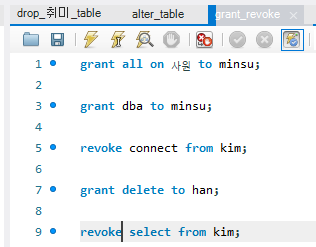
갱신 이상 update anomaly
- 데이터 중복으로 발생하는 문제
- 삽입 이상 : 불필요한 데이터를 삽입하지 않으면 데이터 삽입이 안되는 이상
- 수정 이상 : 중복데이터 중 일부만 수정되어 데이터 불일치 발생
- 삭제 이상 : 유용한 데이터도 같이 삭제되는 문제
교수 릴레이션 - 기본키 : 학번, 교과목 번호

- 학번에 학년 정보가 중복되어 있음
- 삽입 이상 : 600번 학생. 2학년 삽입 시 교과목 번호가 없으면 삽입 x
- 수정 이상 : C312 수강한 400번 학생 학년을 4 -> 3학년으로 변경시 나머지 데이터 학년과 불일치
- 삭제 이상 : 200번 학생 삭제시 3학년 정보도 사라짐
->속성간 종속성 고려가 불충분해서 발생
=> 릴레이션 분해해서 하나의 종속관계를 하나의 릴레이션으로 표현해야함 => 릴레이션 정규화
함수적 종속 functional dependency : fd
- 정규화 핵심 개념으로 릴레이션의 갱신 이상을 발견하는 방법.
- 속성 간 관계에 대한 제약조건에 해당
- 속성 y는 속성 x에 함수적으로 종속 : x -> y
사원 릴레이션의 함수적 종속 관계 표현
1. 사원번호 -> 사원 이름, 주소, 전화번호 : 사원번호를 알면 이름, 주소, 전화번호알수있음
2. 부서번호 -> 부서이름 : 부서번호를 알면 부서이름 알수있음
3. 부서이름 -> 부서번호 :부서이름을 알면 부서번호알수있음
4. {사원번호, 부서번호} -> 직책 : 사원번호, 부서번호를 알아야 직책을 알수있음
5. x : 사원이름이나 부서번호, 주소등을 알아도 나머지 속성을 알수없음. 함수적으로 결정 x

함수적 종속 다이어그램 function dependency diagram fdd
- 함수적 종속 관계를 그림으로 표현
사원 릴레이션 함수적 종속 다이어그램

완전 함수적 종속 full functional dependency
- 복합속성 x -> y가 성립시
- 복합속성 {a,b}가 c의 결정자로 a나 b만으로 c를 결정 불가

부분 함수적 종속
- 복합 속성 x->y 성립시
- 복합 속성 {a, b} 중 b만으로 c를 결정

사원 릴레이션 함수적 종속 정리
함수적 종속 1. {사원번호, 부서번호} -> (직책, 사원이름, 주소, 전화번호, 부서이름) 성립
부분 함수적 종속 1. {부서번호} -> (사원이름, 주소, 전화번호)
부분 함수적 종속 2 {사원번호} -> (부서이름)
완전 함수적 종속 1. {사원번호, 부서번호} -> (직책)
이행적 함수적 종속 transitive functional dependency
- 한 릴레이션 속성 a, b, c가 있을때 다음 필요충분조건 만족하는경우. 속성 c가 속성 a에 이행적 함수적종속

학생 릴레이션 예시
- 학생(학번, 교과목번호, 성적, 학과 이름, 학과 전화번호)
함수족 종속
- 완전 함수적 종속 : {학번, 교과목 번호} -> 성적
- 부분 함수적 종속 : 학번 ->(학과이름, 학과전화번호)
- 완전 함수적 종속 : 학과이름->학과전화번호
학생 릴레이션 함수적 종속 다이어그램

학번 -> 학과명, 학과명-> 학과 전화번호
=> 학과 전화번호는 학번에 이행적 함수적 종속관계
정규화 normalization
- 데이터 중복을 제거하여 갱신 이상 제거. 논리적 데이터 모델 단순화
* 많은 조인이 발생하여 질의 응답시간이 느려질수있음
정규형 normal form
- 데이터 중속 감소와 응답시간 단축하기위한 제약 조건을 만족하는 형태
- 제약조건에 따라 제1 정규형 ~ 제 5정규형.
- 정규화 정도가 낮을수록 하나의 릴레이션에 많은 정보 포함

