduling 알고리즘의 근사해를 opt'라 하고, 최적해를 Opt라고 할 때 ,opt' <= 2 x opt임
2. 근사해는 최적해의 두 배를 넘지 않음. t_i는 작업 i의 수행 시간임.
3. 가장 마지막으로 배정된 작업 i가 T부터 수행되며, 모든 작업이 T + T_i에 종료된 것을 보이고 있음. 그러므로 OTP' = T + t_i임.
4. T'는 작업 i를 제외한 모든 작업의 수행 시간의 합을 기계의 수 m으로 나눈 값임. T'는 작업 i를 제외한 i를 평균 종료 시간임
5. T <= T'이 됨
- 작업 i가 배정된(가장 늦게 끝나는) 기계를 제외한 모든 기계에 배정된 작업은 적어도 T 이후에 종료되기 때문임.
클러스터링 문제
- n개의 점이 2차원 평면에 주어질 때, 이 점들 간의 거리를 고려하여 k개의 그룹으로 나누고자 하는 문제
클러스터링 문제 조건
- 입력으로 주어진 n개의 점을 k개의 그룹으로 나누고 각 그룹의 중심이 되는 k개의 점을 선택하는 문제임
- 단, 가장 큰 반경을 가진 그룹의 직경이 최소가 되도록 k개의 점이 선택되어야 함
클러스터링 문제 해결 전략
1. n개의 점 중에서 k개의 센터를 선택해야 하는데, 이를 한 꺼번에 선택하는 것 보다 한 개씩 선택하는 것이 쉬움
2. 오른쪽 그립 같이 첫 번째 센터가 랜덤하게 정해졌다고 가정함
3. 두 번째 센터는 두 개의 센터가 서로 가까이 있는 것보다 멀리 떨어져 있는 것이 좋음