정규형 단계
1. 제 1정규형 1NF : 모든 속성 도메인이 원자값 -> 중복 속성 분리
2. 제 2정규형 2NF : 모든 속성이 기본키에 완전 함수적 종속 -> 기본키에 부분 함수적 종속 속성 분리
3. 제 3정규형 3NF : 이행적 함수적 종속 없어야함 -> 이행적 함수적 종속 속성 분리
4. 보이스/코드 정규형 BCNF
* 보통 제3정규형이나 보이스/코드 정규형까지 정규화 수행
3NF, BCNF가 최적인 이유
- 1NF, 2NF : 불필요한 데이터 중복, 공간 낭비
- 4NF, 5NF : 너무많은 릴레이션. 복잡한 종속성
정규화 단계
0. 비정규 릴레이션
1. 1NF <- 원자 값이 아닌 도메인 분해
2. 2NF <- 부분 함수적 종속 제거
3. 3NF <- 이행적 함수적 종속 제거
4. BCNF <- 결정자가 후보키가 아닌 함수적 종속 제거
5. 4NF <- 다치 종속성 제거
6. 5NF <- 조인 종속성 제거
- 비정규 릴레이션 예시 : 동아리가 다중치 속성

(1) 제1 정규형
- 릴레이션 속성은 원자값만 가져야함. 학생 2 새 릴레이션 생성(기본키 : {학번, 동아리})
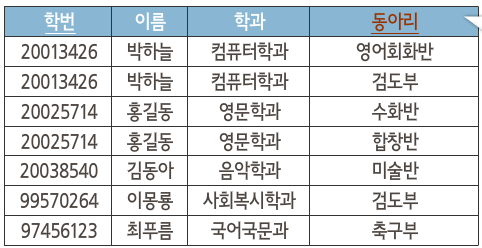
- 그러나 학번, 이름, 학과가 중복된 데이터 발생 -> 2개의 새 릴레이션(제 1 정규형 만듬)
- 학생 3 릴레이션(1NF) : 학번 -> (이름, 학과)
- 학생 4 릴레이션(1NF) : {학번, 동아리}


(2) 제 2정규형
- 제1 정규형은 기본키에 부분적 함수적 종속으로 갱신 이상 발생
-> 릴레이션을 분해하여 부분적 함수적 종속 제거하여 제 2정규형 만듬
수강지도 릴레이션 분해
- 수강지도(학번, 교과목번호, 지도교수, 학과, 성적)
- 기본키 : {학번, 교과목번호}
- 함수적 종속
학번 -> (지도교수, 학과)
{학번, 교과목번호} -> 성적
지도교수 -> 학과

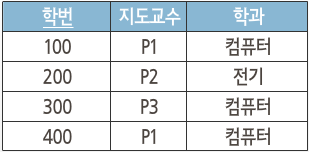
수강 릴레이션 2NF, 지도 릴레이션 2NF
- 학번 -> (지도교수, 학과)로 부분적 함수적 종속 발생
=> 수강 릴레이션과 지도 릴레이션으로 분해
지도(학번, 지도교수, 학과)
수강(학번, 교과목 번호, 성적)

(2) 제 3 정규형
- 제 2정규형은 이행적 함수적 종속관계가 존재시 갱신 이상 발생
-> 이행적함수적 종속 제거하여 제3정규형 만듬
지도 릴레이션 2NF
- 지도(학번, 지도교수, 학과)
- 기본키 : 학번
학번 ->(지도교수, 학과)
지도교수 -> 학과
=> 학과는 학번에 이행적 종속관계

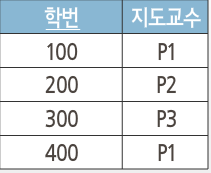
지도 릴레이션 분해 3NF
- 지도릴레이션을 학생지도와 교수소속 3NF 릴레이션으로 분해
학생지도(학번, 지도교수)
교수소속(지도교수, 학과)

보이스 코드 정규형 BCNF
- 제3 정규형은 후보키가 아닌 결정자가 존재시 갱신 이상 발생
-> 모든 결정자가 후보키가되는 BCNF 만듬
수강과목 3NF 릴레이션
- 수강과목 : (학번, 교과목, 교수)
- 기본키 : {학번, 교과목}
- 후보키 : {학번, 교과목}, {학번, 교수}
{학번, 교과목} -> 교수
교수 -> 교과목
-> 교수 속성이 후보키가 아닌데도 결정자 역활 수행

수강과목 3NF 릴레이션 분해
- 교수과목(교수, 교과목) BCNF 릴레이션
- 수강교수(학번, 교수(FK)) BCNF 릴레이션


역정규화 denormalization
- 성능 개선을위해 데이터 중복과 갱신 이상이 생기더라도 낮은 정규형으로 되돌아감
'컴퓨터과학 > SW, DB' 카테고리의 다른 글
| 소프트웨어 공학 활용 - 2 소프트웨어 개발 라이프사이클 (0) | 2020.05.18 |
|---|---|
| 소프트웨어 공학 활용 - 1 소프트웨어 공학 개요 (0) | 2020.05.18 |
| 데이터베이스 6 - 논리적 설계 (0) | 2020.05.17 |
| 데이터베이스 5 - 개념적 설계 (0) | 2020.05.17 |
| 데이터베이스 4 - 관계형 데이터베이스 구축과 요구사항 분석 (0) | 2020.05.17 |